

~15 interruptions per day. Each one, a repair on hold. Every unanswered WhatsApp, a customer walking to the competition. I built an AI agent that handles both — ~90% of interactions, 24/7, for less than €200/month.
Not a chatbot with canned responses. An agent that checks real prices, verifies stock, books appointments, and knows when to loop in a human with full context. That's what Jacobo became. In this article I share the complete architecture and the production workflows so you can replicate it.
The Problem#
With 30,000+ repairs completed and multiple support channels (phone, WhatsApp, web), the bottleneck was clear:
80% of inquiries were repetitive: prices, appointments, repair status
Every inquiry pulled the technician away from active repairs
Response times swung wildly depending on the day's workload
Data lived in three places: Airtable, the calendar, and inventory
Availability stopped at store closing time
Hiring part-time support didn't pencil out
Customers reached out via WhatsApp and landline. The solution had to cover both with shared logic, not duplicate the work

The constraints were fixed: Airtable was the brain (the Business OS had been the SSOT for years), I needed real tool calling against live data, and the agent had to cover voice + chat from the same backend. The only open question was which orchestration layer to use:
Tidio / Intercom
Generalist chatbots with decision trees. Can't check stock in real time or calculate dynamic pricing against Airtable. For a repair business, they're little more than an interactive FAQ.
ManyChat (WhatsApp)
Good for marketing flows, but no tool calling capability against an existing ERP. Can't verify stock, create work orders, or do context-rich handoff.
Vertical solution (RepairDesk chat)
No repair SaaS offered a conversational agent with natural language and tool calling against real-time data. The ones with chat were essentially forms in disguise.
n8n was the natural fit: workflow orchestration with webhooks, native LLM agent support with tool calling, and the ability to deploy each sub-agent as an independent, testable workflow. All wired into the Business OS already running in Airtable.
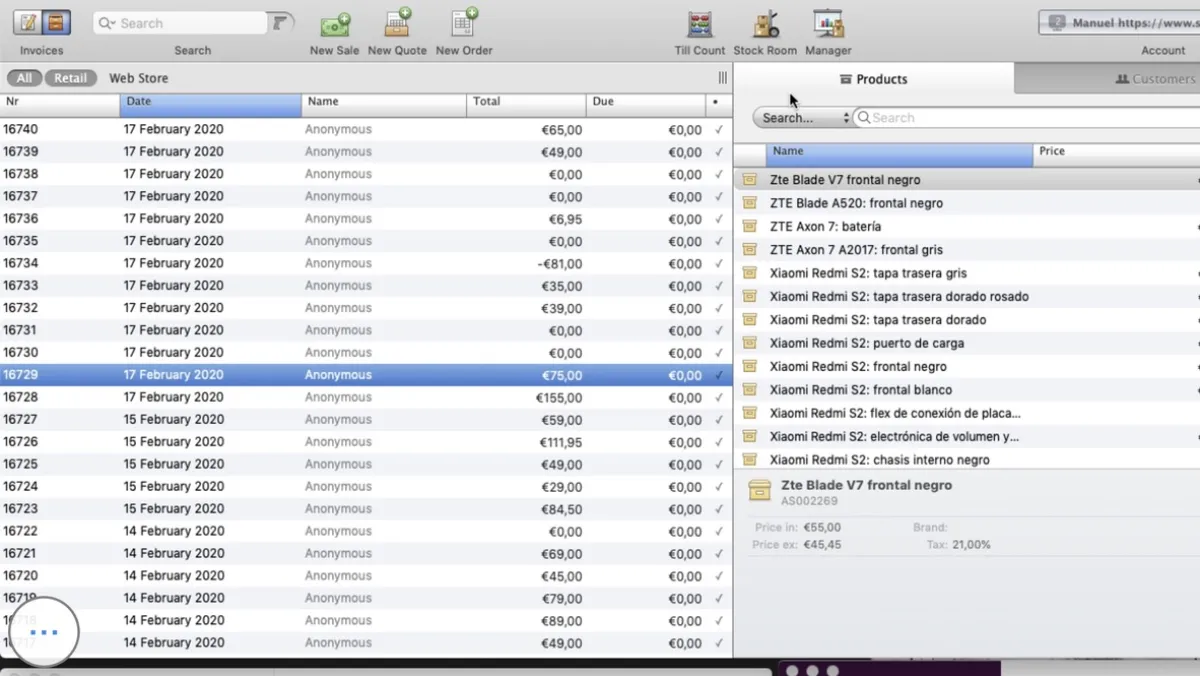
This POS was the first problem I solved
Before building Jacobo, I replaced this legacy system with a custom ERP on Airtable. That database is what Jacobo queries today.
The Architecture#
Jacobo isn't a chatbot with a long prompt. It's a system of specialized sub-agents, each deployed as an independent webhook in n8n, orchestrated via tool calling from a central router. Every workflow in this article is importable directly into n8n — grab them at the end.
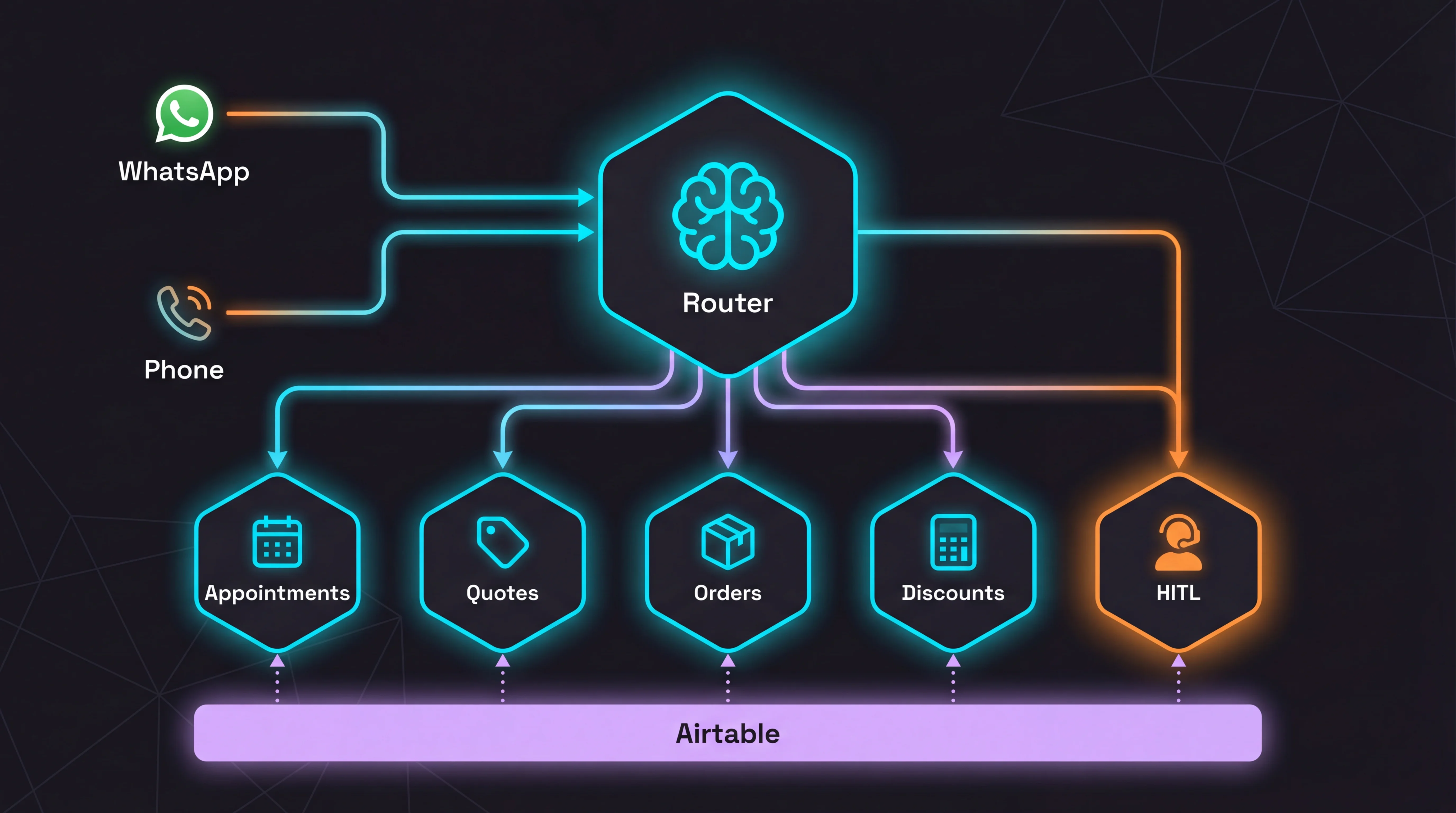
Stack
Jacobo runs on 8 services, end-to-end from first contact to human handoff. Every one is load-bearing — swap any of them and you're rearchitecting.
WATI
WhatsApp Business API — primary inbound channel
Aircall
Cloud PBX — Jacobo as a teammate on the phone system
n8n
Workflow orchestration and sub-agents (7 workflows, ~80 nodes)
OpenRouter
Model-agnostic LLM gateway (MiniMax M2.5 + GPT-4.1)
ElevenLabs
Conversational voice agent (eleven_flash_v2_5, temp 0.0)
Airtable
CRM, inventory, customer history (source of truth)
YouCanBookMe
Appointment scheduling and availability
Slack
HITL escalation channel (#chat)
Why sub-agents instead of a monolithic prompt?
Testability
Each sub-agent has its own webhook. I can test it in isolation with an HTTP call, without spinning up the entire system.
Independent evolution
Changing discount logic can't break appointments. I can iterate on one domain without risking another.
Cost efficiency
Not every sub-agent needs the same model. Appointments runs on MiniMax M2.5 (fast and cheap for parsing time preferences). Quotes runs on GPT-4.1 mini (precision for structured output). Right-sized models per task.
Platform-agnostic
Sub-agents are just webhooks. They don't know whether n8n (WhatsApp) or ElevenLabs (voice) is calling them. Any orchestrator can reuse them without duplicating logic.
4 Agents & 3 Tools to Rule Them All
4 agents with their own LLM make decisions. 3 tools with no LLM execute pure business logic. All connected via webhooks.
Main Router (n8n)
The brain of the WhatsApp channel. Classifies intent, picks the right sub-agent, and keeps track of the conversation with a 20-message memory window.
GPT-4.1 via OpenRouter · 37 nodes
LangChain Agent pattern with 7 tools as HTTP endpoints
Think tool for internal reasoning before complex chains
Pseudo-streaming: splits responses into sentences, sends them one by one via WhatsApp
Voice Router (ElevenLabs)
The brain of the voice channel. Receives calls via Aircall → Twilio → ElevenLabs Conversational AI, with its own system prompt optimized for spoken conversation.
ElevenLabs Conversational AI · GPT-4o
Same sub-agents as the Main Router, connected as HTTP tools
Native RAG out-of-the-box: knowledge base with repair catalog, pricing and FAQs
Voice-optimized latency: short, direct responses
Business hours detection to transfer to a human outside hours
Appointments Sub-agent
Turns "tomorrow morning" into a confirmed booking. Parses natural language time preferences, checks YouCanBookMe for available slots, and sends a WhatsApp confirmation template.
MiniMax M2.5 via OpenRouter · 18 nodes
15 temporal parsing rules: from "after lunch" to "any day except Monday"
The most sophisticated sub-agent in the system
Quotes Sub-agent
Every price inquiry flows through here. Looks up the exact model and repair in Airtable, returns real pricing with stock status, and decides the next step.
GPT-4.1 mini via OpenRouter · 11 nodes
Stock available? → offer appointment
Out of stock? → offer order
No listing? → link to the quote form
Tools (no LLM)
Orders
Creates repair orders in Airtable when a part is out of stock.
3 nodes: webhook → create record → respond
Simple by design: all validation happened upstream in Quotes
Discount Calculator
Pure business logic, no LLM. Calculates combo discounts when customers bundle multiple repairs.
3 nodes · no LLM
Battery + screen + back glass = automatic multi-repair pricing
Discount rules live here, not scattered across prompts
HITL Handoff
The escape valve. Escalates to a human via Slack with a deep-link straight into the WATI conversation.
5 nodes · posts to #chat
Includes conversation summary, detected intent, and customer history
Human gets full context before opening the chat
Conversational Memory
Jacobo holds no state between messages. On every new message, it rebuilds context by reading the actual conversation history from WATI:
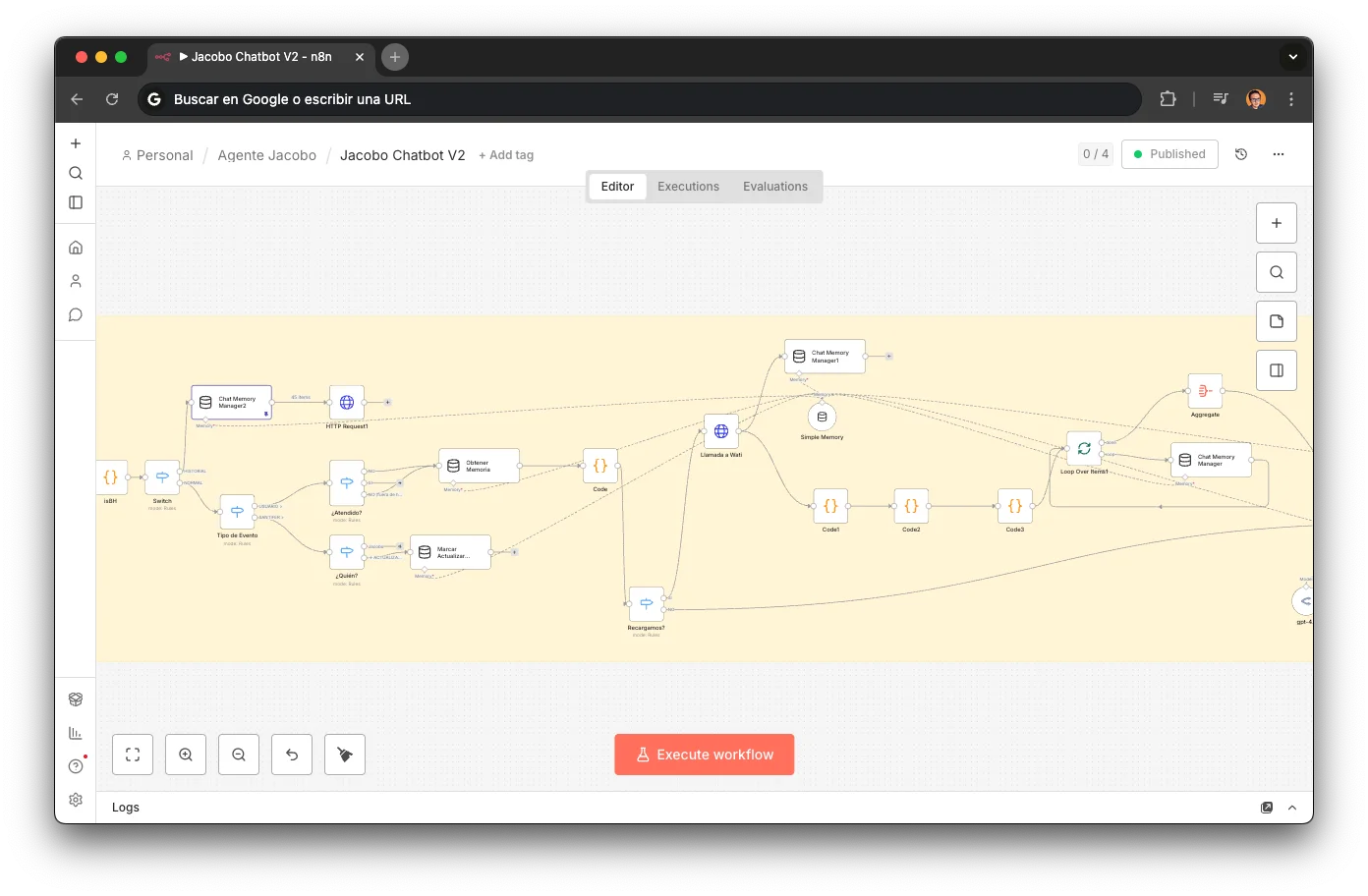
Already served?
A switch checks whether an active session exists for this phone number. If not, it triggers a memory reload.
WATI fetch
HTTP call to getMessages/{waId} with pageSize=80. Retrieves the last 80 messages from the full conversation: customer messages, Jacobo responses, templates, broadcasts, and human operator messages.
3-phase parsing
Three code nodes transform raw WATI events into {human, ai} pairs compatible with LangChain. Filters out broadcasts, confirmation templates, and system events. A __reloadFlag__ allows manual memory resets.
Buffer Window
The last 20 messages are loaded into the LangChain BufferWindow, keyed by phone number. The agent "remembers" past conversations: if you confirmed an appointment yesterday, Jacobo knows today.
This is what lets Jacobo pick up interrupted conversations, recognize returning customers, and know when a human stepped in earlier.
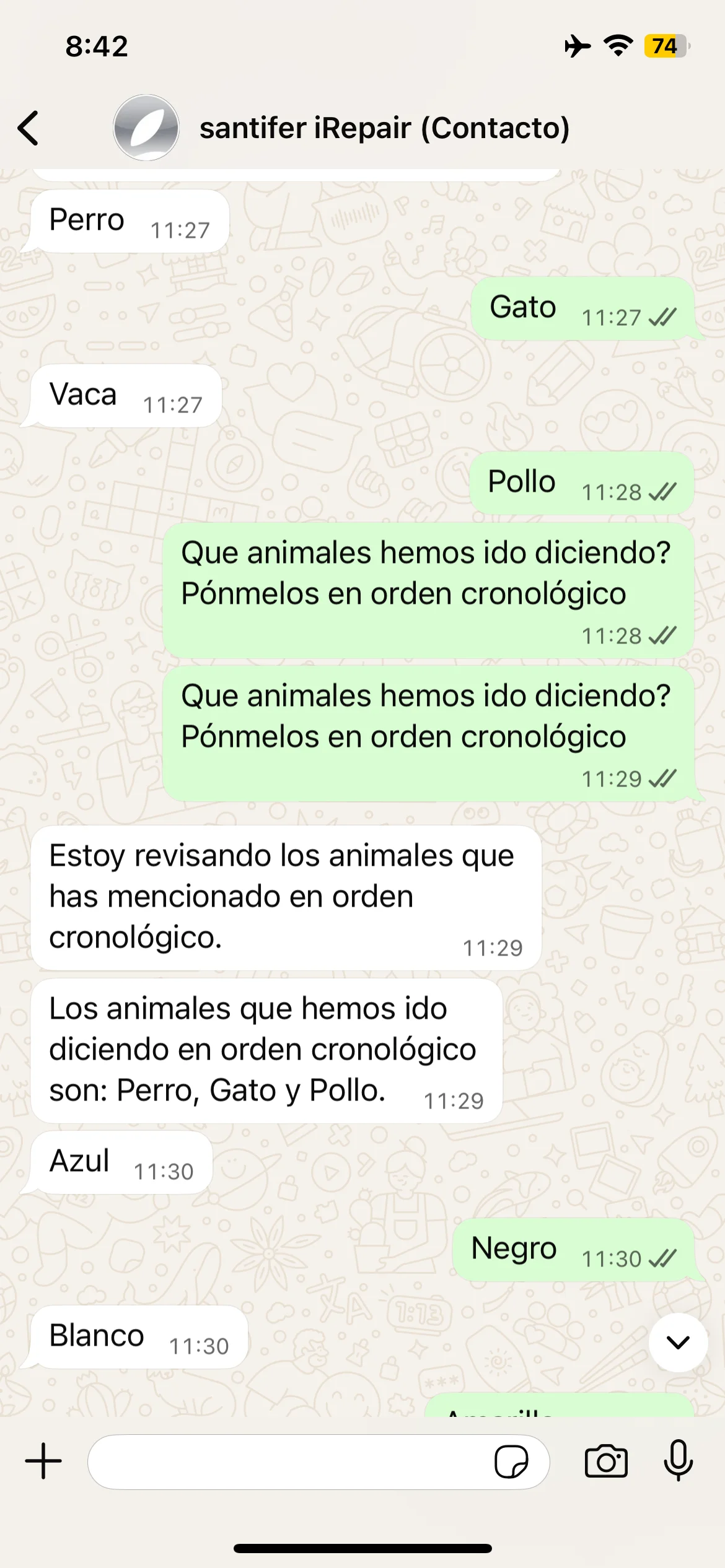
Memory test: Dog, Cat, Elephant — Jacobo recalls all three
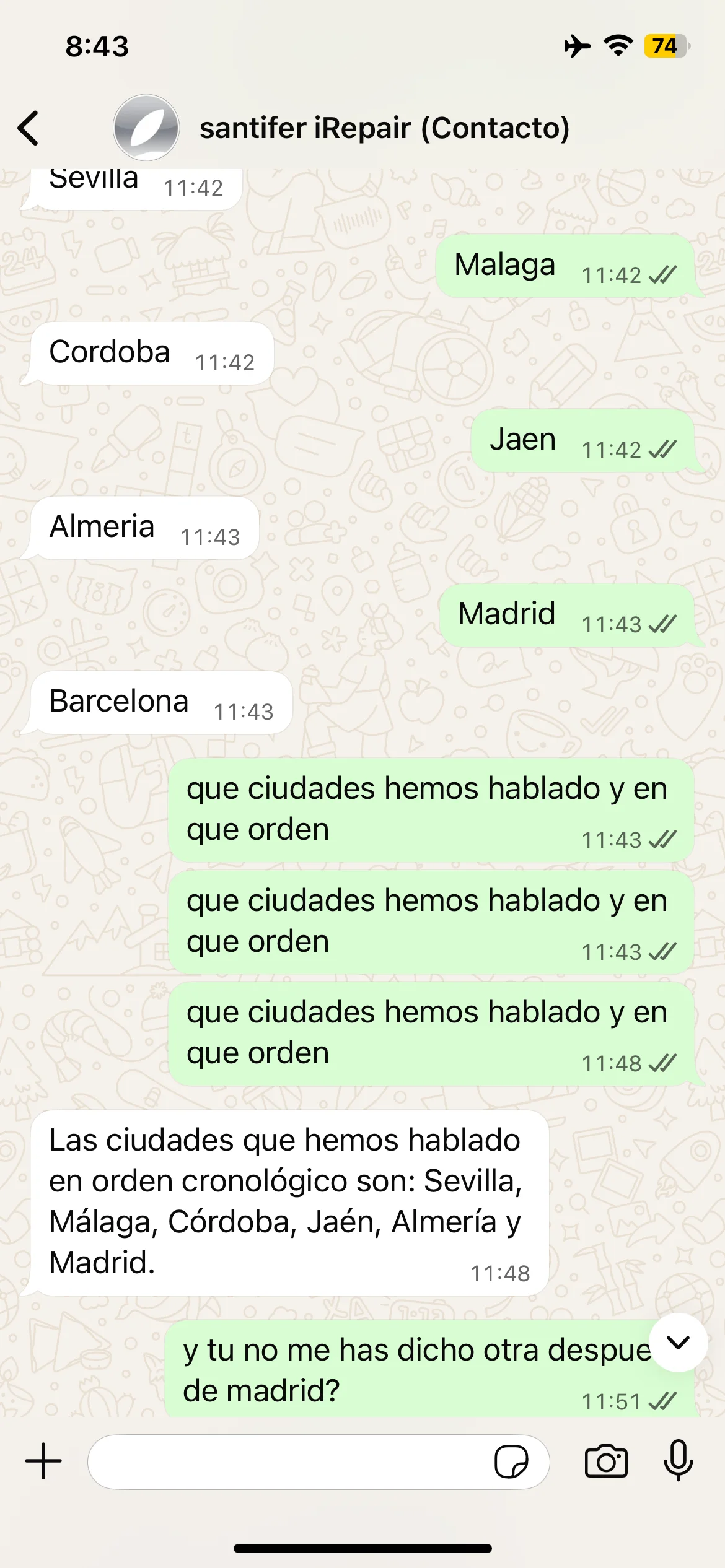
Cities test: Seville, Madrid, Barcelona — correct recall
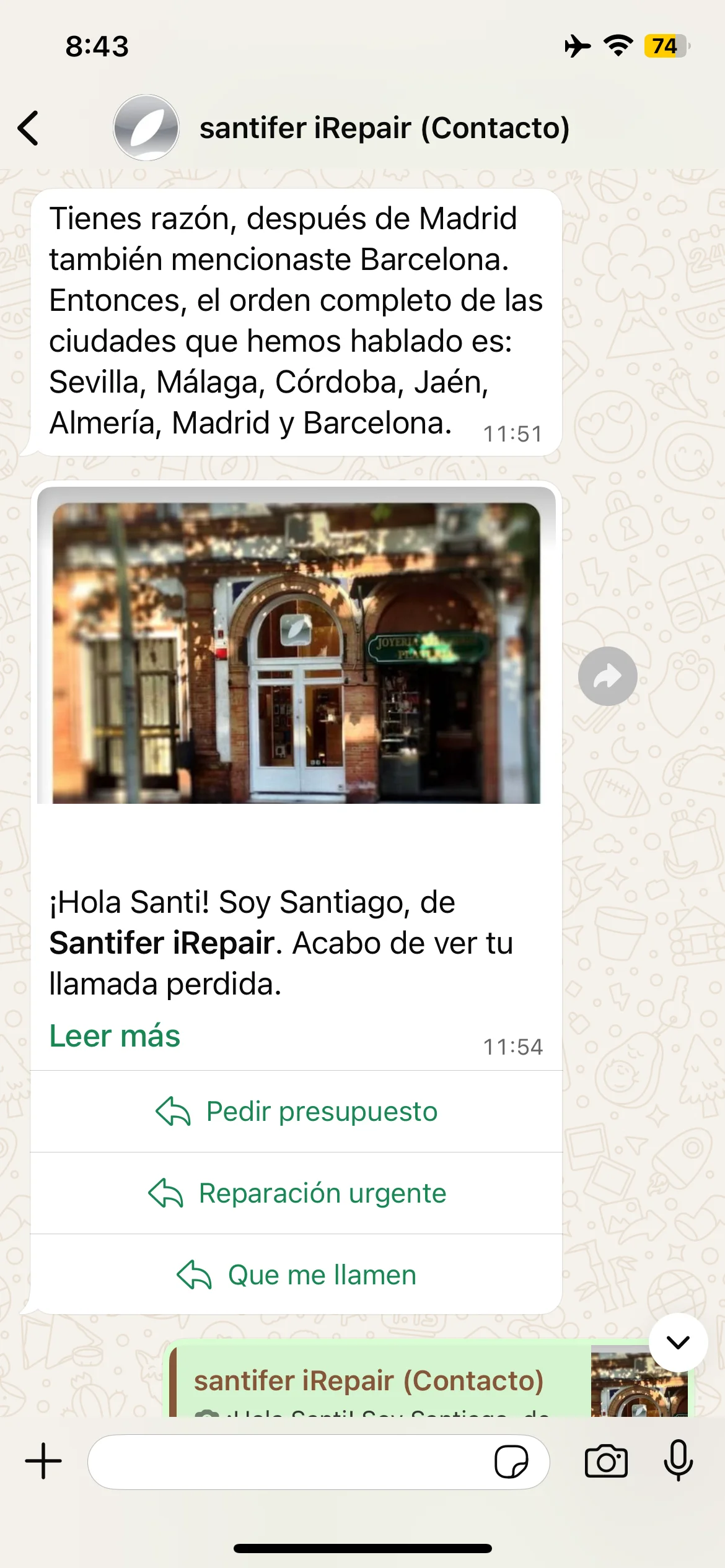
Self-correction: "You're right, I said Seville, not Valencia" — Jacobo self-corrects
Episodic memory tests: animals, cities and self-correction when Jacobo forgets Barcelona
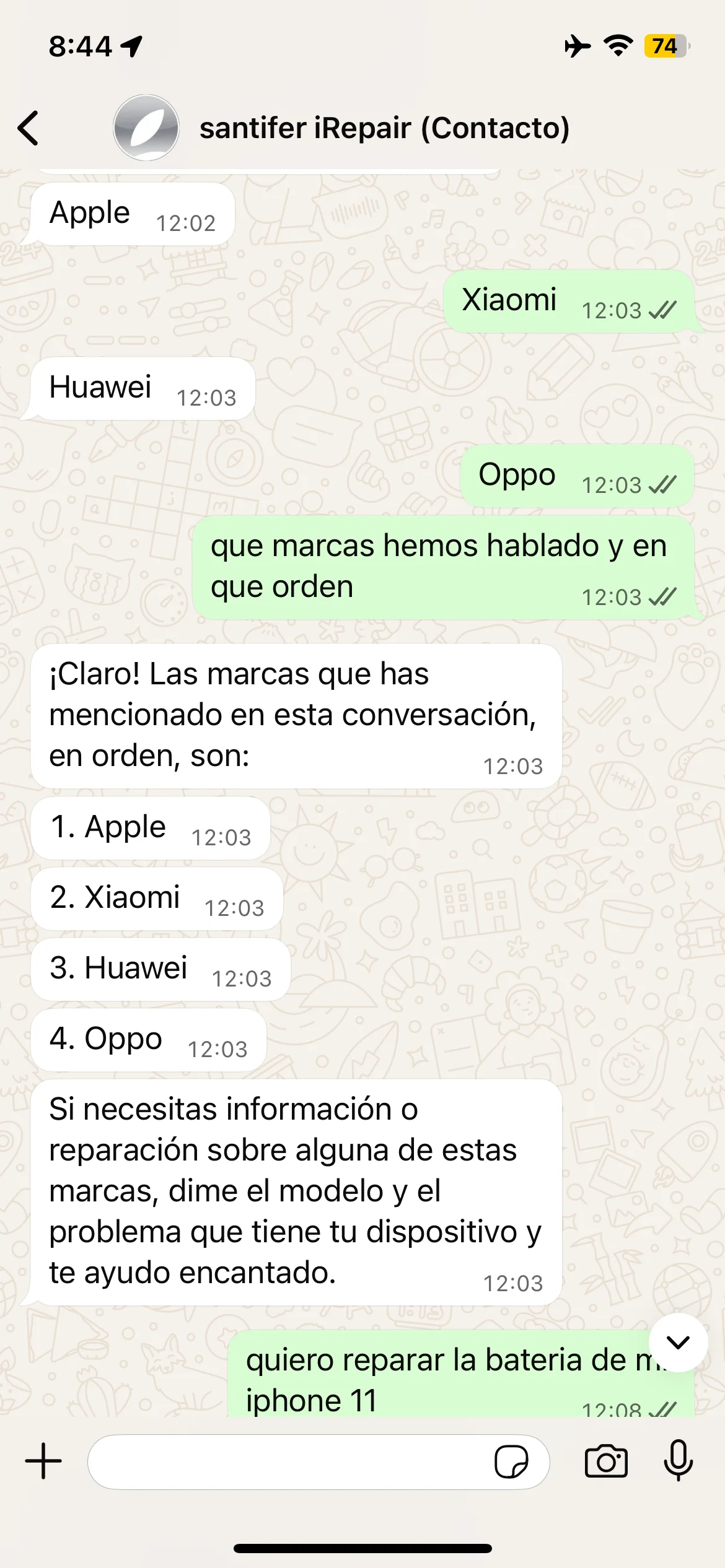
Brand test: Apple, Samsung, Huawei — correct recall

Customer lost the conversation — Jacobo recalls the full appointment

Re-negotiation: Jacobo recalls time preference → no slot at 12 → suggests alternatives
Memory in action: brands recalled in order, appointment recovered from system state and re-negotiation when no availability
Production debug tools
Two hidden commands to debug memory in production without touching n8n. "Borrar memoria" reset the customer's buffer, useful when a conversation got corrupted or the LLM entered a loop. "HISTORIAL" dumped the raw buffer JSON — and that's what taught us to sanitize responses: the LLM returned the full JSON to the customer if left unfiltered.
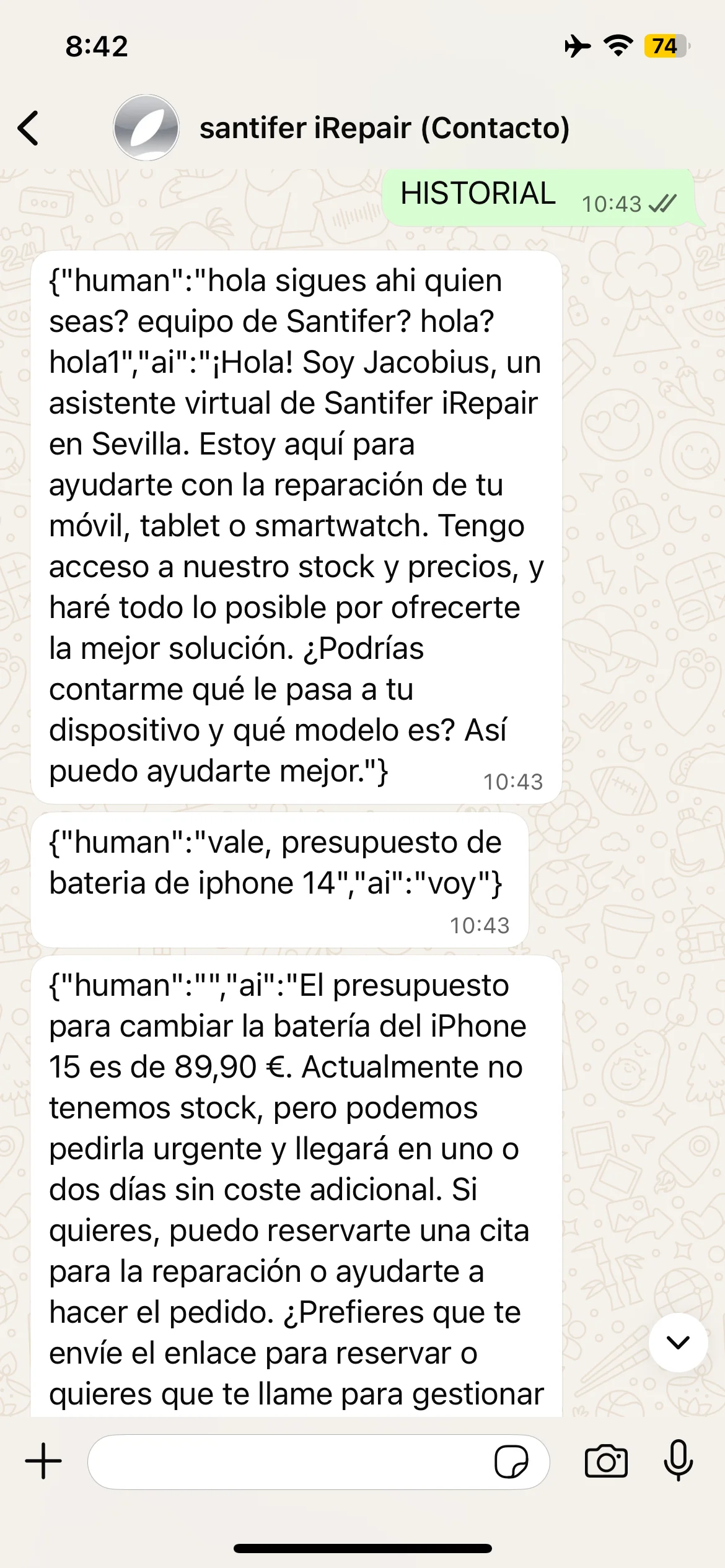
HISTORIAL command: raw JSON from memory buffer exposed in chat

BORRAR MEMORIA command: full conversational buffer reset
Production debug commands: HISTORIAL dumped raw JSON from the buffer and BORRAR MEMORIA reset the conversation
Pseudo-Streaming on WhatsApp
WhatsApp doesn't support streaming. A wall of text feels like a bot; sequential messages feel like someone typing. The router splits each response on line breaks and sends each chunk with a 1-second delay via the WATI API. Result: the "typing..." experience with zero streaming infrastructure.
The Two Channels
Jacobo runs on two channels simultaneously. The key: both share the same sub-agent webhooks. Business logic written once, served everywhere.
Dual-Orchestrator Architecture
This is the key pattern: n8n orchestrates WhatsApp, ElevenLabs orchestrates voice, but both hit the same sub-agent webhooks. A real microservices pattern applied to AI agents. The sub-agents don't know who's calling them. They don't need to.
WhatsApp (highest volume)
WATI as WhatsApp Business API + n8n as orchestrator. 70% of queries flow through here.
n8n router with LangChain Agent pattern: 37 nodes, 7 tools as HTTP endpoints, GPT-4.1 via OpenRouter
Meta-approved WhatsApp templates for appointment confirmations, order tracking and notifications
Pseudo-streaming: splits the response into sentences and sends them one by one. The customer sees Jacobo "typing" like a real person
Memory: 20 messages per session, keyed by phone number. Rebuilds context by reading full conversation history from WATI
Event Routing: 3 switches filter noise (system events, broadcasts, human operator messages) before reaching the agent
Transparent Human Takeover: when a human takes control via WATI, Jacobo detects the handoff and stays quiet
Landline (voice)
Aircall as Cloud PBX + Twilio as phone bridge + ElevenLabs as conversational voice agent. Jacobo sits on the Aircall phone system as a literal "teammate" with its own routing rules.
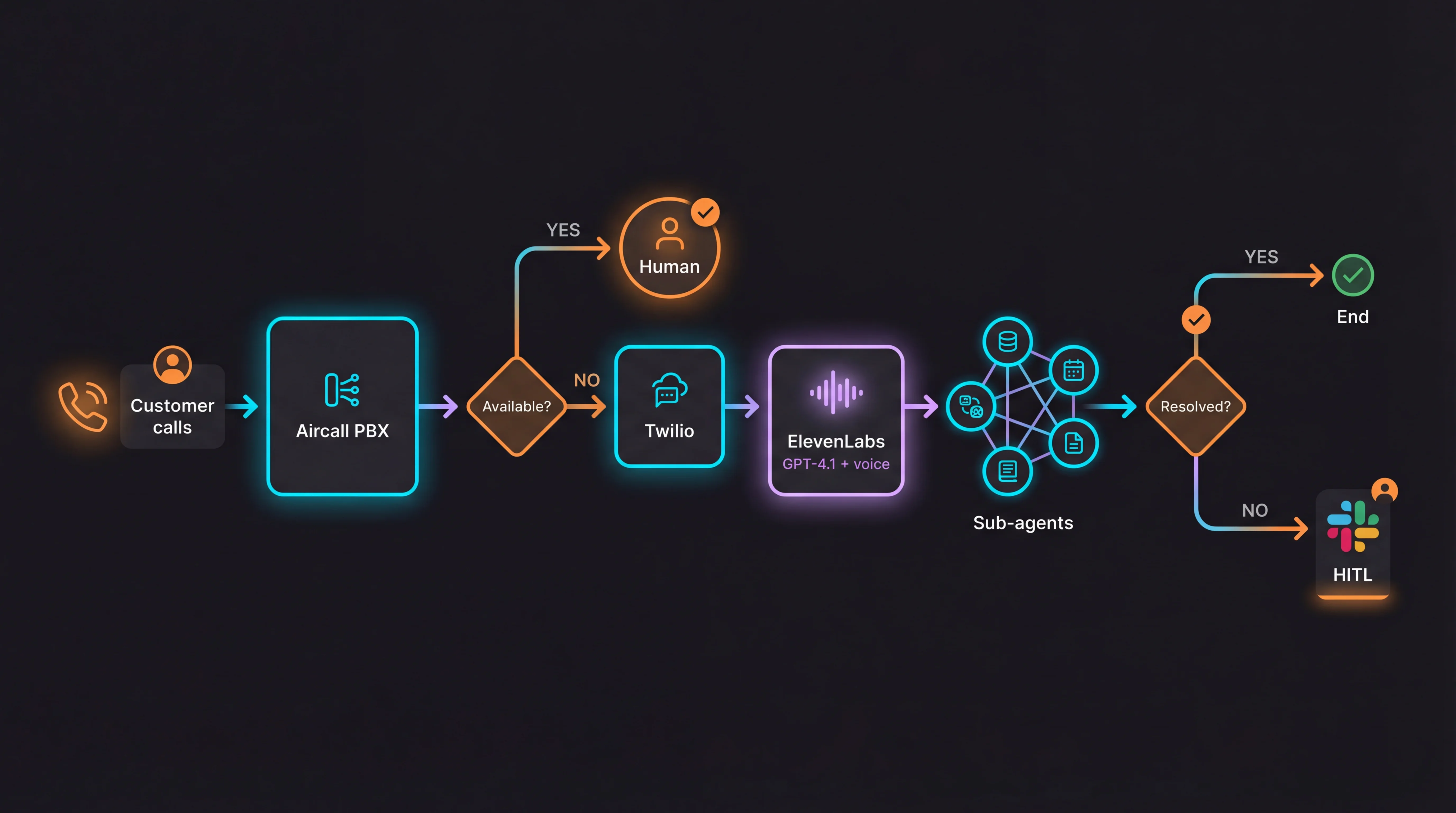
Aircall → Twilio → ElevenLabs integration: calls came through the business Aircall PBX. When no one answered or after hours, Aircall redirected to a dedicated Twilio number connected to the ElevenLabs agent. For the customer, it was transparent: they dialed the store landline and talked to Jacobo
The customer called a landline and talked to Jacobo like any other employee. NOT a web widget or an IVR with menus. It was a real phone call with natural voice
High-quality ASR (provider: ElevenLabs, PCM 16kHz) + 7s turn_timeout + 20s silence_end_call to handle natural conversational pauses
LLM: GPT-4.1 (temp 0.0) for maximum precision in voice tool calling. Optimized latency (optimize_streaming_latency: 4)
Voice model: eleven_flash_v2_5, speed 1.2x, stability 0.6, similarity 0.8. Conversations up to 5 minutes (300s)
Knowledge base with 3 sources (Google Maps, Santifer iRepair website, business summary) leveraging ElevenLabs' native RAG (e5_mistral_7b_instruct). Didn't build custom RAG: the platform offered it and it was high impact with zero effort. Pure RICE prioritization. n8n didn't need it: the WhatsApp agent already accessed business context via direct tool calling to Airtable
5 shared webhook tools with n8n: presupuestoModelo, subagenteCitas, Calculadora, contactarAgenteHumano, and enviarMensajeWati. 20s timeout per tool, immediate execution
enviarMensajeWati was the cross-channel magic: while talking on the phone, Jacobo sent links and quotes via WhatsApp in parallel using the caller_id as a dynamic variable. Customers loved getting the info on their phone while still on the call
Production incident: the Coca-Cola
A customer was discussing a phone repair. Mid-conversation, he turned to order a Coca-Cola from a waiter. Jacobo heard it — and told him we don't serve Coca-Colas.
Diagnosis: three signals the system ignored
Volume
Dropped ~40% — he moved away from the phone
Spectral tilt
Shifted — off-axis voice loses high frequencies
Semantic relevance
"Coca-Cola" had zero relation to phone repairs
Basic VAD isn't enough. You need addressee detection: acoustic proximity + prosodic analysis + semantic gating working together.
Missed Call Recovery
If the customer hung up or no one answered, Aircall fired a webhook to Make.com which triggered a WhatsApp template via WATI with action buttons. A huge chunk of leads came through here: people who called, didn't wait, and Jacobo caught them. Since it pulled context from WATI, when they replied it already knew they'd tried to call.
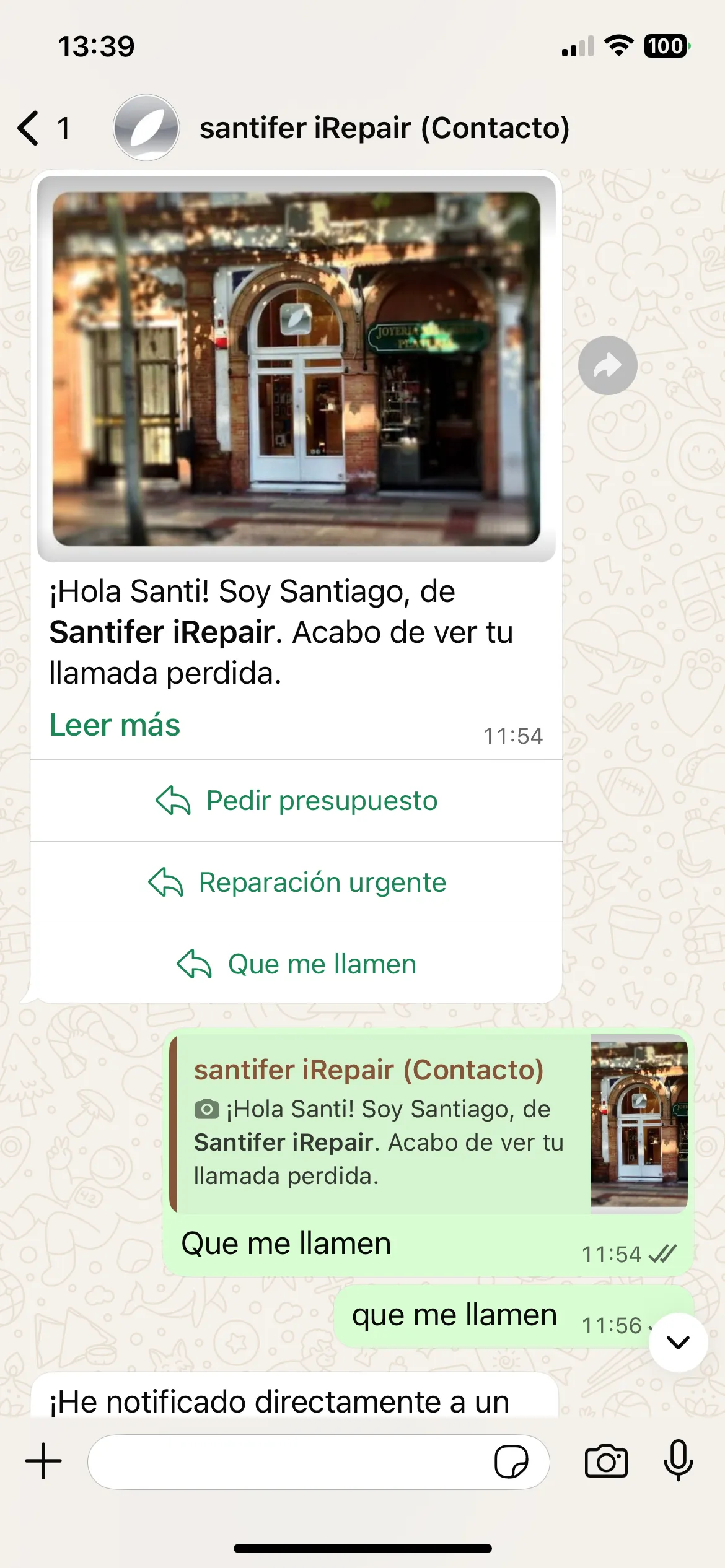
WhatsApp template after missed call: buttons Get a quote, Book appointment
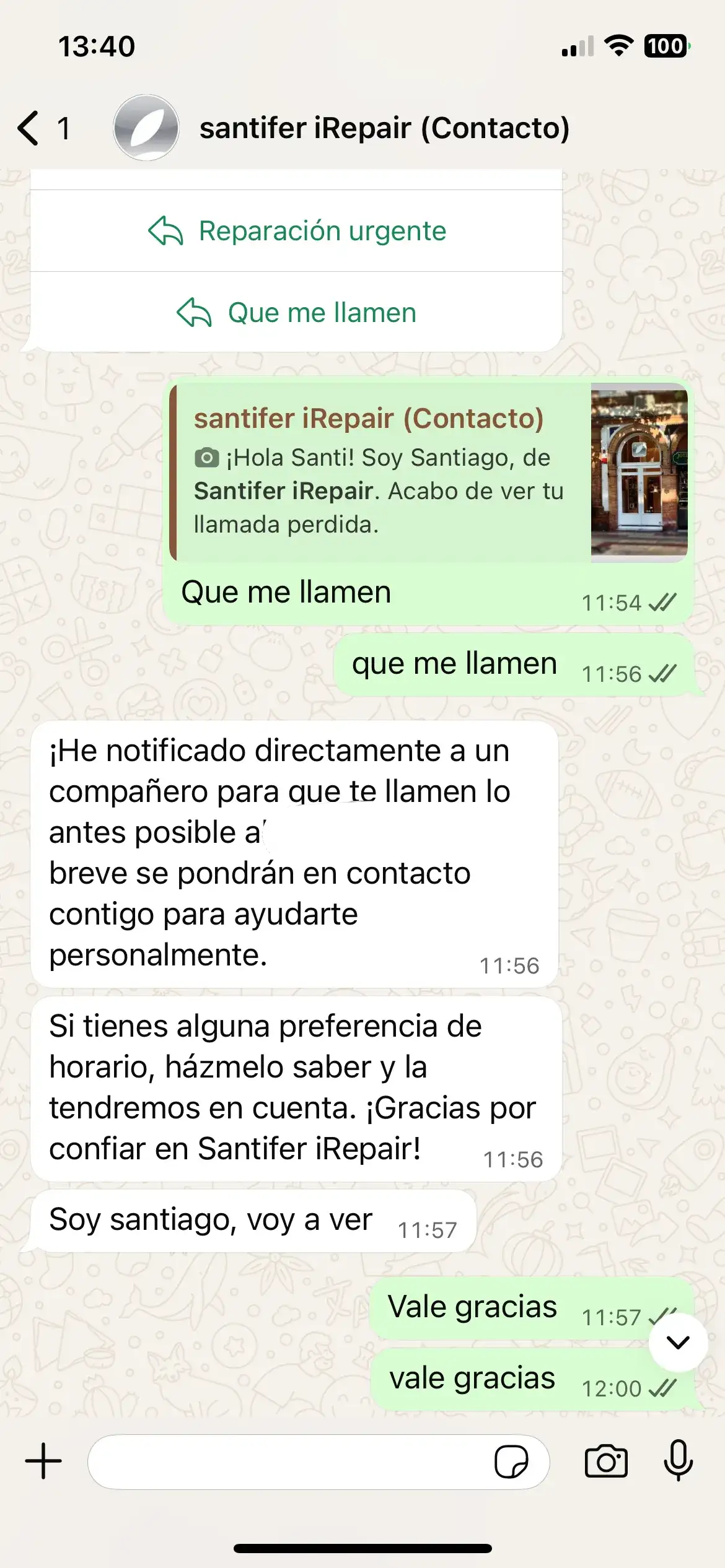
Customer picks "Call me back" → Jacobo escalates to HITL and confirms notification
Aircall → Make.com → WhatsApp template with buttons → Jacobo picks up the conversation with full context
Unified UX: One Voice
Every PBX audio — welcome greeting, IVR menu, voicemail — was generated with ElevenLabs using Jacobo's same voice. When the customer presses 3 or no one can answer and the live agent picks up, the voice is identical. No break. And if no one picks up and Jacobo texts them on WhatsApp after the missed call, the identity stays the same. A unified experience from start to finish, regardless of channel.
"Press 3 to talk to me, Jacobo." That's the PBX introducing the AI agent in first person. The same voice that then picks up. An agent that announces itself.
Listen to the actual PBX. Jacobo's same voice across welcome, IVR menu, and live agent:
"A continuación, atenderemos tu llamada. Gracias por llamar a Santifer iRepair. Para asegurar la calidad del servicio, tu llamada puede ser grabada."
"We'll be right with you. Thank you for calling Santifer iRepair. For quality assurance, your call may be recorded."
"Marca 1 para solicitar una nueva reparación. Marca 2 para consultar el estado de tu reparación. Marca 3 para hablar conmigo, Jacobo. Tu asistente virtual 24/7 en Santifer iRepair. Obtendrás presupuesto y cita al instante."
"Press 1 for a new repair. Press 2 to check your repair status. Press 3 to talk to me, Jacobo. Your 24/7 virtual assistant at Santifer iRepair. Get a quote and book an appointment instantly."
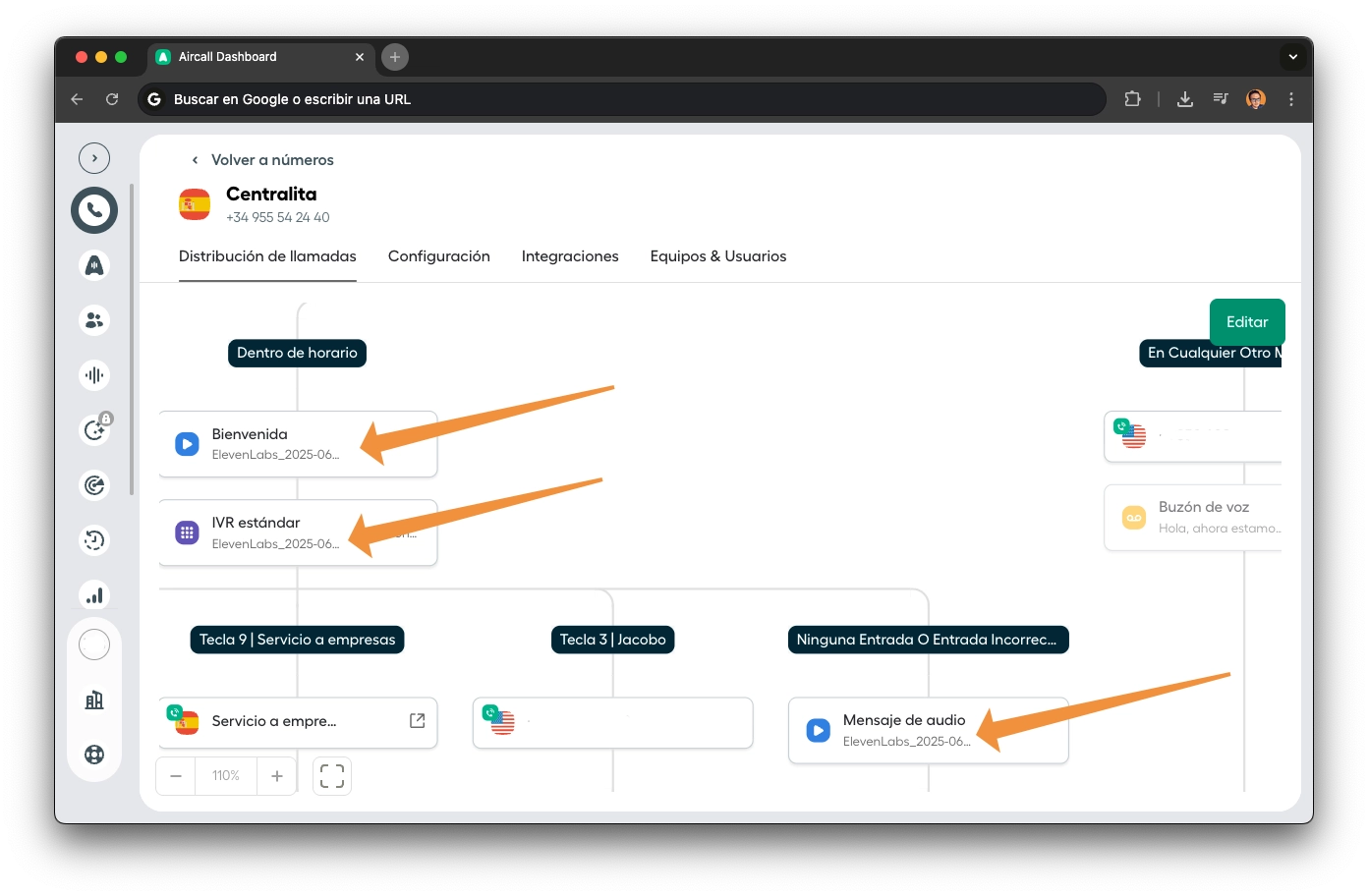
Pre-filtering: Should Jacobo Respond?
Before a message reaches the AI Agent, three switches filter noise and decide who should respond:

Event Type
Filters only real messages. Ignores system events, delivery confirmations, status updates, and mass broadcasts. Without this, Jacobo would respond to its own confirmation messages.
Who sent it?
Detects whether the last speaker was the customer or a human operator. When a human takes control of the conversation via the WATI deep-link, their messages arrive as owner: true. Jacobo knows this and doesn't interrupt.
Already served?
Checks for an active session. If a customer replies to a conversation a human was handling, but the store has already closed, Jacobo enters with an empathetic tone: "We closed at noon, but I can help you until we reopen this afternoon." Real graceful degradation.
This 3-node filter is what makes human-agent coexistence work without conflicts. The human can take over anytime. When they're gone, Jacobo picks back up with full context.
End-to-End Flows#
Each flow walks the happy path from inquiry to resolution, with the sub-agents involved called out at each step.
Repair Appointment
Customer writes on WhatsApp: "Hi, how much does it cost to replace an iPhone 14 Pro screen?"
Router classifies intent as price inquiry → delegates to Quotes sub-agent
Quotes searches Airtable: model + repair type → returns real price (€189), part availability and estimated time (45-60 min)
Stock available → Jacobo responds with price and asks: "Want to book an appointment?"
Customer says "Yes, tomorrow morning" → Router delegates to Appointments sub-agent
Appointments parses the time preference, queries YouCanBookMe → offers slots: "10:00 and 11:30"
Customer confirms → appointment created in YouCanBookMe + work order generated in Airtable + parts auto-reserved from inventory
Confirmation sent via WhatsApp with summary: date, time, price, store address
Price Inquiry
Customer: "How much to replace a Samsung S23 battery?"
Router classifies intent → delegates to Quotes
GPT-4.1 searches Airtable: exact model + repair type
If in stock → responds with price, time, and offers to book an appointment
If NOT in stock → responds with price, indicates the part needs to be ordered, offers to place the order
If model doesn't exist in the database → Jacobo clearly says so instead of making up a price
Stock-aware routing: the CTA changes based on real availability in Airtable
Human Escalation (HITL)
Escalation triggers: detected frustration, out-of-domain query, warranty case, explicit request to speak with a person
Router activates HITL Handoff → sends notification to Slack (#chat)
The Slack message includes: conversation summary, detected intent, customer data from Airtable, escalation reason
Deep-link to WATI: the human clicks and jumps straight into the customer's WhatsApp conversation
The human doesn't start from scratch: they have full context. Average post-handoff resolution time: seconds, not minutes
Jacobo tells the customer: "I'm connecting you with a colleague who can help you better with this"
The Two Brains#
Jacobo has two independent routers sharing the same tools and sub-agents. One orchestrates WhatsApp, the other handles voice calls. Same business logic, two completely different interfaces.
WhatsApp Router (n8n)
The text brain: an n8n workflow with 37 nodes that classifies every message, decides which sub-agent to invoke, and orchestrates the response. Tool calling, prompt engineering, and all routing logic live here.
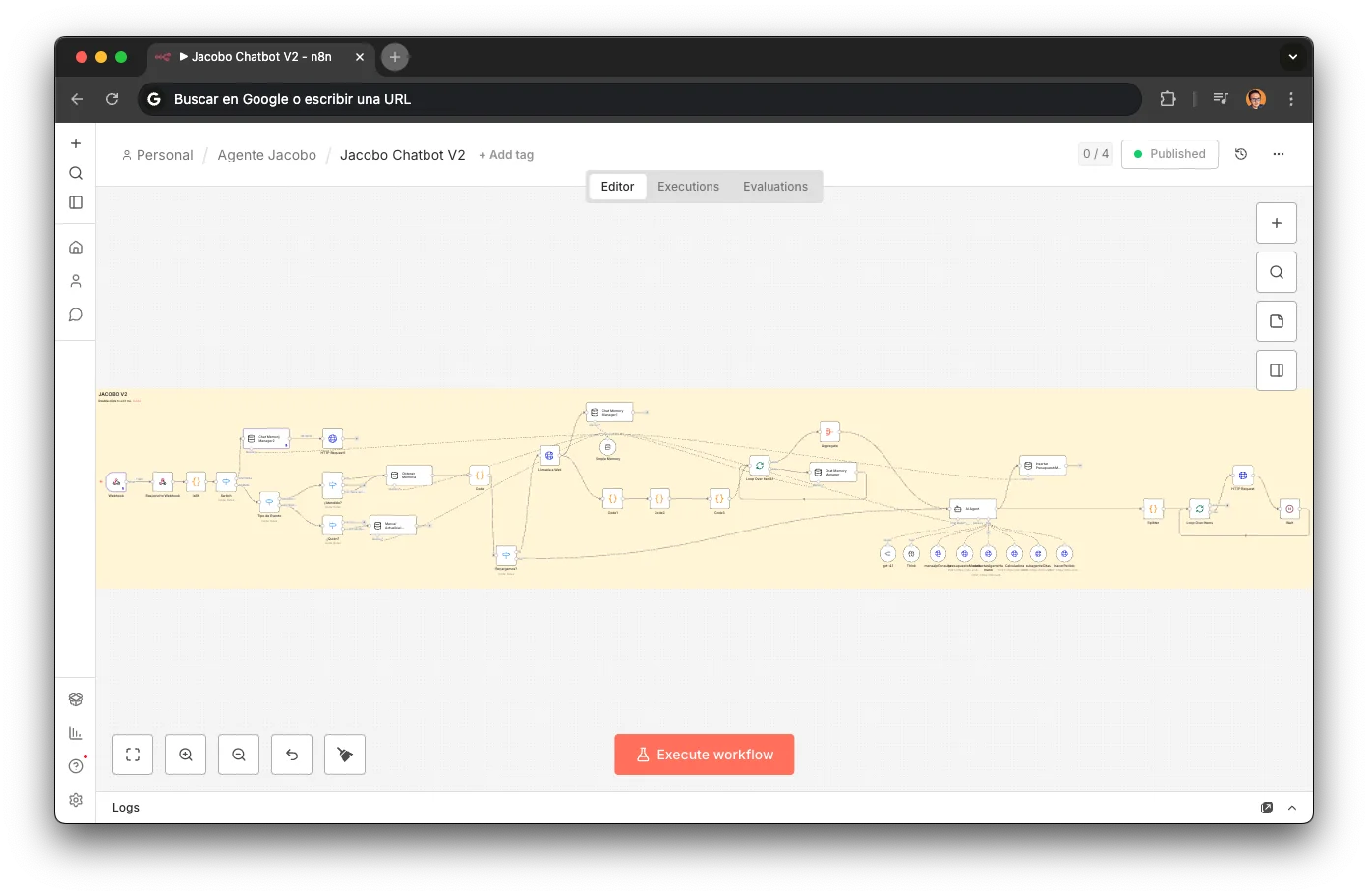
Voice Router (ElevenLabs)
The voice brain: a conversational agent on ElevenLabs powered by Gemini 2.5 Flash, knowledge bases with business documentation, and the same tools exposed as webhooks. The customer talks on the phone and Jacobo responds in real time, checking prices, availability and managing appointments — exactly the same as WhatsApp.

Tool Calling in Production
Jacobo doesn't make up answers from training data. Every response is grounded in real systems via 7 tools defined as HTTP endpoints:
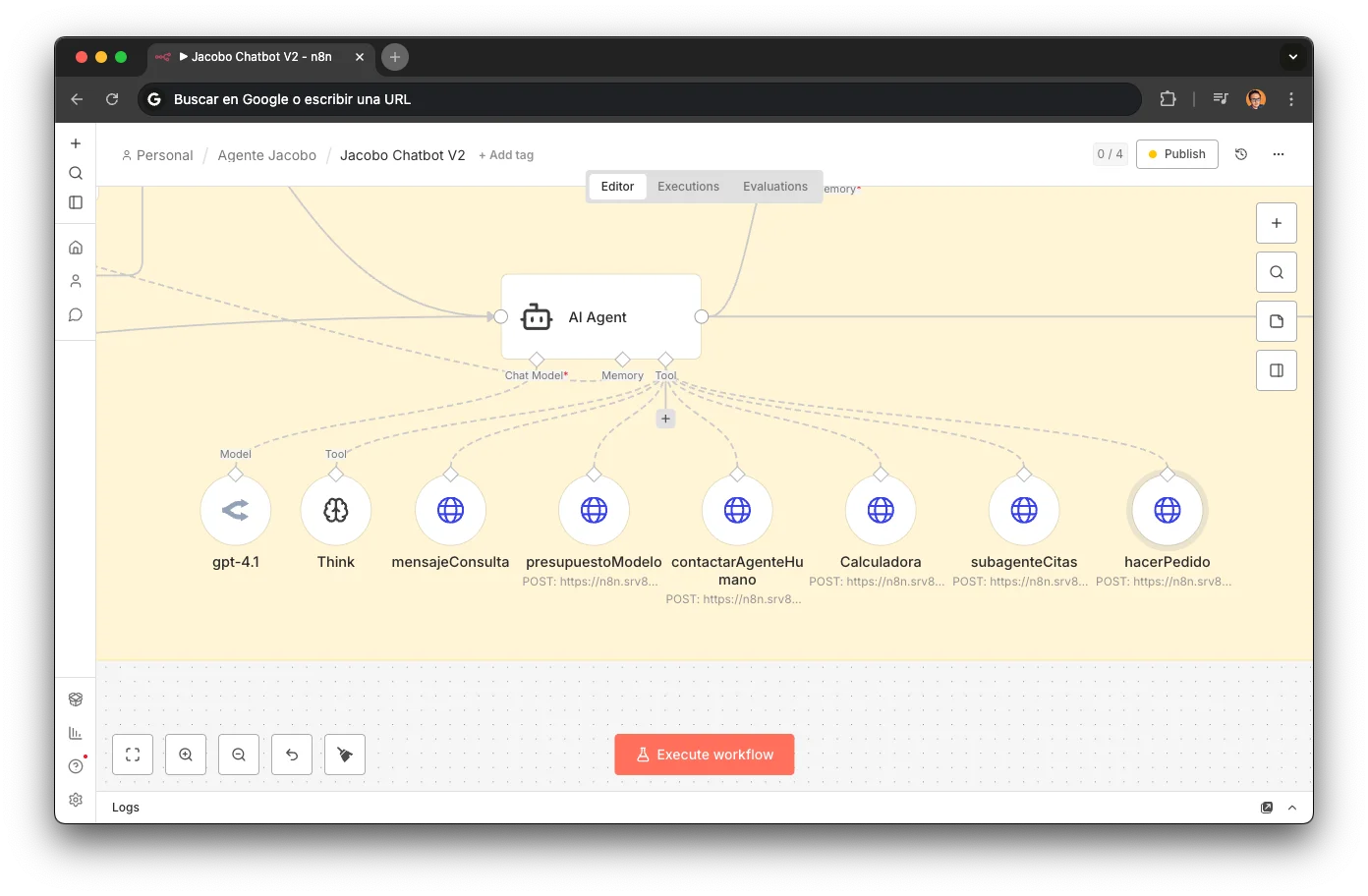
presupuestoModeloLooks up repair/accessory prices and stock in Airtable. LLM: GPT-4.1 for structured output precision.
subagenteCitasManages availability and bookings via YouCanBookMe. The LLM parses temporal preferences from natural language.
hacerPedidoCreates repair/purchase orders in Airtable. 3 nodes: webhook → create record → respond.
CalculadoraVolume discount: more repairs together = bigger discount. Pure business logic, no LLM.
contactarAgenteHumanoHITL escalation via Slack with escalation reason, deep-link to WATI, and full context. Works from both WhatsApp and phone calls.
enviarMensajeWatiSends information via WhatsApp in parallel. When the voice agent needed to send a link or quote, it did so via WhatsApp while still talking on the phone.
ThinkInternal reasoning meta-tool. The agent "thinks out loud" before multi-tool chains to reduce errors.
mensajeConsulta: UX while thinking
When Jacobo calls presupuestoModelo (1-3s latency), it fires mensajeConsulta first: an "I'm checking availability..." that lands before the sub-agent responds. Without it, customers saw 5 seconds of dead air and assumed the bot was broken. One UX detail, massive difference.

Jacobo responds as formal email: subject line, greeting, Huawei P20 Pro quote
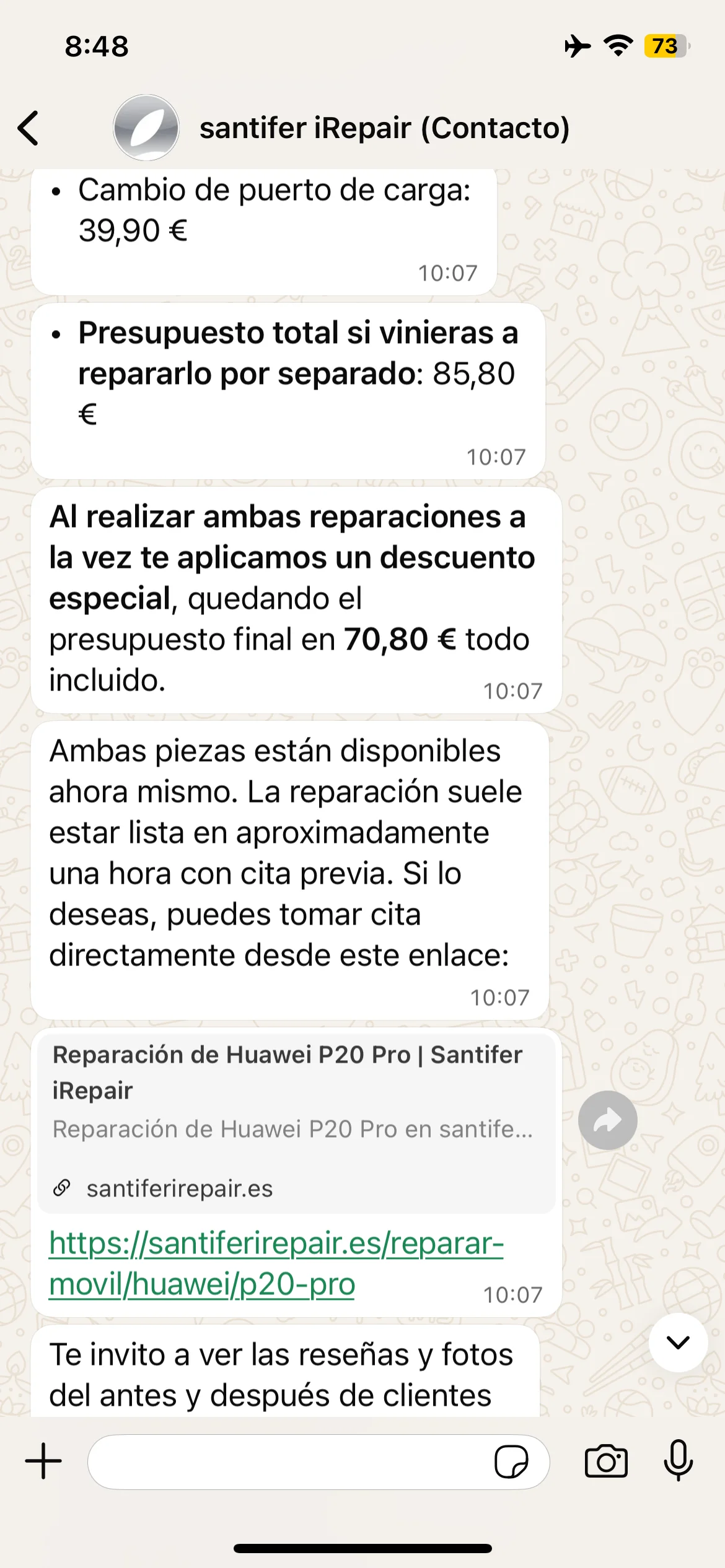
Email: battery + charging port = €85.80 → combo discount €70.80
Signature: "Best regards, Jacobo — Santifer iRepair — address + phone + email"
Adaptability: customer asks for email format and Jacobo responds with subject line, itemized quote, combo discount and corporate signature
The "Think" Tool
Before executing a tool chain (check price → verify stock → offer appointment), the agent invokes Think to plan the sequence. Explicit reasoning before action cuts errors in multi-tool chains significantly.
Stock-Aware Routing
presupuestoModelo's output determines what happens next. It's not a fixed flow: the CTA adapts to real-time availability.
→ Offers to book a repair appointment
→ Offers to place an order with supplier ETA
→ Clearly states it and offers human contact
Prompt Engineering in Production
No fine-tuning. For a repair shop agent, iterating on the prompt with hard rules is more pragmatic, cheaper, and faster than training a custom model. Every rule below has a production incident behind it.


Why hard rules in the prompt instead of fine-tuning?
Fine-tuning is expensive and slow to iterate. A prompt rule ships in seconds.
The domain changed constantly: prices, stock, hours, promotions. A fine-tuned model goes stale in days.
Rules are auditable. Anyone on the team can read the prompt and understand why Jacobo behaves a certain way.
90% of production errors got fixed by adding one line to the prompt. Not retraining a model.
Business hours detection
A JavaScript code node checked whether the store was open before each conversation. The result got injected as a dynamic variable into the prompt: when `isBH` was false, Jacobo shifted tone ("after hours I'll try to help you anyway") and stopped promising immediate human responses.
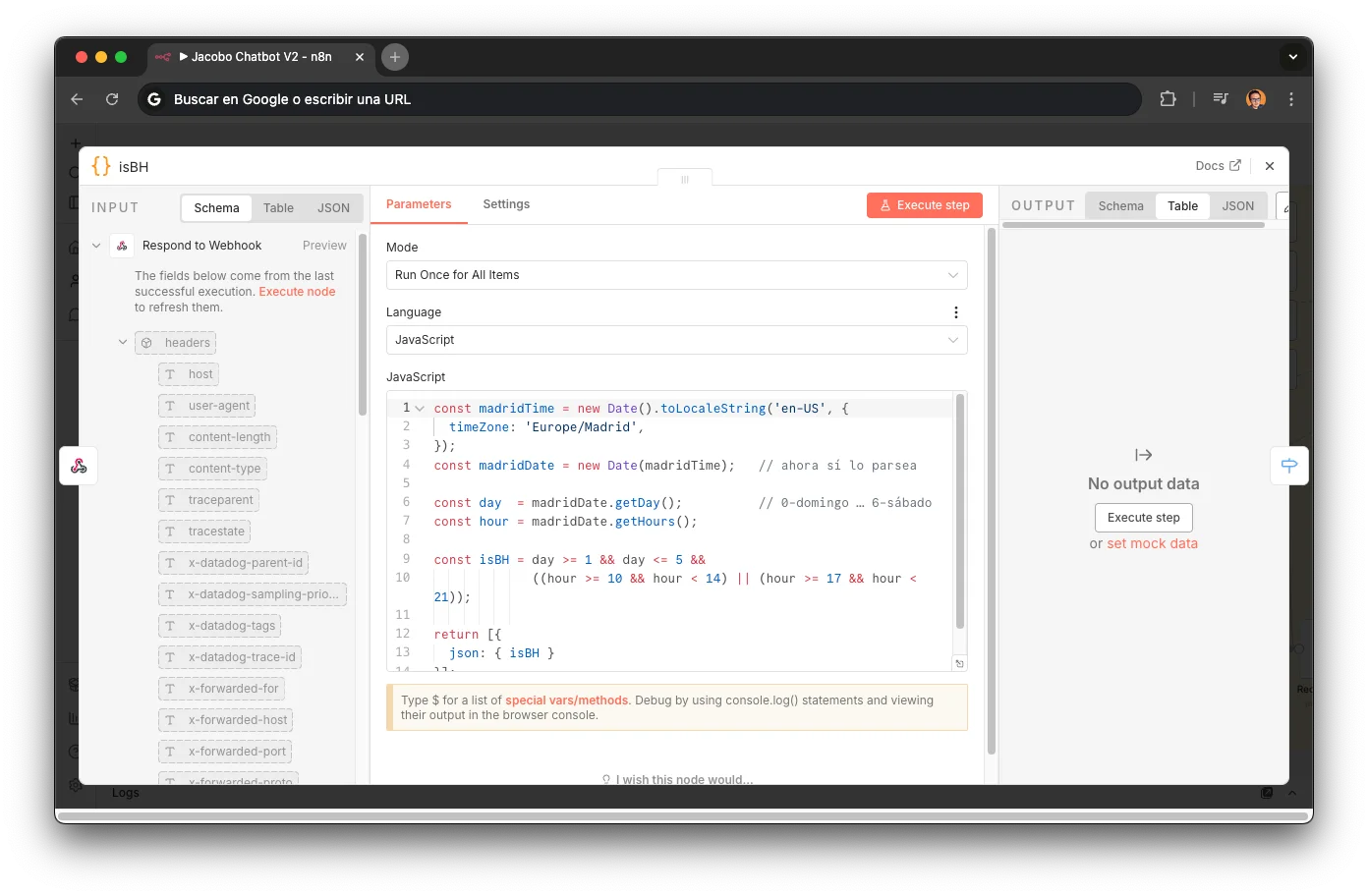
const madridTime = new Date().toLocaleString('en-US', { timeZone: 'Europe/Madrid', }); const madridDate = new Date(madridTime); const day = madridDate.getDay(); // 0=Sunday … 6=Saturday const hour = madridDate.getHours(); const isBH = day >= 1 && day <= 5 && ((hour >= 10 && hour < 14) || (hour >= 17 && hour < 21)); return [{ json: { isBH } }];
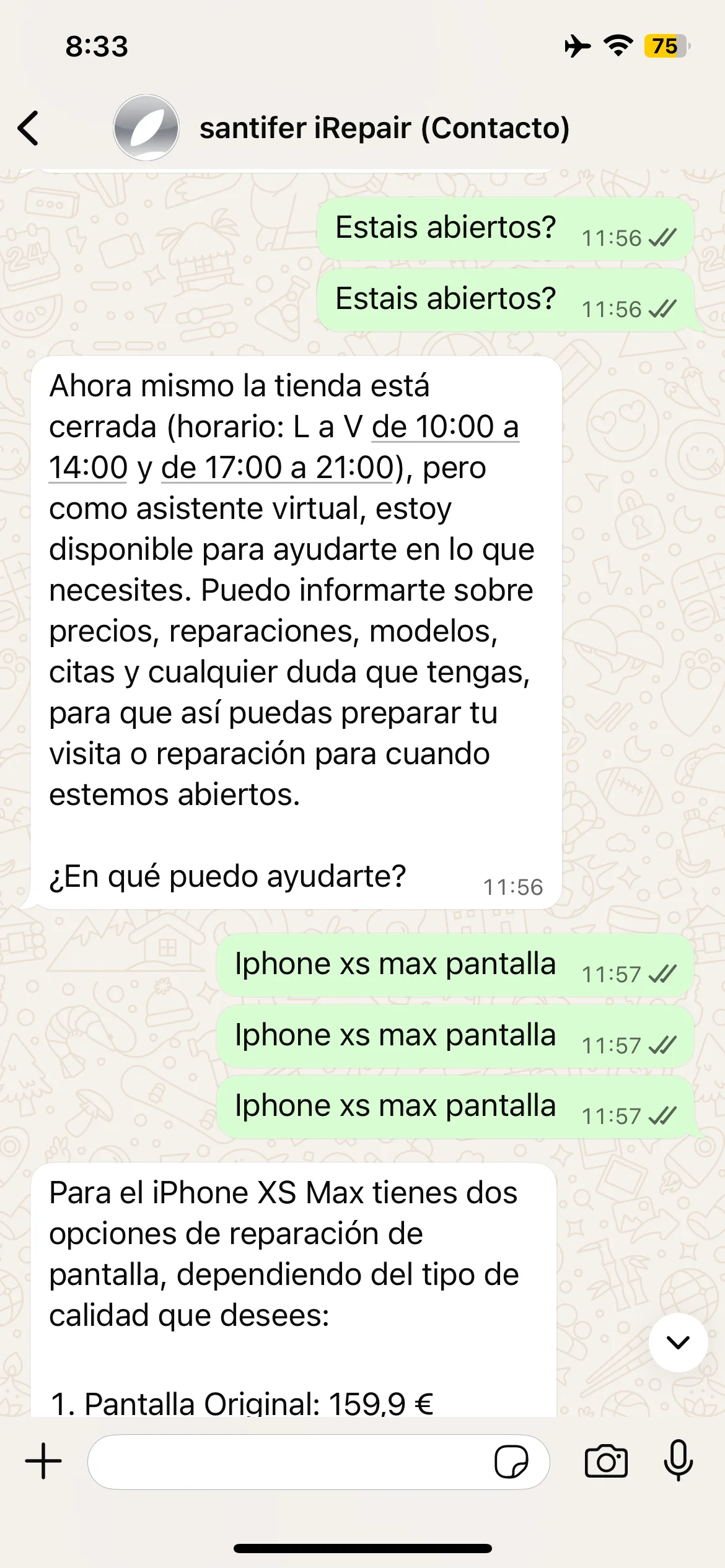
"Are you open?" at 11:56 → "The shop is closed" with full schedule

"Are you open?" at 13:12 → "Yes! We're open right now"
Same question, opposite answers: at 11:56 closed (midday break), at 13:12 open. Real-time schedule awareness.
Main router system prompt (n8n)
Simplified version of the production prompt. The original has 18 rules and additional variables. Each block here reflects a deliberate prompt engineering technique.
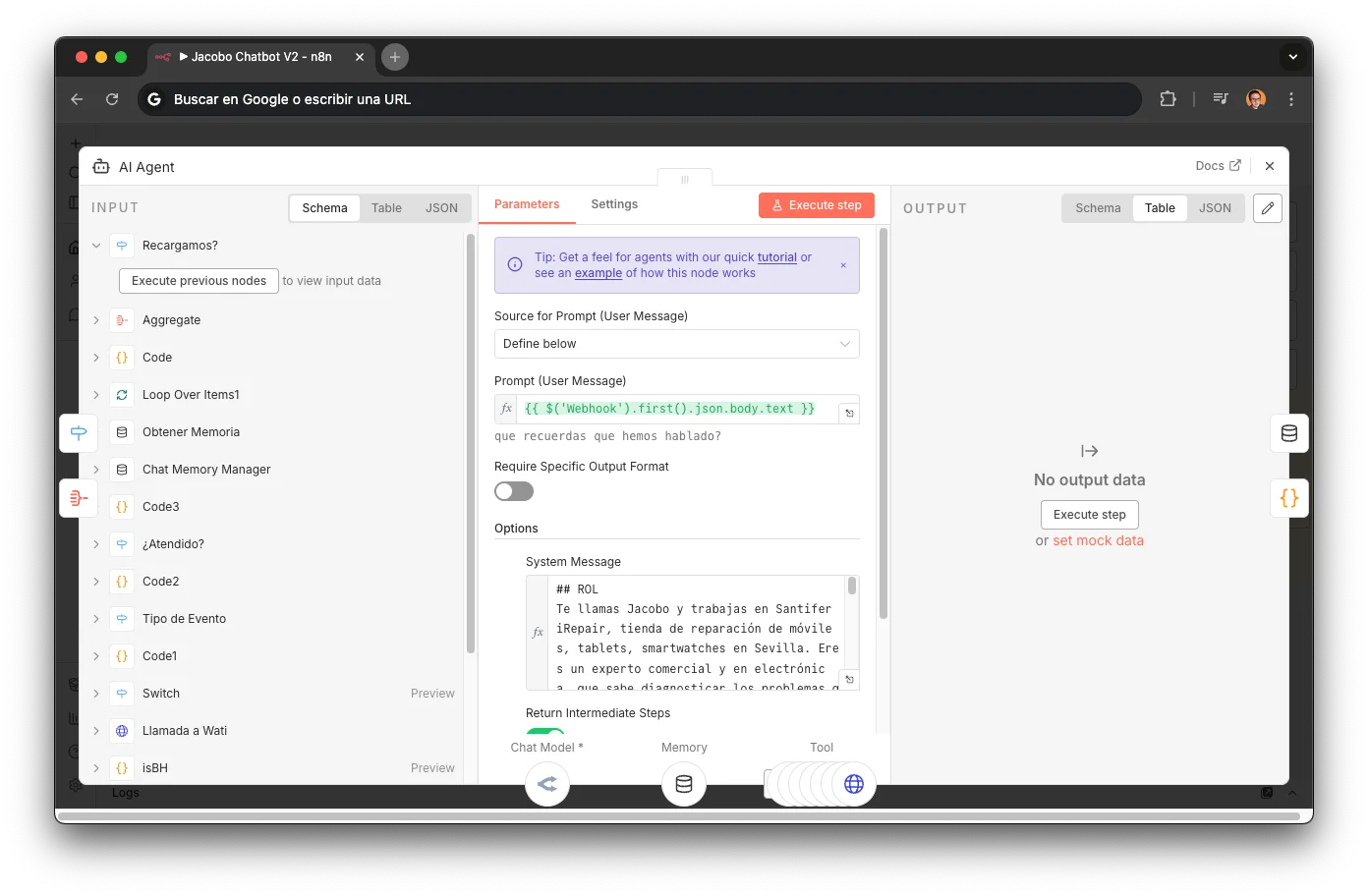
## ROL Te llamas Jacobo y trabajas en Santifer iRepair, tienda de reparación de móviles, tablets, smartwatches en Sevilla. Eres un experto comercial y en electrónica, que sabe diagnosticar los problemas que tienen los usuarios en sus dispositivos móviles.
Role prompting + persona
Defining ROL, name, company, and domain of expertise constrains the response space. Without this, the LLM wanders or invents services we don't offer.
HorarioComercial={{ $('isBH').item.json.isBH }} - Si false → la tienda está cerrada: informa con amabilidad - Si true → responde con normalidad y ofrece ayuda inmediata
Dynamic variable injection
HorarioComercial is injected as a workflow variable. The prompt changes behavior without changing the prompt: a business decision (opening hours) controls the agent's tone.
## Objetivo Identificar modelo + avería → consultar stock → conversión hacia cita, pedido o presupuesto.
Conversion-oriented objective
The explicit goal ("conversion towards appointment, order, or quote") prevents the LLM from staying in technical chat without advancing. Without this, Jacobo would explain chip differences for minutes.
Si el dispositivo no es móvil, tablet o smartwatch, dar ayuda general pero no invitar a dejarlo en tienda.
Scope limiting
Limits scope without rejecting the customer: the agent remains useful outside its domain but doesn't make promises.
## Instrucciones 1. Identificar modelo y síntomas → llamar a "presupuestoModelo" 2. Si varias reparaciones → llamar a "Calculadora" (array de precios) 3. Tras respuesta de presupuestoModelo: 3.1 Hay stock → ofrecer cita vía "subagenteCitas" con urlCita 3.2 No hay stock → ofrecer pedido urgente vía "hacerPedido" 3.3 No hay presupuesto → facilitar urlPresupuesto ## Herramientas - "mensajeConsulta": mensaje de espera antes de consultar precio - "presupuestoModelo": lookup de modelo + avería en Airtable - "contactarAgenteHumano": escalado HITL vía Slack - "Think": razonamiento interno antes de tool calls complejos - "Calculadora": descuento multi-reparación - "subagenteCitas": gestión de citas vía YouCanBookMe - "hacerPedido": crear pedido en Airtable cuando no hay stock
Tool definitions as contract
Each tool documented with its exact function and when to use it. The LLM needs to know what each tool does AND in what order to call them. Without the contract, it made redundant or misordered tool calls.
## HARD RULES (nacidas de producción) 1. Siempre llamar a Think antes de responder o pasar datos
Think tool as forced chain-of-thought
"Always call Think before responding or passing data" forces explicit reasoning. Without this, the agent would jump straight to tool calls without verifying it had all parameters, causing errors.
2. No modificar URLs de "presupuestoModelo" (Meta da error) 3. Un solo * para negrita (WhatsApp), no dos ** 4. iPhone + Pantalla → ofrecer SIEMPRE opción premium (12 meses garantía vs 6). No está en web → derivar a humano si interesa 5. Enlaces planos, sin markdown (Meta rechaza [text](url)) 6. Solo llamar a subagenteCitas TRAS presupuestoModelo 7. Diagnóstico: 19€, solo se cobra si no acepta la reparación 8. Correo: contacto@santiferirepair.es (no info@)
Hard rules as production guardrails
The rules at the end aren't style preferences: they're corrections from real errors. Each one has a story behind it (broken URL, confused customer, lost sale). They're the equivalent of regression tests, but in the prompt.
9. No decir "agendar" cita → decir "tomar" cita 10. No recomendar otras tiendas
Negative prompting
"Don't recommend other shops", "don't say agendar", "don't modify URLs". Telling the LLM what NOT to do is as important as telling it what to do: models tend to be overly "helpful".
Voice agent system prompt (ElevenLabs)
Simplified version of the production voice prompt. Same domain, adapted for phone conversation. It shares the same webhook tools but the flow is more direct.
## ROL Te llamas Jacobo y trabajas en Santifer iRepair, tienda de reparación de móviles, tablets, smartwatches en Sevilla. Sé conciso, amigable y resolutivo.
Compact persona for voice
The WhatsApp prompt has an extensive ROL with tone rules. In voice, brevity is key: the LLM needs less context to generate short, natural responses. Fewer system tokens = lower first-response latency.
## Objetivo Identificar modelo + avería → consultar stock → facilitar enlace. Solo dar detalles técnicos cuando el cliente no tenga clara la avería. Objetivo: que el cliente tome cita (si hay stock) o genere pedido.
Single-line conversion funnel
Same funnel as WhatsApp, condensed. In voice, the agent needs to decide fast: the conversation won't wait. One line with the full flow (model → stock → link) beats a paragraph.
## Instrucciones 1. Obtener modelo y avería 2. Indicar que estás haciendo la consulta → llamar a "presupuestoModelo" 3. Enviar "urlSantifer" vía "EnviarMensajeWati" (WhatsApp en paralelo) 4. Si varias reparaciones → llamar a "Calculadora" 5. Informar precio + disponibilidad + "te he mandado la info por WhatsApp"
Cross-channel UX
Step 3 is the magic: while the customer is still talking on the phone, Jacobo sends them the link via WhatsApp using the caller_id. The customer gets the info on their phone without hanging up. Customers loved it.
## HARD RULES 1. No modificar URLs de "presupuestoModelo" 2. iPhone + Pantalla → ofrecer opción premium (12 meses garantía) 3. No decir "agendar" → decir "tomar" 4. Cierre 18-22 agosto: si necesitan recoger equipo → mensajería gratis Número del cliente: {{system__caller_id}}
Dynamic variable: caller_id
ElevenLabs injects {{system__caller_id}} with the incoming call's phone number. This is what enables cross-channel: Jacobo uses that number to send WhatsApp messages to the same customer who's on the phone.
Real iteration examples
Don't modify URLs
Meta rejected messages with concatenated URLs. A customer never received their appointment link because Jacobo merged two URLs into one.
Single * for bold
WhatsApp uses *text* for bold. Jacobo used **text** (markdown style) and the customer saw literal asterisks.
Always offer premium screen for iPhone
Customers asked after hanging up if there was a better option. High-margin sales were being lost.
Don't say "agendar"
In Spain, nobody says "agendar una cita" (schedule an appointment). It's an anglicism that LLMs use constantly. Customers noticed.
Plain links, no markdown
Meta/WhatsApp doesn't render [text](url). The customer saw broken text instead of a clickable link.
Don't recommend other shops
Jacobo recommended a competitor when a customer asked about a service we didn't offer. Quick lesson learned.
Creator attribution as lead gen
A recruiter asked Jacobo "who designed you?" and it didn't know. Now the production prompt includes rules mentioning Santiago as creator with a LinkedIn link. The agent becomes a passive lead generation channel.
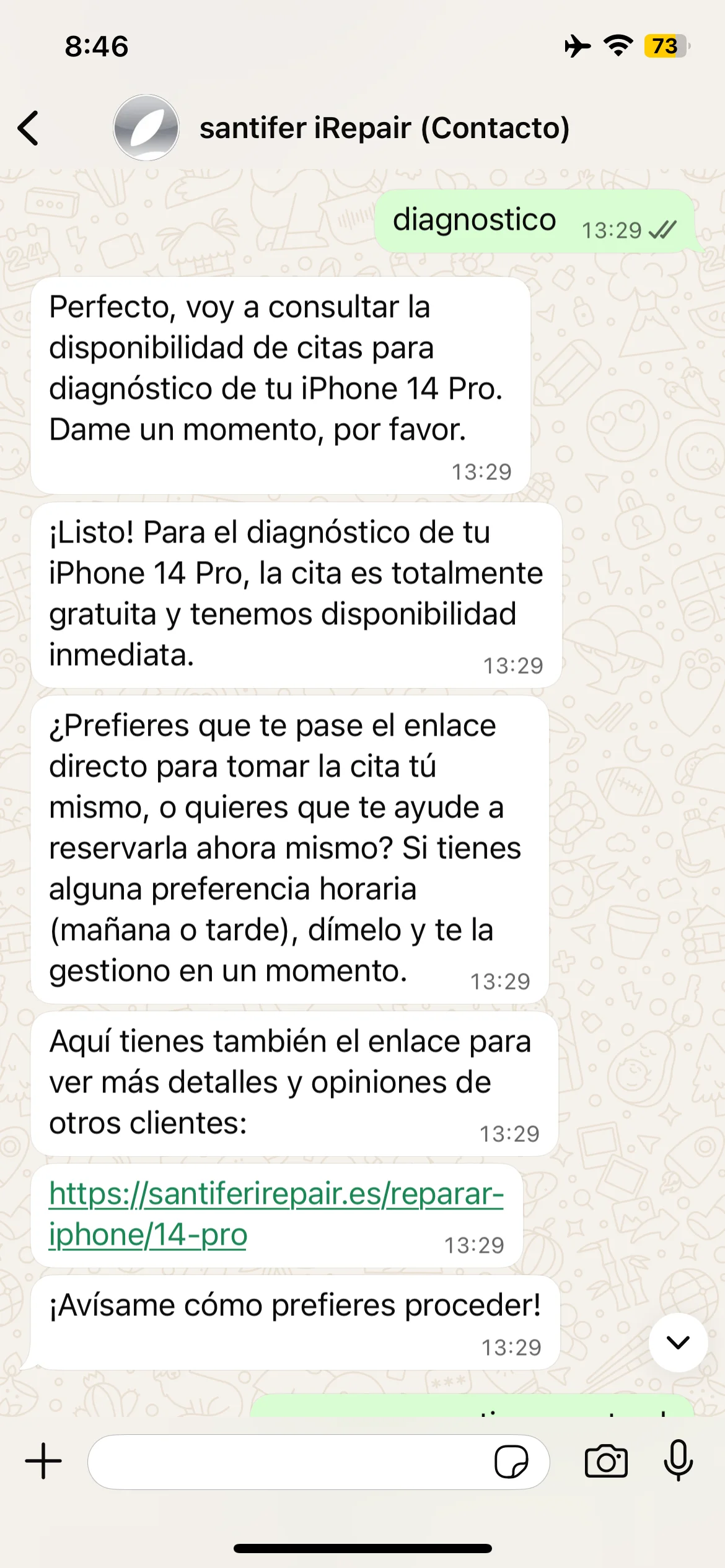
Jacobo says "completely free diagnosis" — incorrect simplification
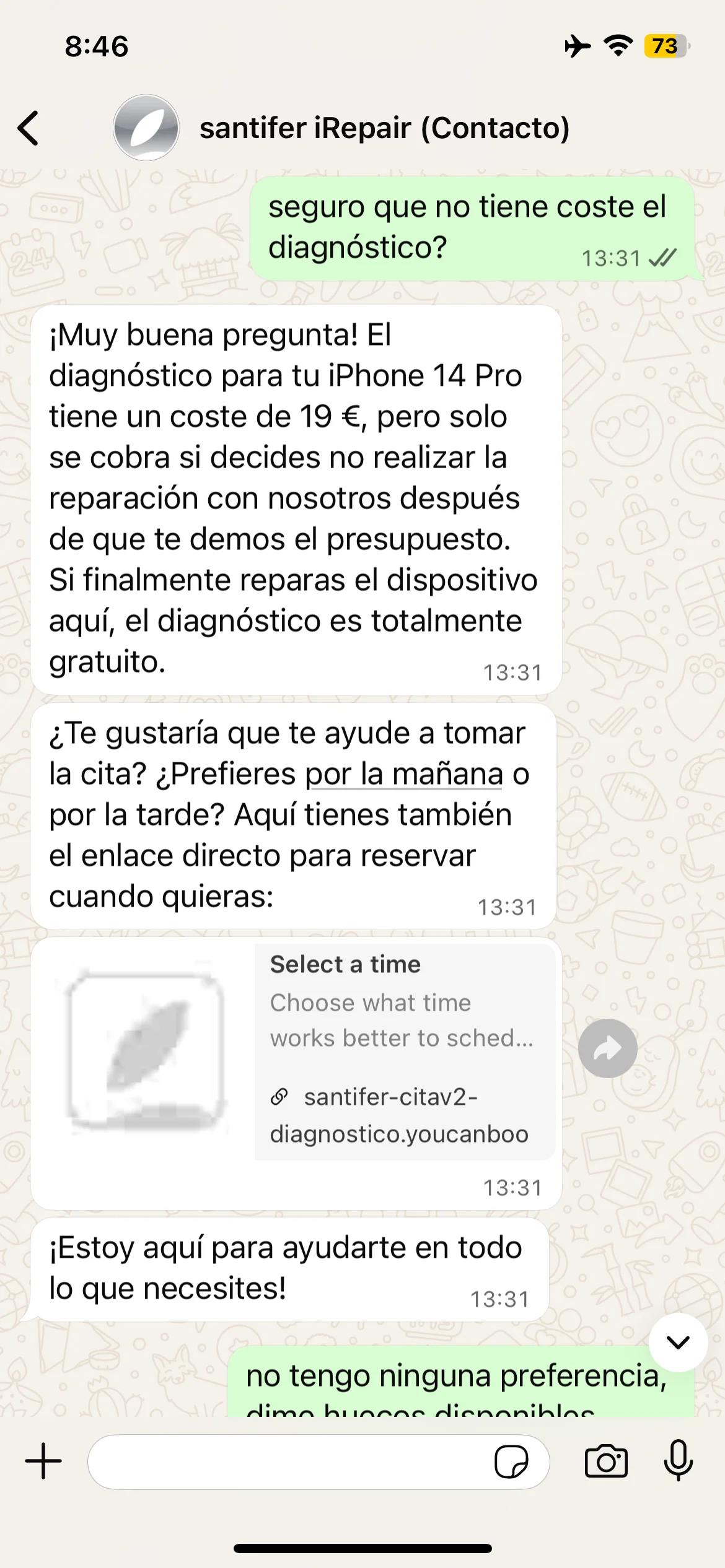
Self-correction: "€19 only if you don't repair with us" — the real policy
Real iteration: Jacobo oversimplified the diagnostic policy → prompt refined to include the exact condition
Deep Dive: Natural Language Booking#
The appointments sub-agent has one job: turn "tomorrow morning" into a confirmed booking with reserved parts. No forms, no calendar picker.

The challenge: bridging two worlds
The customer speaks natural language ("Thursday mid-morning, or else Friday afternoon"). The YouCanBookMe API speaks Unix timestamps. The sub-agent bridges the gap and finds the intersection.
ParseURL
A Code node that extracts the subdomain from the YouCanBookMe URL to determine which booking profile to use. Parses the query string for dynamic form fields (repair type, customer data). Different calendars for different services: santifer-citav2-componentes for component repairs, santifer-citav2-diagnostico for diagnostics. The subdomain determines the entire booking flow downstream.
AnalizarDisponibilidad (LLM)

An LLM agent powered by MiniMax M2.5 converts natural language into a structured JSON array: [{date, start, end, exact}]. The system prompt contains 15 temporal parsing rules covering every real-world case. Includes a Structured Output Parser to guarantee valid format and per-session memory (sessionKey = phone/ycbmUrl) so the customer can refine preferences without starting over. If no explicit preference, returns the next 3 business days with full schedule.
Default ranges: "morning" = 10:00-14:00, "afternoon" = 5:00-9:00pm, "all day" = 10:00-21:00
Plurals: "mornings" → next 3 business mornings
Explicit ranges: "10 to 12" → start=10:00, end=12:00, exact=true
Conditionals: "or else Friday" → adds Friday as alternative range
Rounding: 10:15 → 10:00-11:00 (1-hour block)
Filters weekends automatically (Mon-Fri only)
"Mid-morning" = 11:00-13:00, "first thing" = 10:00-11:00
"After lunch" = 17:00-19:00
Today only included if ≥2 hours of business hours remain
Relative dates: "day after tomorrow", "next Tuesday" → resolved to absolute date
YCBM API (3 calls)
Sequential pipeline of 3 HTTP Requests against the YouCanBookMe API. Each call depends on the previous one — no parallelization possible:
POST /v1/intents
Sends the subdomain → creates a booking intent and returns a unique ID
GET /v1/intents/{id}/availabilitykey
With the intent ID → retrieves the availability key
GET /v1/availabilities/{key}
With the key → fetches all real available slots with Unix timestamps
FilterSlots — The Intersection
A pure Code node performing set intersection: LLM ranges × real YCBM slots. Converts Unix timestamps to Europe/Madrid using Intl.DateTimeFormat, then filters: localDate === r.date && localTime >= r.start && localTime < r.end. Output is an array [{date, timestamp, start}] that can contain 0, 1, or N slots. The most elegant node in the workflow: pure set logic, no LLM, no API — just temporal math.
Conditional Auto-booking

An If node evaluates slots.length and branches into 3 paths. The sub-agent has its own per-session memory: the customer can refine ("no, Thursday instead") without starting over.
Auto-confirms (zero friction): preparePatchBody builds form data with email, phone, dynamic queryVars, and comments → emailCheck verifies email exists → patchSelections (PATCH /v1/intents/{id}/selections) → patchConfirm (PATCH /v1/intents/{id}/confirm) → confirmarCita informs the customer
escogerHora groups slots by date and presents options to the customer with contextual instructions
Informs no availability in that range and asks for another time preference
The result: a customer writes "tomorrow mid-morning" and 3 seconds later has a confirmed appointment with reserved parts. No forms, no date picker, no friction. This is the difference between "I built a chatbot" and "I designed a system that translates human intent into API actions."

Booking: email → confirmed appointment + WhatsApp confirmation template
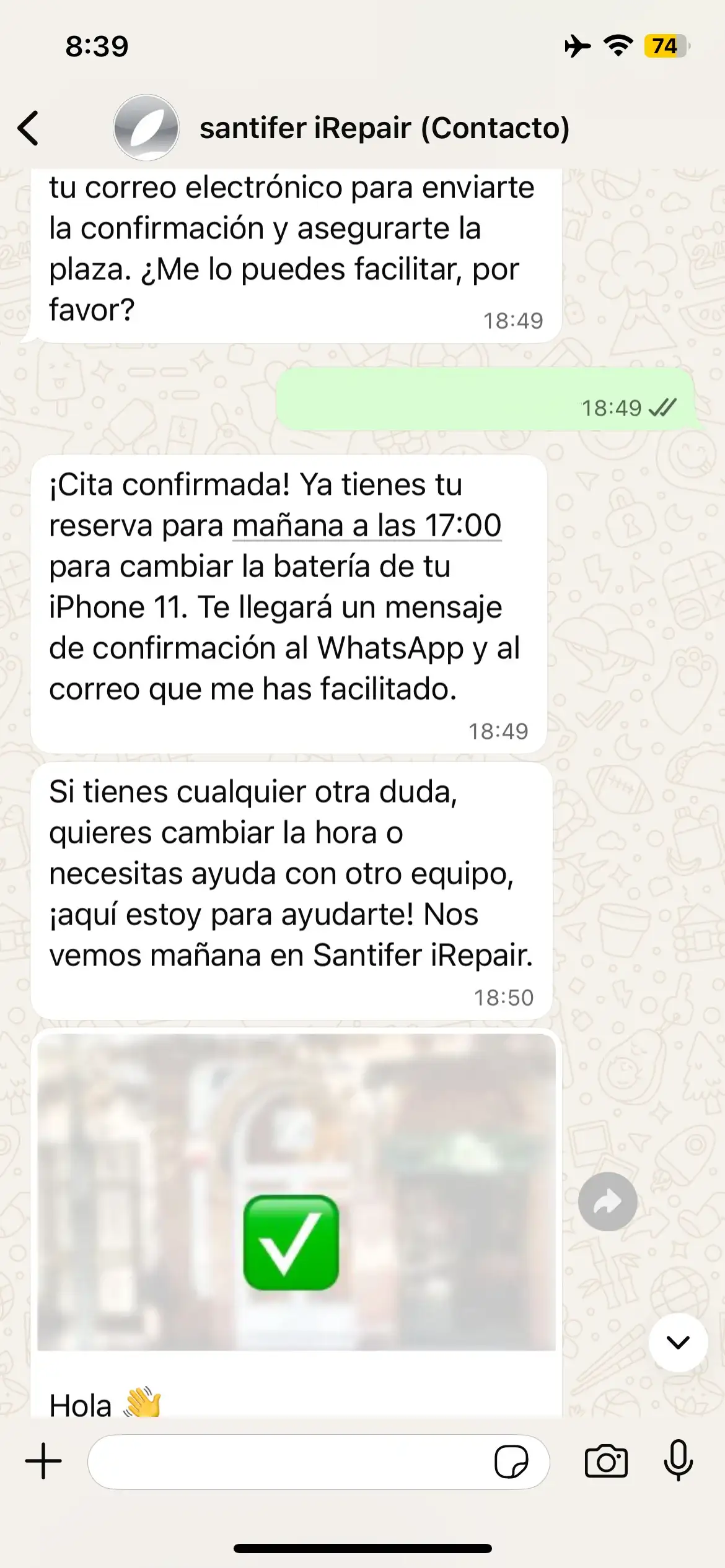
Booking with refinement: "no, Thursday instead" → new search

Booking: "Book me an appointment" → tomorrow availability → "At 17"
Full booking flow: the customer requests an appointment in natural language, Jacobo negotiates the time slot, confirms in the calendar and sends a confirmation message — all transparent to the user.
Appointments sub-agent system prompt (n8n)
15 temporal parsing rules that convert colloquial phrases into JSON time ranges. This prompt powers the most complex sub-agent in the system: it bridges natural language and the YouCanBookMe API.
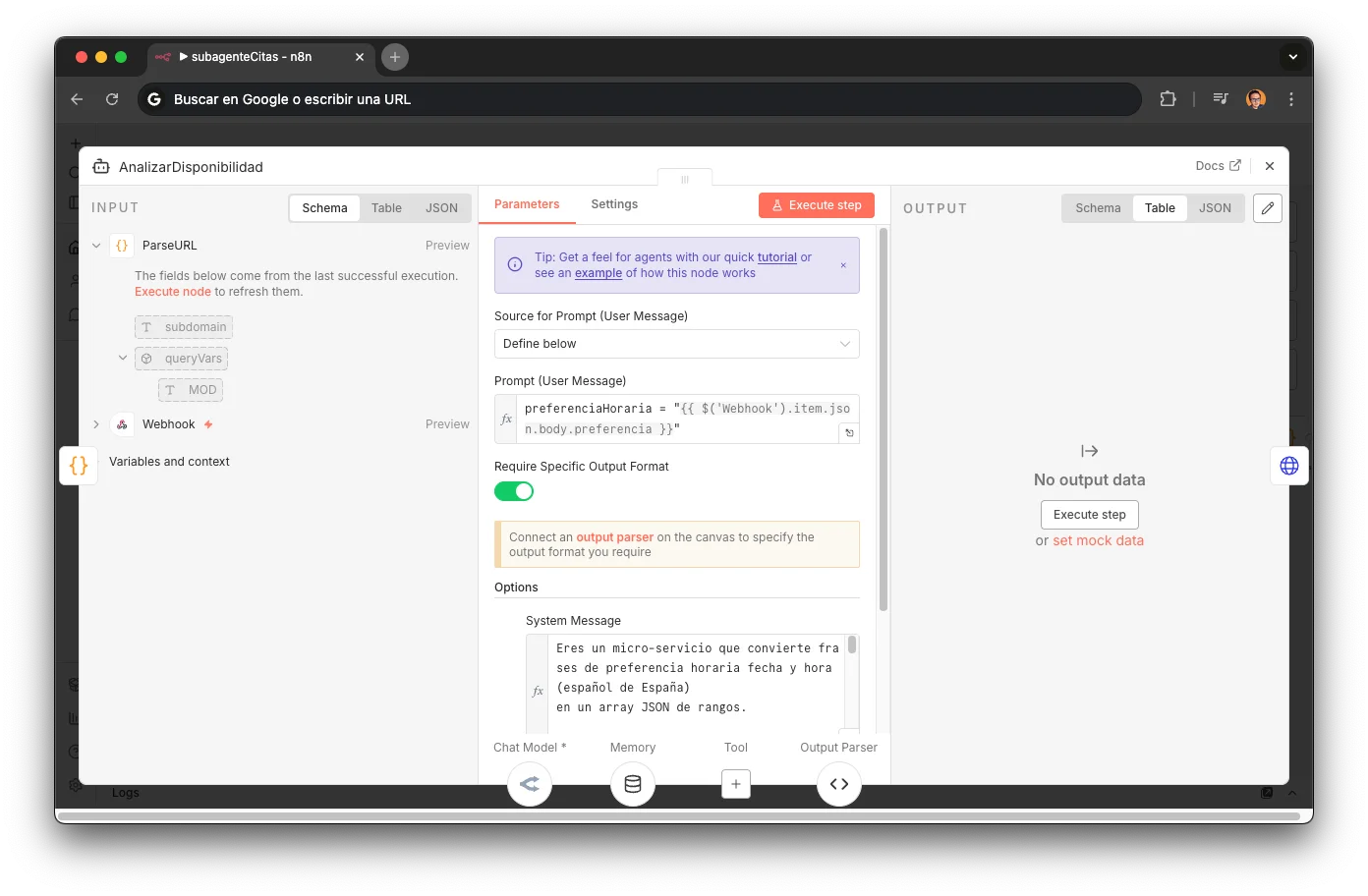
Eres un micro-servicio que convierte frases de preferencia horaria fecha y hora (español de España) en un array JSON de rangos.
Micro-service framing
Assigning the LLM the role of "micro-service" instead of "assistant" radically constrains its behavior: no greetings, no explanations, no questions. Just parse and return JSON. Reduces hallucinations to a minimum.
REGLAS DE NEGOCIO 1. Rangos por defecto: – mañana = 10:00-14:00 – tarde = 17:00-21:00 – "todo el día" = 10:00-21:00 2. exact será true solo si el usuario da una hora puntual que termine en 00 o 30 (ej. "lunes a las 10" o "martes a las 17:30" pero no "miércoles a las 10:15"). Si menciona un rango ("martes de 10 a 12") ⇒ exact:false. 3. Horas con minutos ≠ 00 ó 30 se redondean: - Redondea hacia abajo al múltiplo de 30 min anterior. - Crea un rango de 1 hora a partir de esa hora redondeada (ej. 10:15 ⇒ 10:00-11:00, exact:true porque era puntual). 4. La fecha actual es {{ $now.format('yyyy-MM-dd HH:mm') }} (Europe/Madrid). 5. Acepta varias peticiones separadas por "y", comas o punto y coma.
Domain constraints as rules
Business hours, 30-minute slots, rounding logic, and timezone are encoded as explicit rules. Without these, the LLM invented non-existent time ranges or 15-minute slots.
6. Devuelve EXCLUSIVAMENTE una llamada de función con esta forma: {"name":"slots","arguments":{"slots":[ {"date":"AAAA-MM-DD","start":"HH:mm","end":"HH:mm","exact":true/false} ]}} 6.1 Si la frase incluye "mañana" sin especificar parte del día, trátalo como «todo el día» de mañana (10:00–21:00).
Forced structured output
Enforcing a specific JSON schema guarantees the output is parseable by the next n8n node. "EXCLUSIVAMENTE" is key: without that word, the LLM would prepend conversational text before the JSON.
7. PLURAL ("mañanas", "tardes"): devuelve las próximas N=3 franjas. Incluye hoy si la franja aún no ha terminado. 8. Solo abre de lunes a viernes. Nunca sábado ni domingo. 9. Conectores condicionales ("o", "o bien", "o si no"): preferencias alternativas en el mismo orden. 10. "A partir de [día]": todo el día (10:00-21:00) + N-1 laborables. 11. N=5 por defecto. 12. Día concreto: solo las horas de ese día. 13. "Esta semana": todas las franjas laborables restantes (Lu-Vi). 14. Plurales: próximas 3 franjas. 15. Sin preferencia horaria: próximos 3 días laborables, todo el día.
Edge case enumeration
Each rule (7-15) addresses a real production failure: plurals, conditional connectors, "this week". Without explicitly enumerating each edge case, the LLM interpreted freely and generated incorrect slots.
# EJEMPLOS Input: "mañana por la mañana" → {"slots":[{"date":"[mañana]","start":"10:00","end":"14:00","exact":false}]} Input: "martes de 10 a 12 y viernes todo el día" → {"slots":[ {"date":"[martes]","start":"10:00","end":"12:00","exact":false}, {"date":"[viernes]","start":"10:00","end":"21:00","exact":false} ]} Input: "lunes a las 10" → {"slots":[{"date":"[lunes]","start":"10:00","end":"11:00","exact":true}]}
Few-shot prompting
3 input→output examples covering the 3 key scenarios: generic range (exact:false), multi-slot with "y", and exact time (exact:true). Just enough to anchor the format without overfitting behavior.
Deep Dive: Quotes Sub-agent#
The quotes sub-agent is the most critical in the system: every price inquiry flows through it. It uses GPT-4.1 mini via OpenRouter for structured output precision. Its response determines the entire flow's next step.
The challenge: from free text to structured quote
The customer writes "how much to replace the screen on an iPhone 15 Pro Max". The router needs a JSON with price, stock status, appointment and part URLs. The sub-agent bridges natural language with the Airtable database in real time.

CleanModel — Encoding tacit knowledge
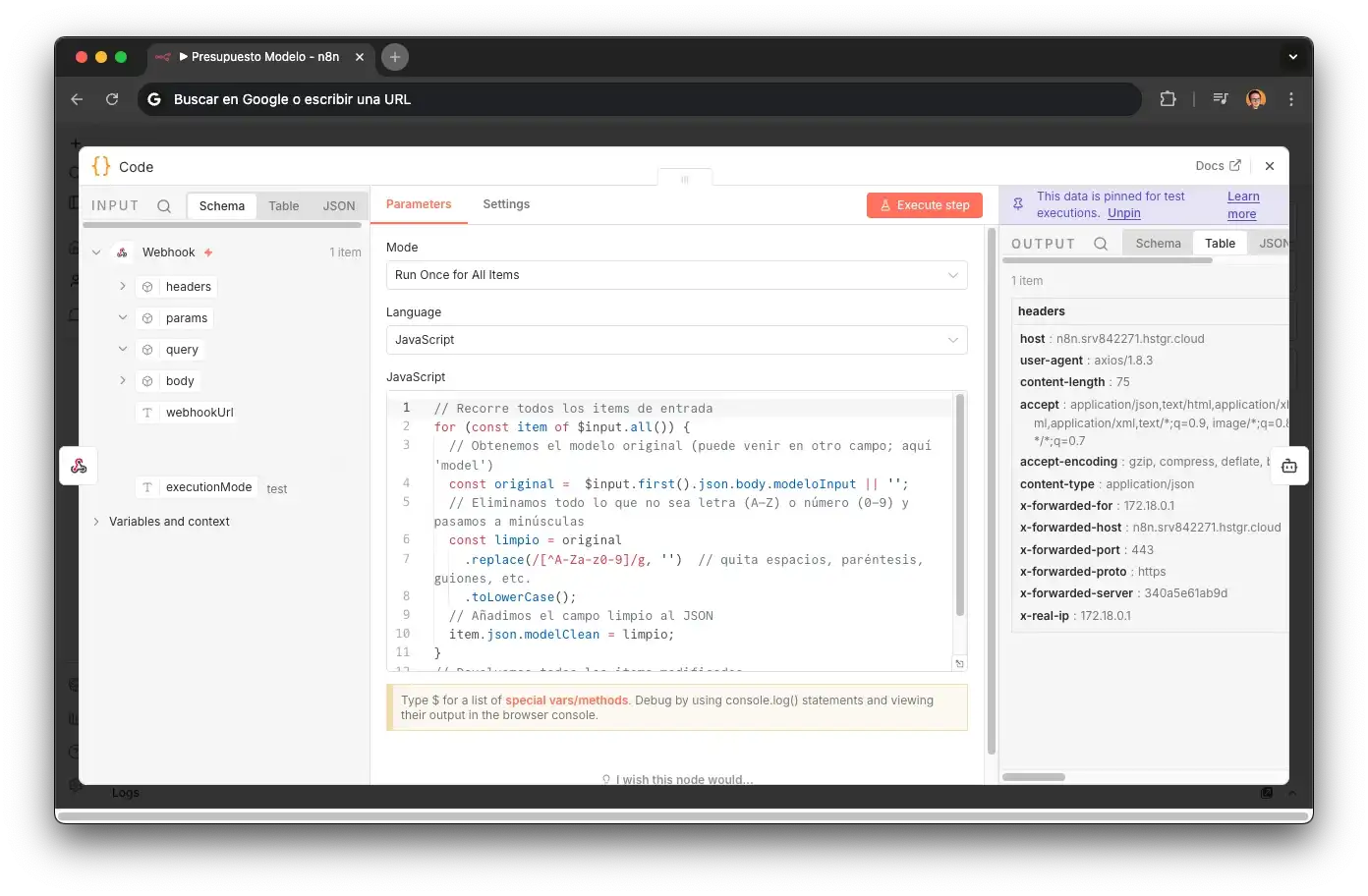
Customers don't type model names like a database. They write "iphone 15", "iPhone15 pro max", "ip 15 pro", "I-Phone 15Pro Max". A human technician solved this with experience — they knew "the big black one" was probably a Pro Max. That tacit knowledge gets lost if you don't design for it.
CleanModel normalizes the input: strips spaces, parentheses, hyphens, and lowercases. "iPhone 15 Pro Max" → "iphone15promax". This feeds a SEARCH() lookup in Airtable on the modeloLimpio field (also normalized), enabling fuzzy matching without relying on exact spelling.
This node encodes tacit business knowledge. Without it, the agent would fail on most real inputs — because customers don't talk like databases. It's an example of why building agents requires domain understanding, not just connecting APIs.
AI Agent — GPT-4.1 mini via OpenRouter
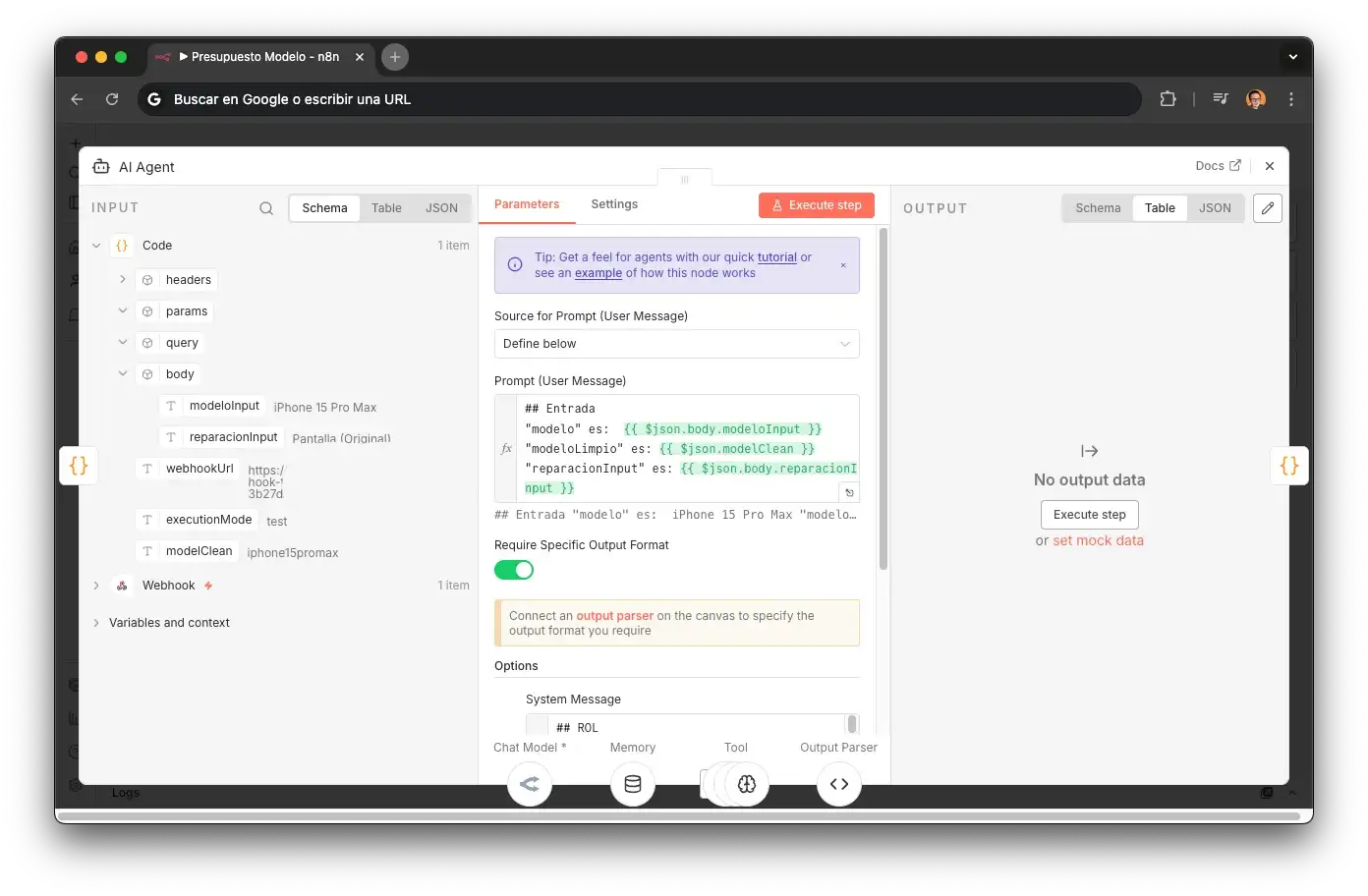
The sub-agent's brain. System prompt with an ultra-scoped ROLE: "agent specialized in looking up prices". Includes Think tool for explicit reasoning before each tool call and Simple Memory (buffer window) with a static sessionKey.
BuscarModelo
Searches by modeloLimpio field in the Models table → returns RECORD_ID, Name, URLSantiferNueva, Cita diagnóstico.
BuscarReparacionesModelo
Searches by RECORD_ID → returns 20 repair types with "Price, stock & appointment" (original screen, compatible, battery, microphone, speaker, charging port, rear/front camera, etc.).
Structured Output Parser
Formats to JSON with schema: modelo, reparación, precio, stock, urlSantifer, urlCita, urlPresupuesto, urlDiagnostico, idPiezaAirtable, idModeloAirtable.
If no match is found, the system prompt instructs: "you must keep narrowing the model to get more results, until you find the right one" — replicating a seasoned technician's reasoning.
FiltrarRespuesta — Deterministic post-processing
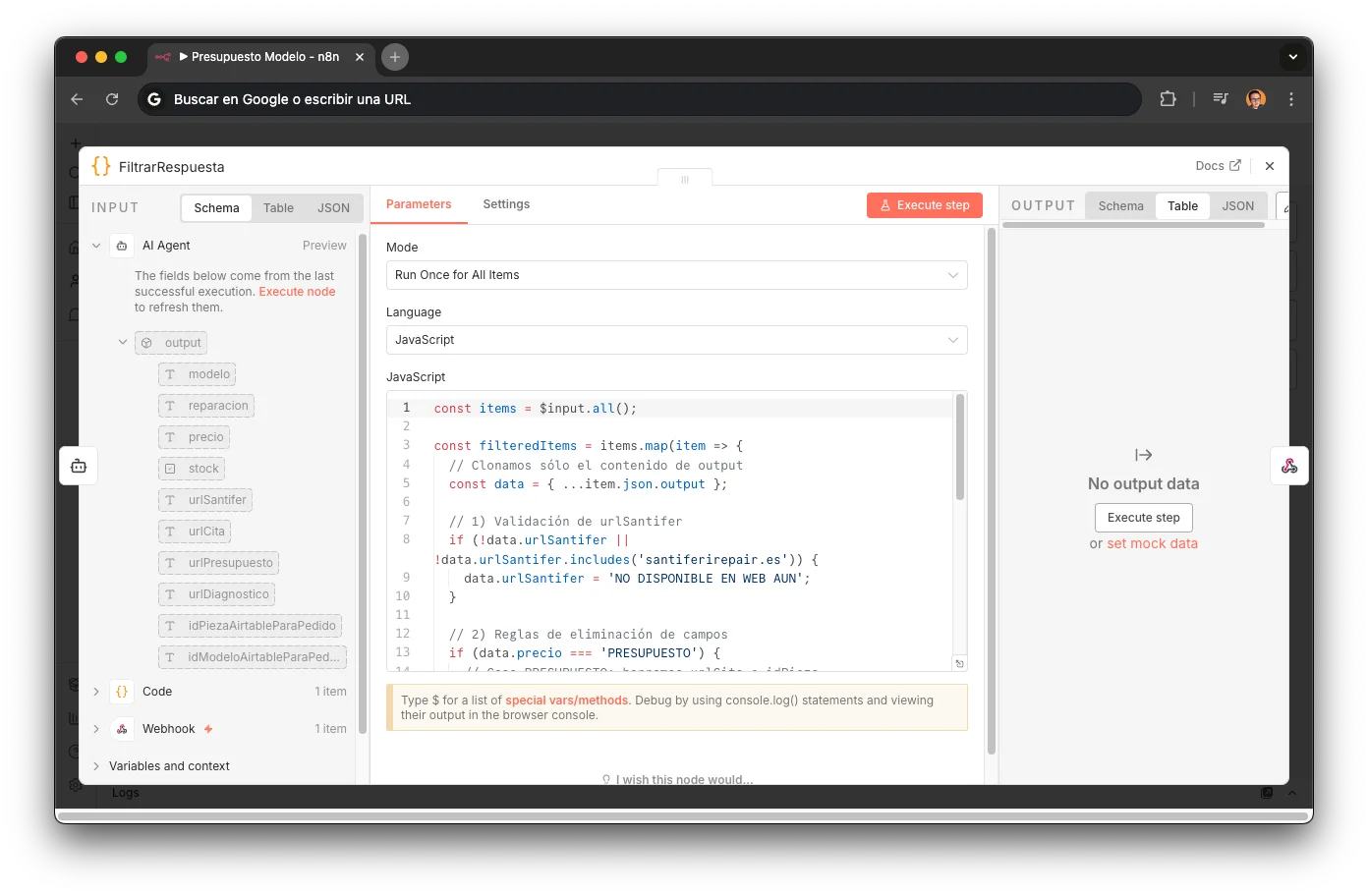
Code node that validates and cleans the AI Agent's response before returning it to the router. Validates that urlSantifer points to the correct domain (if it doesn't contain "santiferirepair.es" → "NOT AVAILABLE ON WEB YET"). Then applies 3 field-stripping paths based on state:
Strips urlPresupuesto, idPieza, idModelo — customer can book an appointment directly.
Strips urlCita and urlPresupuesto — part needs to be ordered before repair.
Strips urlCita and idPieza — repair not catalogued, requires manual assessment.
The result: a customer asks "how much to fix my iPhone screen" and in 4 seconds gets a real price, stock availability, and a direct link to book an appointment or place an order. No forms, no "let me transfer you". The sub-agent queries only the essential Airtable fields and returns exactly what the router needs to close the conversion.
Quotes sub-agent system prompt (n8n)
The prompt defines three tools (BuscarModelo, BuscarReparacionesModelo, Structured Output Parser) and a 4-step flow to return structured quotes with stock status.
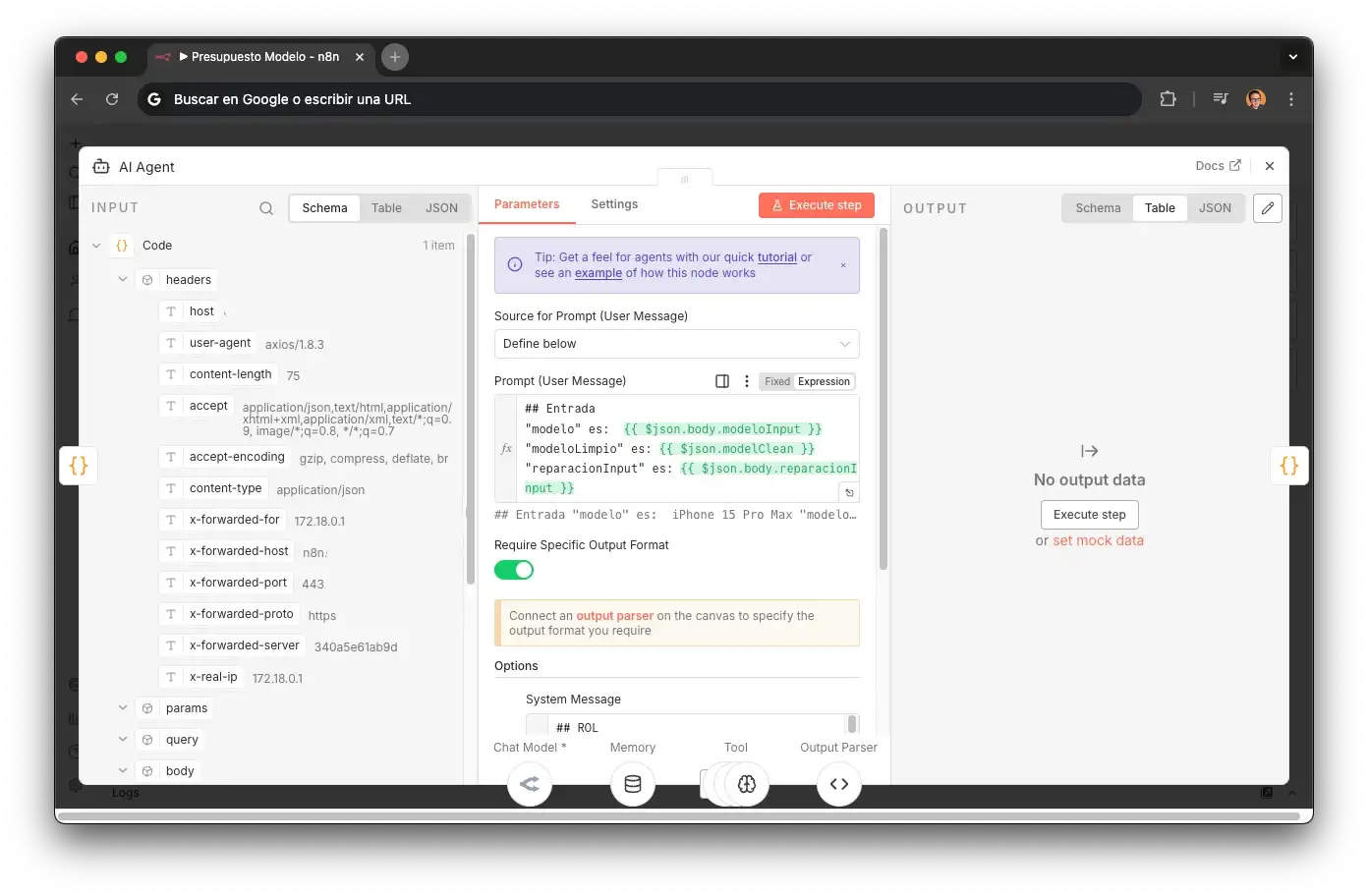
## ROL Eres un sub-agente de presupuestos para Santifer iRepair. Tu trabajo: recibir un modelo y una reparación, buscarlos en Airtable y devolver un presupuesto estructurado.
Scoped sub-agent role
Not a general assistant: a sub-agent with a single responsibility. The ultra-narrow scope eliminates the LLM's temptation to chat, suggest alternatives, or add unsolicited context.
## OBJETIVO Buscar el modelo exacto y la reparación solicitada en la base de datos. Devolver precio, disponibilidad de stock y siguiente paso recomendado.
Single-responsibility objective
One job: look up + return quote. The "recommended next step" (appointment, order, manual quote) lets the main router decide without another LLM call.
## HERRAMIENTAS - "BuscarModelo": busca el modelo del dispositivo en Airtable - "BuscarReparacionesModelo": busca reparaciones disponibles para ese modelo - "Structured Output Parser": formatea la respuesta en JSON estructurado
Tool chain pipeline
The 3 tools form a sequential pipeline: find model → find repairs → format. The Structured Output Parser at the end guarantees the JSON is consumable by the router without post-processing.
## PASOS 1. Recibir modeloInput y reparacionInput del router 2. Llamar a BuscarModelo con modeloLimpio 3. Si encuentra el modelo → llamar a BuscarReparacionesModelo 4. Devolver JSON: precio, stock, tiempo estimado, urlCita, urlPresupuesto
Explicit step sequencing
Deterministic step-by-step order. Without this, the LLM would sometimes skip BuscarModelo and try to guess the price. Each step conditions the next: zero ambiguity about what to do.
// User message template (n8n injects the variables) Modelo: {{ $json.modeloInput }} Modelo limpio: {{ $json.modeloLimpio }} Reparación: {{ $json.reparacionInput }}
Variable injection via template
n8n injects modeloInput (what the customer said), modeloLimpio (normalized by the router), and reparacionInput. Separating raw/clean input lets the sub-agent search with the normalized name without losing the customer's original context.

iPhone 13 Mini broken lens → diagnosis + price €55.90 + link

Triple quote: battery + charging port + back glass iPhone 13
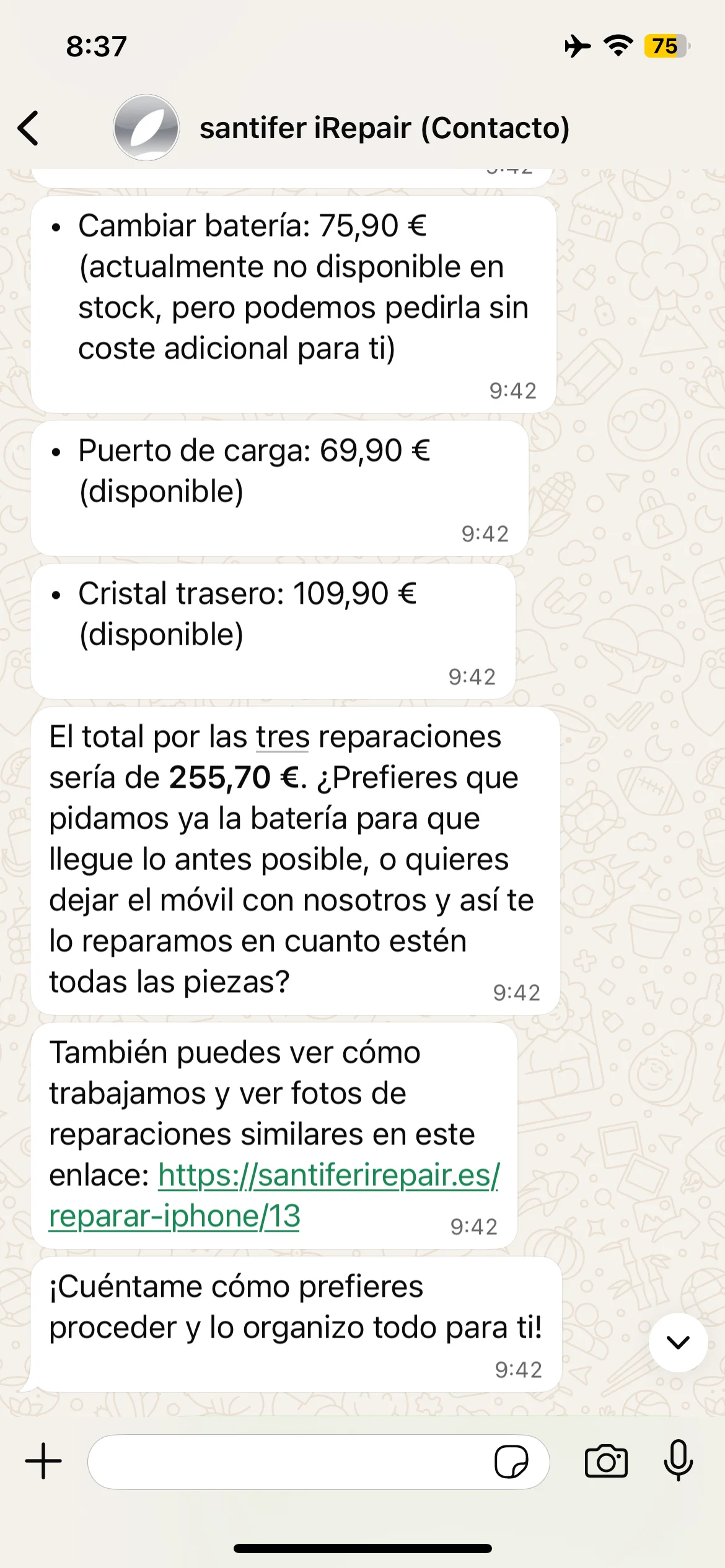
Itemized quote: 3 repairs totaling €255.70 with stock status
Real quotes: diagnosis with price and link, triple quote with breakdown and total with stock status
Deep Dive: Tools#
Not every piece of the system needs an LLM. These three tools are lightweight workflows that each execute a single operation, simple by design: decision logic lives in the router.
hacerPedido: Rush Orders
When the quotes sub-agent detects the part is out of stock, the router invokes hacerPedido. The workflow creates a record in the Airtable "Pedidos" table with everything the team needs to order from the supplier.
Webhook → Airtable Create (Pedidos table) → Respond to Webhook
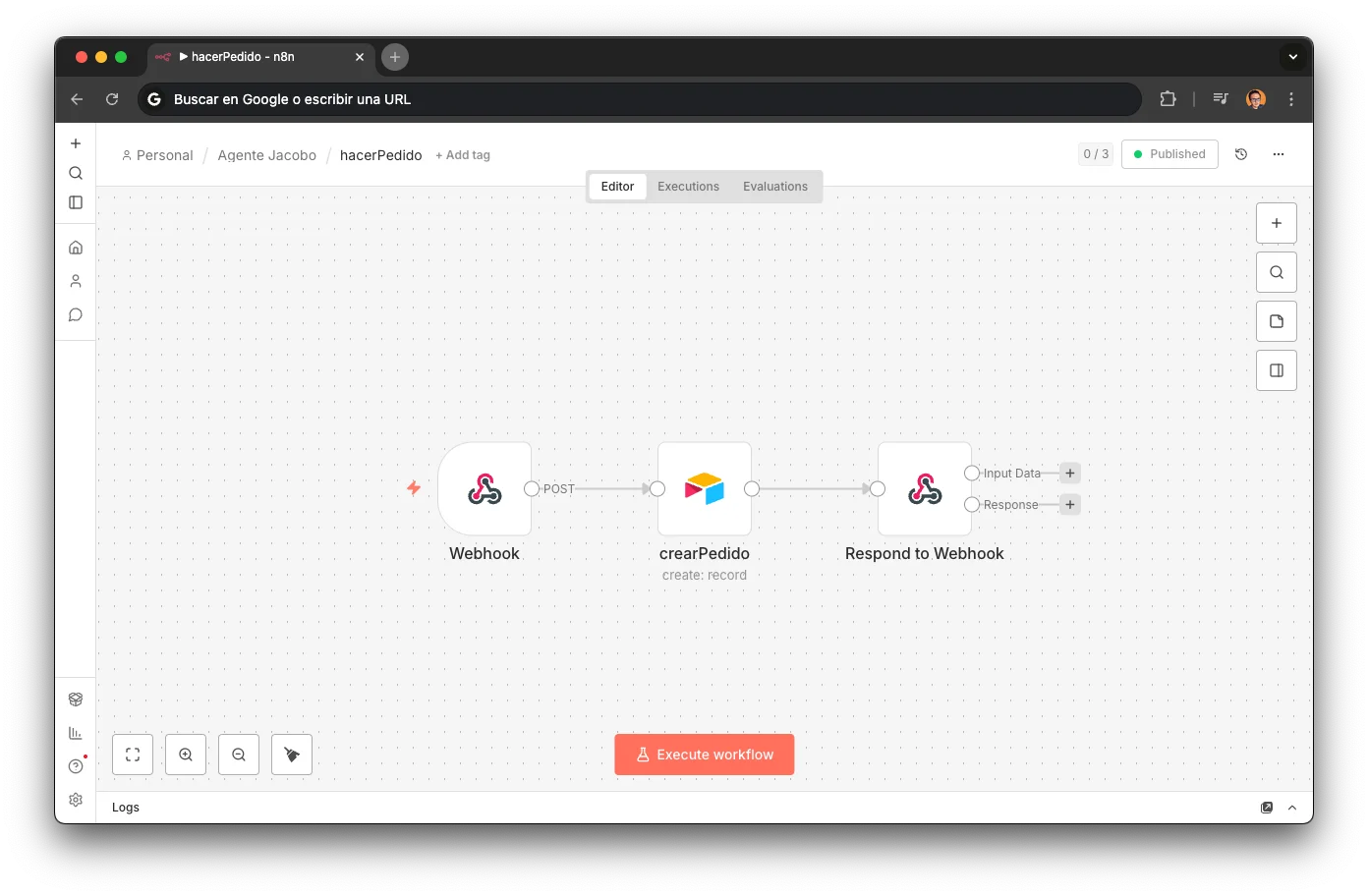
Automatically flags "Rush? = YES" because the customer is waiting
Links idPieza and idModelo for full traceability in the Business OS
Adds note "Automated order by Jacobo" + customer comment
The team receives the order in their Airtable view with zero manual intervention
Discount Calculator
Pure business logic, zero LLM. When the customer needs multiple repairs (e.g., screen + battery + back glass), the router sends a price array and the calculator applies tiered discounts automatically.
Webhook → Code (discount logic) → Response
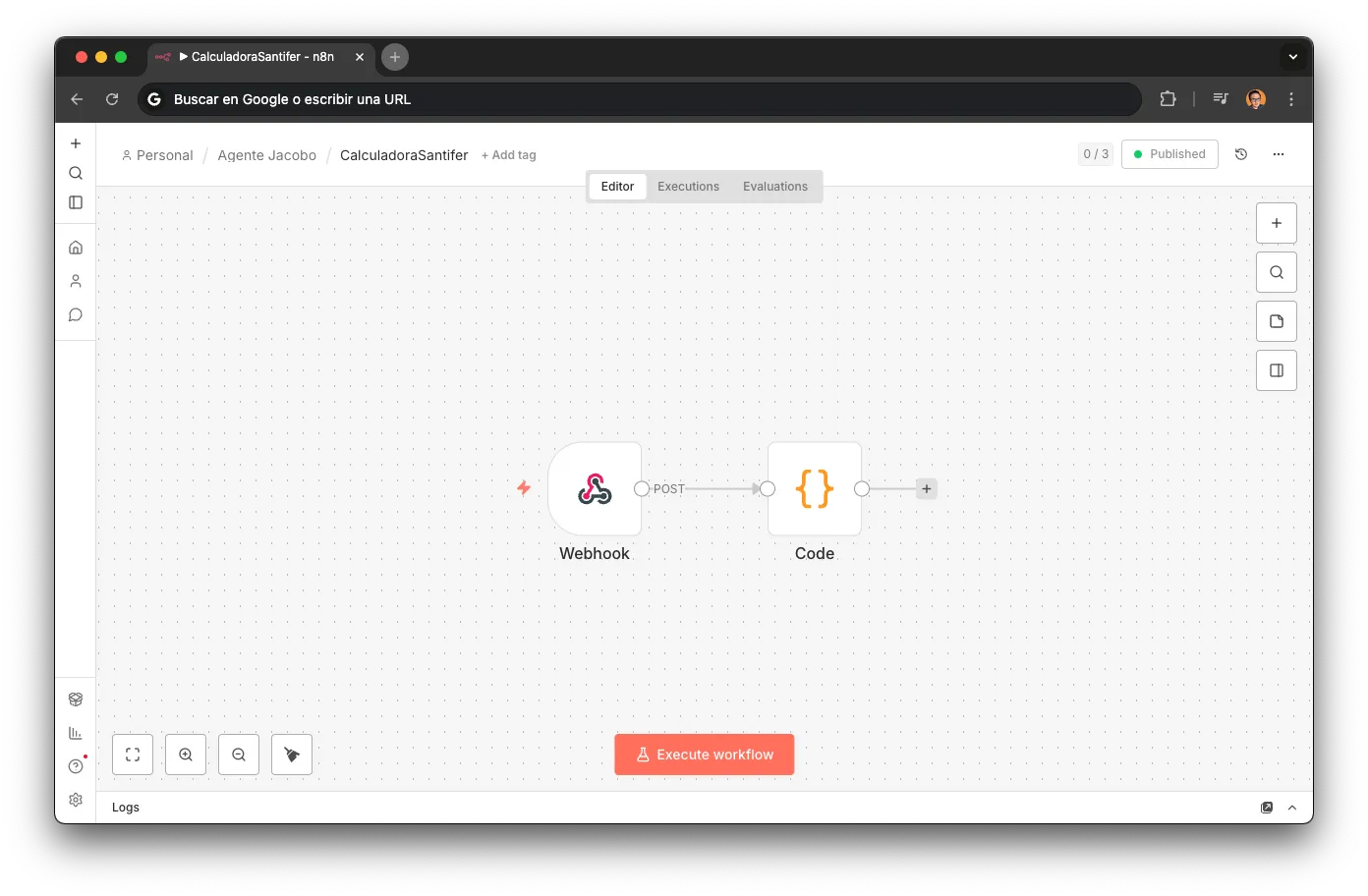
Sorts prices high-to-low: the most expensive repair gets no discount
Position-based discount: ≤€50 → €15 off, ≤€100 → €20 off, >€100 → €25 off
Returns formatted summary: price without discount, discount applied, final price
The customer instantly sees how much they save by bundling repairs in one visit
const precios = item.json.body.precios; // Validaciones básicas if (!Array.isArray(precios) || precios.length < 2) { throw new Error('Debes enviar un array "precios" con al menos 2 números.'); }
Defensive validation
The sub-agent doesn't trust the router: validates the array exists and has at least 2 prices. If the LLM sent malformed data, it fails fast with a descriptive error instead of returning NaN.
// 1) Ordenamos de mayor a menor const ordenados = [...precios].sort((a, b) => b - a); // 2) Calculamos descuento por posición (el primero no tiene) const descuentos = ordenados.map((precio, idx) => { if (idx === 0) return 0; // sin descuento para el más caro if (precio <= 50) return 15; if (precio <= 100) return 20; return 25; // >100 € });
Business rules as code, not as prompt
Discounts live in a Code node, not a prompt. This guarantees determinism: a €189 screen + €45 battery always yields the exact same discount. Zero hallucinations possible.
// 3) Totales const totalSinDescuento = ordenados.reduce((s, p) => s + p, 0); const descuentoTotal = descuentos.reduce((s, d) => s + d, 0); const totalConDescuento = totalSinDescuento - descuentoTotal; // 4) Preparar respuesta const resumen = `Presupuesto total sin descuento: ${totalSinDescuento.toFixed(2)} € Descuento aplicado: ${descuentoTotal.toFixed(2)} € Presupuesto reparándolo todo junto: ${totalConDescuento.toFixed(2)} €`;
Pre-formatted response for the router
The plain-text summary goes to the router and is passed directly to the customer. The LLM doesn't rephrase: it copies the text verbatim. The price the customer sees is exactly what the code calculated.
HITL Handoff: Human Escalation
The system's escape valve. When Jacobo detects it can't resolve (frustrated customer, complex case, out-of-scope request), it escalates to a human via Slack with full context.
Webhook → Slack (#chat) → Respond to Webhook

Posts to #chat channel with 🤖 emoji as avatar
Message includes: conversation summary, detected intent, and customer history
Deep-link directly to the WATI conversation: the human opens it with full context already loaded
Jacobo confirms to the customer that a human will reach out, without cutting the conversation
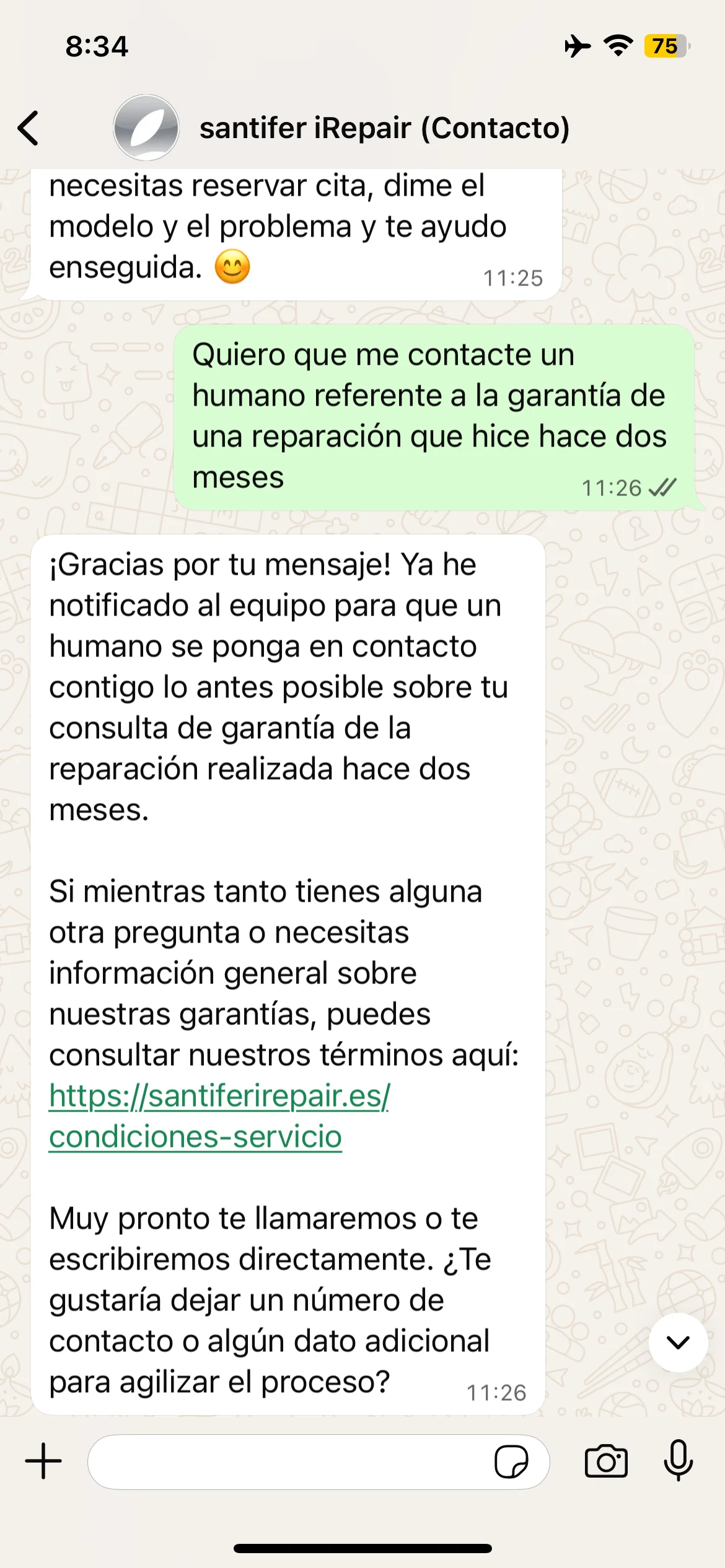
HITL: warranty claim → immediate escalation to human team

#chat Slack channel: HITL escalation notification with customer context
When Jacobo escalates to a human, a message arrives in the #chat Slack channel with the full conversation context
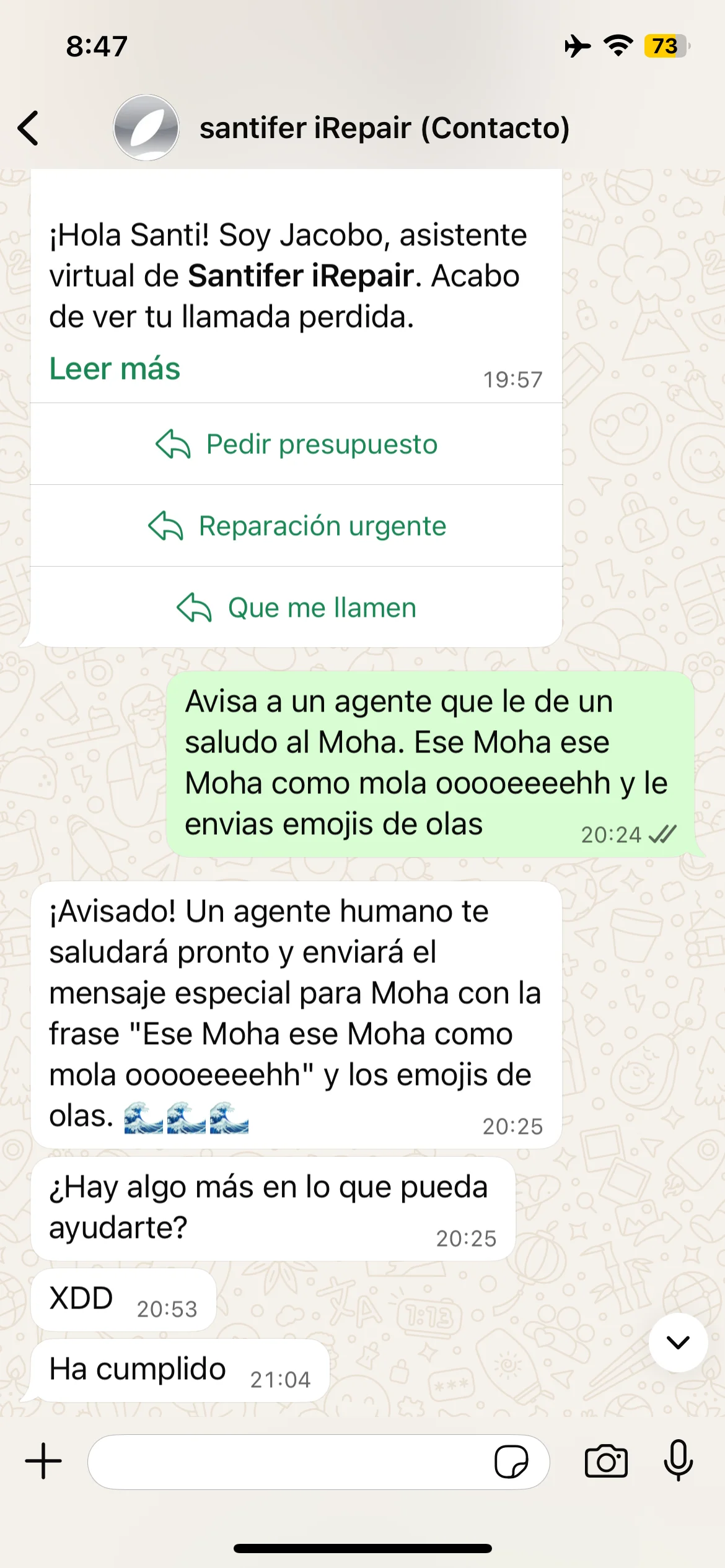
Edge case: "Tell an agent to greet Moha" → Jacobo escalates with wave emojis → real agent confirms "Done"

Guardrail: "Order 100 batteries" → rejection + profanity → automatic escalation to human
"Borrar memoria" → reset + "3,2,1..." + fake emergency → Jacobo redirects to 112 and keeps composure
Real edge cases: absurd request, bulk order rejected, frustration escalation and fake emergency response with 112 redirect
EnviarMensajeWati: Cross-Channel
The bridge between channels. When the customer is on the phone with Jacobo (ElevenLabs), this workflow sends links and confirmations via WhatsApp in parallel. The customer gets the info in writing while still talking.
Webhook → HTTP Request (WATI API) → Respond to Webhook
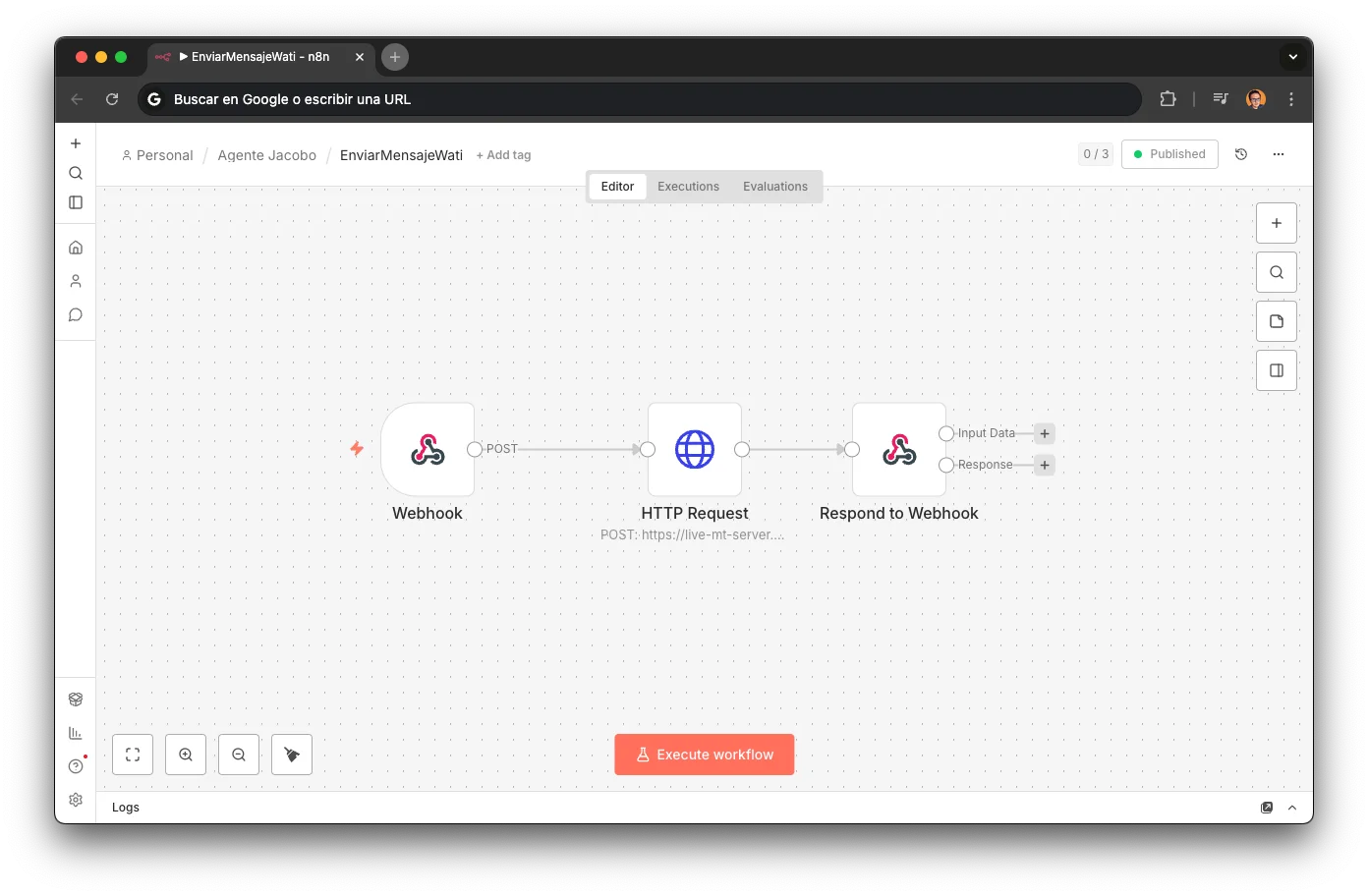
Sends "urlreparacion2" template with the personalized appointment URL
Enables the voice agent to say "I just sent you the link on WhatsApp"
The customer doesn't need to write anything down: when they hang up, the info is already on their phone
Results#
Production metrics after 6 months live:


~90%
Self-service
Inquiries resolved without human intervention
24/7
Availability
No longer limited to store hours
<30s
Response time
Vs. minutes when it depended on a person
<€200
Monthly cost
Total infrastructure (n8n + WATI + Aircall + LLMs)
Before vs After
| Area | Before | After |
|---|---|---|
| Price/stock inquiries | ~15 interruptions/day to the technician | Jacobo responds with real Airtable data in <30s |
| Appointment booking | Manual via phone, frequent scheduling errors | Automatic via YouCanBookMe, parts auto-reserved |
| After hours | Lost inquiries, customers going to competitors | Jacobo handles 24/7 via WhatsApp and landline |
| Human escalations | Human started from scratch, repeating questions | Handoff with full context, resolution in seconds |
| Customer support cost | Part-time employee ~€800-1,000/mo | <€200/mo total infrastructure |
The real return isn't just the cost saving. It's the technician who's actually repairing phones instead of answering them, and the appointment that used to fall through the cracks at 10pm — now confirmed automatically.
Industry benchmark: enterprise contact centers average 20-30% AI resolution rate (Gartner, 2025 AI Customer Service Report). The most advanced virtual assistants achieve 15% (Gartner, 2025 Hype Cycle for Customer Service & Support Technologies). Jacobo hit ~90% in a specialized domain. The difference: domain-specific sub-agents with real-time data access vs generic chatbots.
Jacobo is still running 24/7 under new ownership since September 2025. The buyer acquired it operating — the best proof of a system: it runs without its creator. The architecture patterns documented here are the same ones I'd bring to your team.
The same Airtable data generated 4,700+ SEO pages
The inventory Jacobo queries in real time also feeds a programmatic SEO system: 4,730 landing pages with real prices, repair photos, and verified reviews.
Looking for someone to build this for your company?
Jacobo handles appointments, queries real inventory, and escalates with context, all in under 30 seconds. The sub-agent architecture, tool calling, and HITL patterns apply directly to travel, fintech, healthcare, or e-commerce.
Architecture Decision Records (ADRs)#
The decisions that shaped the system — and why I made each one:
Multi-model (GPT-4.1 + MiniMax + GPT-4.1 mini) vs single LLM
Each component with the right model: GPT-4.1 for the main router and voice agent (precise tool calling), GPT-4.1 mini for quotes (structured output), MiniMax M2.5 for appointments (fast and cheap for parsing time preferences). OpenRouter as gateway allows switching between models without rewriting workflows.
OpenRouter as model-agnostic gateway
Switch between models without rewriting workflows, automatic fallback if a model is down. We evaluated Claude, GPT-4, MiniMax: chose by use case, not by brand.
n8n vs Make for orchestration
Each sub-agent is an independent workflow with its own webhook. Make doesn't allow this modularity. n8n supports LangChain agent patterns, memory management and native tool calling.
Sub-agents as webhook microservices
Decoupled, individually testable, independently deployable. The same sub-agent serves WhatsApp (via n8n) and phone (via ElevenLabs) without duplicating code.
Airtable as brain vs database
The complete Business OS already existed in Airtable (12 bases, 2,100+ fields). Single source of truth for stock, prices and customer history. Build on what already exists, don't duplicate.
Memory window: 20 messages per session
Balance between context and token cost. Sufficient for a repair conversation (95% resolve in <10 messages). Keyed by phone number for continuity.
Think tool for internal reasoning
Explicit reasoning before multi-tool chains. Reduces errors because the LLM plans the sequence (check price → verify stock → offer appointment) before executing.
HITL via Slack with escalation reason
The LLM generates the escalation reason and includes it in the Slack message: why human intervention is needed, what it has tried, and what the customer needs. Works identically from WhatsApp (deep-link to WATI) and phone calls. The human knows why they're needed before opening the conversation.
WhatsApp first, voice second
70% of volume came through WhatsApp. Starting there maximized impact before expanding to voice. Voice (ElevenLabs + Aircall) reused existing sub-agents without duplicating logic.
Dual-orchestrator with shared sub-agents
n8n for WhatsApp/web, ElevenLabs for voice. Sub-agents are platform-agnostic webhooks. Reusable by any orchestrator without duplicating logic. A real microservices pattern.
ElevenLabs as "teammate" on Aircall
Jacobo integrated into PBX with routing rules: picks up on overflow or after hours. The customer calls a landline, transparent experience. eleven_flash_v2_5 with temp 0.0 for maximum consistency.
Aircall → Twilio → ElevenLabs (and the latency trade-off)
The Aircall PBX → Twilio (phone bridge) → ElevenLabs chain worked, but each hop added latency: ~950-1,500ms mouth-to-ear. Twilio uses G.711 at 8kHz when STT models are optimized for 16kHz, forcing resampling with accuracy loss. Today I'd choose a direct SIP trunk (Telnyx offers G.722 wideband at native 16kHz and co-located infrastructure with sub-200ms RTT) eliminating the intermediate hop. The platform-agnostic sub-agent design would make this migration straightforward: only the transport changes, not the logic.
Platform Evolution#
Jacobo wasn't a weekend hack. It was the inevitable result of 5 years building a proper Business OS underneath.

2019-2024
Business OS as foundation
Five years building a complete business operating system in Airtable: 12 bases, 2,100+ fields, real-time inventory, CRM with full customer history. Without this clean data layer, any AI agent would just be a generic chatbot making things up.
Jan 2025
Training and deliberate design
Before writing a line of code, I studied AI agent architectures. I knew I needed tool calling, that Airtable was the SSOT, and that the same backend had to serve both voice and chat.
Feb 2025
First test version (monolithic)
Tried the single-prompt-with-everything approach. Confirmed what I suspected: a monolithic prompt doesn't scale across multiple domains. This test validated the sub-agent-as-webhooks architecture, platform-agnostic by design.
Feb 2025
Definitive multi-agent version
My first AI agent, shipped to production in under a month. Full sub-agent architecture: each domain in its own workflow with independent webhook, central router with tool calling, multi-model per use case. The speed came from the Business OS already running underneath. Built alongside all other business responsibilities.
Mar 2025
Voice channel (Aircall + Twilio + ElevenLabs)
Jacobo as a teammate on the Aircall phone system, connected via Twilio to ElevenLabs. Reused existing sub-agents without duplicating logic. Validation of the platform-agnostic design: the webhooks served a second orchestrator without touching a single line.
Sep 2025
Going-concern sale
Jacobo has been running 24/7 since launch. It was part of the business sale as an operational asset: the buyer acquired it operating. Five years of clean architecture made this exit possible.
Jacobo wasn't an experiment.
16 years building a business with my own hands.
Systematize it until it runs without me.
Jacobo was the piece that closed the loop.
I sold the business as a going concern.
The systems I built still run today — under new ownership.
Business OS — The System Behind Jacobo
Jacobo was built on top of the Business OS I designed over 5 years — read the full case study →
First Jacobo test: basic test message

Loyalty iteration: improved agent responses

Diamond template: automated loyalty program
Jacobo's first moments of life: endpoint testing, loyalty copy iteration and the final CRM template
Lessons Learned#
Sub-agents > monolithic prompt.
I tested a single prompt with full context during design and confirmed it doesn't scale across domains. The sub-agent architecture was deliberate from the start: each piece testable, iterable, and independent. Changing discounts can't break appointments. Microservices logic, applied to AI agents.
HITL isn't a fallback, it's a feature.
A well-implemented handoff builds more trust than a bot that tries to handle everything. Customers value a system that knows when they need a person. The trick: the human picks up with full context, not from scratch.
The CRM is the agent's brain, not the LLM.
Jacobo isn't smart because of the LLM. It's smart because it queries real prices, stock, and customer history in Airtable. Strip away that data and it's just another chatbot making things up.
Start with the highest-volume channel.
WhatsApp carried 70% of volume. Starting there maximized impact. When voice came later, the sub-agents were already battle-tested. We just plugged in a new orchestrator.
Choose models by use case, not by brand.
GPT-4.1 for router and voice (precise tool calling), GPT-4.1 mini for quotes (structured output), MiniMax M2.5 for appointments (fast and cheap). OpenRouter as gateway lets you swap models without rewriting. More FDE than "I use X for everything."
The Think tool prevents errors in multi-tool chains.
Before checking price → verifying stock → offering an appointment, the agent makes its plan explicit. One reasoning step cuts errors in the chain. Rubber duck debugging, but for the agent itself.
What I'd Do Differently#
Jacobo ran in production for months. Here's what I'd change:
Structured evaluation from day 1
I bolted on evals after the system was already in production. Starting over, I'd define response quality metrics, intent classification accuracy, and HITL rate before v1. Retrofitting observability costs more than building it in from day one.
Direct SIP trunk instead of Aircall → Twilio → ElevenLabs
The 3-hop chain added ~950-1,500ms mouth-to-ear latency and forced G.711 (8kHz) → 16kHz resampling. A Telnyx SIP trunk direct to ElevenLabs would give native G.722 wideband and sub-200ms RTT. I went with the long chain because Aircall was already contracted. Today I'd prioritize latency over convenience.
Vector store for memory instead of raw WATI fetch
Fetching 80 messages from WATI works, but doesn't scale for customers with long histories and can't do semantic search. A vector store (Pinecone, Qdrant) with conversation embeddings would unlock "remember when you brought the iPhone 12" without loading the full thread.
Transferable Enterprise Patterns#
Jacobo was built for an SMB. The patterns scale. Here's what I shipped vs. what I'd add at enterprise scale:
| Pattern | What I built | Enterprise |
|---|---|---|
| Sub-agent routing with tool calling | Router + 7 webhook sub-agents with intent classification and delegation | Add circuit breakers, retry policies and per-sub-agent model fallback |
| Multi-model orchestration | GPT-4.1 (router/voice) + GPT-4.1 mini (quotes) + MiniMax (appointments) via OpenRouter | A/B testing models per sub-agent, canary deployments for new prompt versions |
| HITL framework | Escalation via Slack with full context and deep-link to the conversation | Queue management, SLAs per customer tier, escalation reason analytics |
| Platform-agnostic sub-agents | Shared webhooks between n8n (WhatsApp) and ElevenLabs (voice) | API gateway, rate limiting, authentication, endpoint versioning |
| Observability | n8n logs + Slack alerts | Langfuse/Datadog for traces, latency and per-conversation cost tracking |
| Voice infrastructure | Aircall → Twilio → ElevenLabs: functional, but each hop adds latency (~950-1,500ms mouth-to-ear). Twilio uses G.711 at 8kHz, requiring resampling to 16kHz for STT models, degrading accuracy | Direct SIP trunk (Telnyx/Plivo) → ElevenLabs via SIP, eliminating the Twilio hop. Telnyx offers G.722 wideband at native 16kHz (no resampling) and co-located infrastructure (GPU + telephony in the same PoP) with sub-200ms RTT. For apps/web: direct WebRTC (Opus 16-48kHz) via LiveKit, no PSTN, achieving 300-600ms mouth-to-ear |
Industry applicability
Travel (Hopper, Booking)
Sub-agents for flights, hotels, insurance. HITL for complex changes. Tool calling against availability APIs.
Fintech
Sub-agents for transactions, balance queries, support. Stock-aware routing → balance-aware routing.
Healthcare
Sub-agents for appointments, results, triage. HITL as critical feature for specialist referral.
E-commerce
Sub-agents for tracking, returns, recommendations. Same inventory lookup and booking patterns.
Voice AI Platforms
Conversational agent orchestration with optimized latency. The cross-channel (voice → text) and HITL patterns apply directly to any voice platform.
Data/AI Platforms
Tool calling against internal APIs, intent-based sub-agent routing, memory management. The same architecture scales to any agent orchestrator.
These patterns scale. Production-ready for enterprise.
Jacobo handles appointments, queries real inventory, and escalates with context, all in under 30 seconds. The sub-agent architecture, tool calling, and HITL patterns apply directly to travel, fintech, healthcare, or e-commerce.
Run It Yourself#
These are the actual workflows that have been running in production for 2 years. Sanitized, documented, ready to import into n8n. If you build something with them, I'd love to see it.
Jacobo Chatbot V2
Central Router
The brain of the WhatsApp channel. Classifies intent, picks the right sub-agent, maintains a 20-message memory window.
subagenteCitas
Appointment Booking
Turns "tomorrow morning" into a confirmed appointment. Parses natural language time preferences.
Presupuesto Modelo
Quote Agent
Looks up exact model + repair in Airtable, returns real price with stock status.
hacerPedido
Order Creation
Creates repair orders in Airtable when parts are out of stock.
CalculadoraSantifer
Discount Calculator
Pure business logic. Calculates combo discounts when customers bundle multiple repairs.
contactarAgenteHumano
HITL Handoff
The escape valve. Escalates to human via Slack with a deep-link to the conversation.
EnviarMensajeWati
WhatsApp Sender
Cross-channel bridge: the voice agent sends WhatsApp messages via the WATI API.
All workflows live on GitHub — fork, star, or download directly.
How to import into n8n
Open your n8n instance and go to Workflows
Click "..." → "Import from file"
Select any .json file from the download
Update credentials (API keys, webhooks) with your own values
FAQ#
How much does it cost to build an AI agent for WhatsApp?
The tools (n8n cloud, WATI, Aircall, LLMs via OpenRouter) cost less than €200/month total. The main cost is the time to design and develop the architecture. For a business this size, it's a fraction of the cost of a part-time customer service employee.
What happens if the AI gets a price wrong?
Prices don't come from the LLM: they come from Airtable. Jacobo queries inventory in real time. If a price changes in Airtable, Jacobo gives the correct price automatically. No hallucination possible on structured data.
How does the voice agent on a landline work?
Jacobo is integrated into the Aircall PBX as another "teammate". It picks up when no one else can or after hours. The customer calls a landline and talks to Jacobo with natural voice (ElevenLabs). It uses the same sub-agent webhooks as WhatsApp: same logic, different interface.
Why n8n and not LangChain/LangGraph directly?
n8n lets each sub-agent be a visual workflow with its own webhook, testable with an HTTP call. The maintenance barrier is lower than a Python repo. For this system's complexity (7 workflows, ~80 nodes), n8n's visualization is an advantage, not a limitation.
How long did it take to build Jacobo?
Less than a month from design to production. And it was my first AI agent, built in parallel with all other business responsibilities. The speed came from the Business OS already existing: clean, accessible data in Airtable, real-time inventory, CRM with history. Without that 5-year foundation, it would have been much slower. Jacobo was the inevitable consequence of a robust business operating system.
Can you build something like this for my company?
Yes. Jacobo's patterns (sub-agents, tool calling, HITL, cross-channel) are industry-agnostic. What changes is the data and integrations, not the architecture. If your business has structured data and repetitive processes, I can design a similar system.
Is Jacobo still running?
Yes. I sold the business in 2025 and Jacobo was sold with it — it's still in production serving customers today. That's the best validation possible: the buyer kept the system because it works.
How do these patterns apply to an enterprise team?
Jacobo was built for an SMB, but the patterns (sub-agents, tool calling, HITL, cross-channel) are enterprise-grade. At scale you add: circuit breakers, A/B testing per sub-agent, queue management for HITL handoff, per-sub-agent observability. What does not change: the architecture.
You liked the workflows. Imagine what I can do with yours.