

~15 interrupciones al día. Cada una, una reparación parada. Cada WhatsApp sin responder, un cliente que se iba a la competencia. Construí un agente IA que gestiona ambos canales: ~90% de las interacciones, 24/7, por menos de 200€/mes.
No un chatbot con respuestas enlatadas. Un agente que consulta precios reales, verifica stock, gestiona citas y sabe cuándo escalar a un humano con todo el contexto. Así nació Jacobo. En este artículo comparto la arquitectura completa y los workflows de producción para que puedas replicarlo.
El Problema#
Con +30.000 reparaciones completadas y múltiples canales de atención (teléfono, WhatsApp, web), el cuello de botella era claro:
El 80% de las consultas eran repetitivas: precios, citas, estado de reparación
Cada consulta interrumpía al técnico que estaba reparando dispositivos
Los tiempos de respuesta variaban según la carga del día
La información estaba dispersa entre Airtable, el calendario y el inventario
El horario de atención limitaba la disponibilidad a horas de tienda
Un empleado a tiempo parcial dedicado a atención al cliente costaba más de lo que el negocio podía justificar
Los clientes llegaban por dos canales principales (WhatsApp y teléfono fijo) y la solución tenía que cubrir ambos con la misma lógica, no duplicar el trabajo

Sabía tres cosas desde el principio: Airtable era el cerebro (el Business OS ya llevaba años como SSOT), necesitaba tool calling real contra esos datos, y el agente tenía que ser multimodal (voz + chat) compartiendo los mismos recursos. La pregunta era qué herramienta de orquestación usar:
Tidio / Intercom
Chatbots generalistas con árboles de decisión. No pueden consultar stock en tiempo real ni calcular precios dinámicos contra Airtable. Para un negocio de reparaciones, son poco más que un FAQ interactivo.
ManyChat (WhatsApp)
Bueno para flujos de marketing, pero sin capacidad de tool calling contra un ERP existente. No puede verificar stock, crear órdenes de trabajo ni hacer handoff con contexto.
Solución vertical (RepairDesk chat)
Ningún SaaS de reparaciones ofrecía un agente conversacional con lenguaje natural y tool calling contra datos en tiempo real. Los que tenían chat eran básicamente formularios disfrazados.
n8n era la elección natural: orquestación de workflows con webhooks, soporte nativo para agentes con LLMs y tool calling, y la capacidad de que cada sub-agente fuera un workflow independiente testeable. Todo conectado al Business OS que ya existía en Airtable.
Este POS fue el primer problema que resolví
Antes de construir Jacobo, reemplacé este sistema legacy por un ERP custom sobre Airtable. Esa base de datos es la que Jacobo consulta hoy.
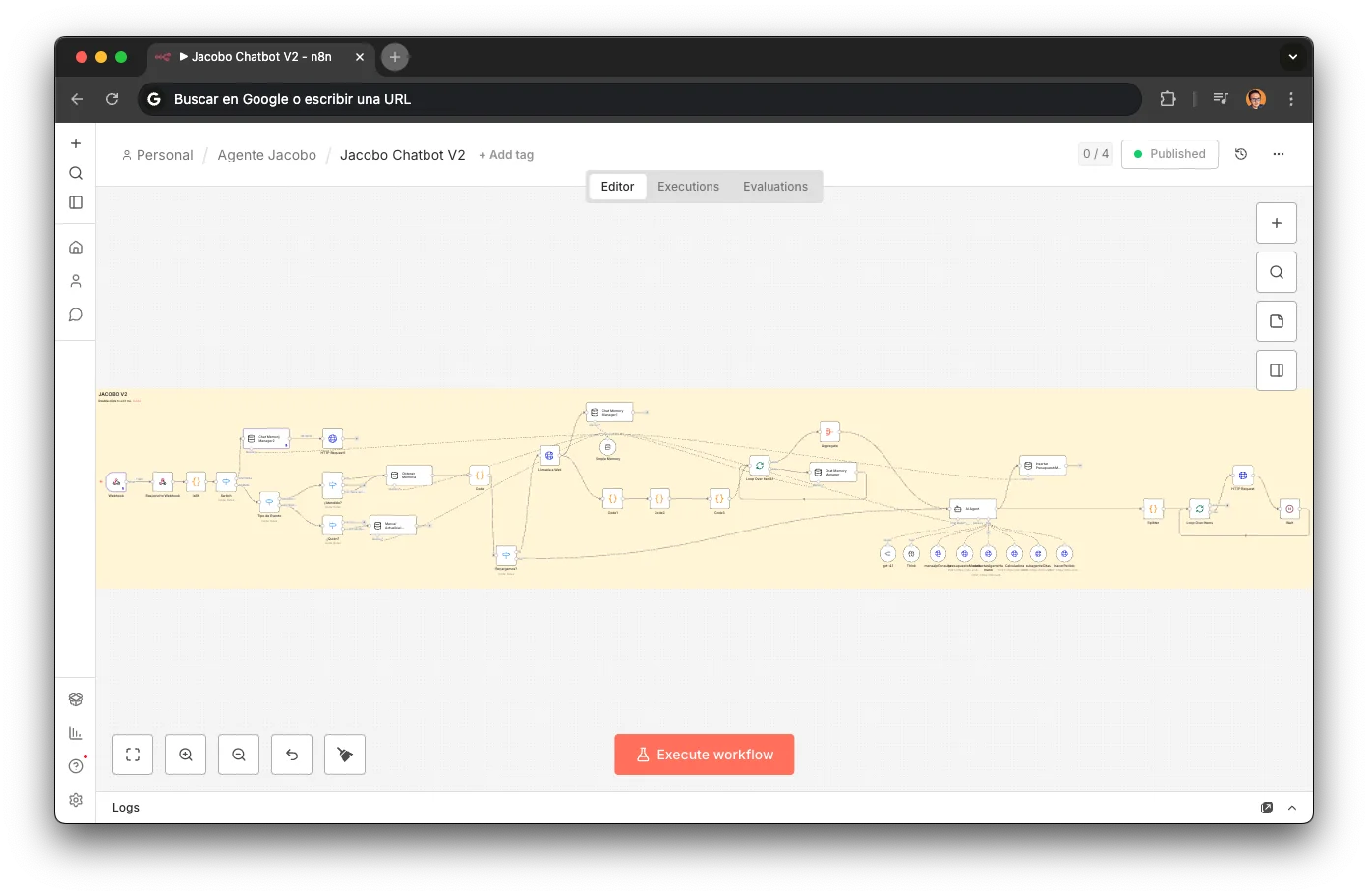
La Arquitectura#
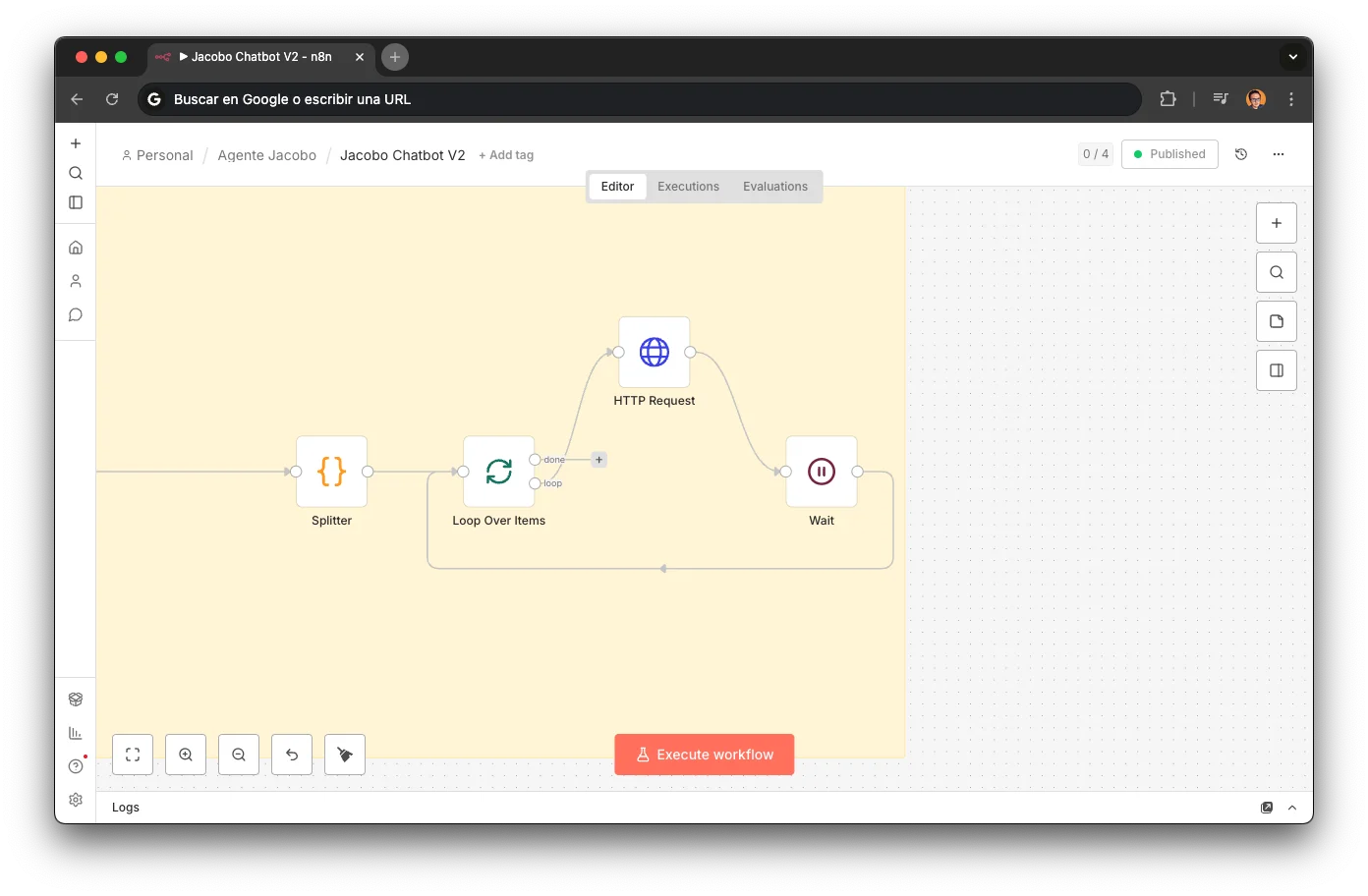
Jacobo no es un chatbot con un prompt largo. Es un sistema de sub-agentes especializados, cada uno desplegado como un webhook independiente en n8n, orquestados mediante tool calling desde un router central. Cada workflow que ves en este artículo es descargable: podrás importarlo directamente en n8n.
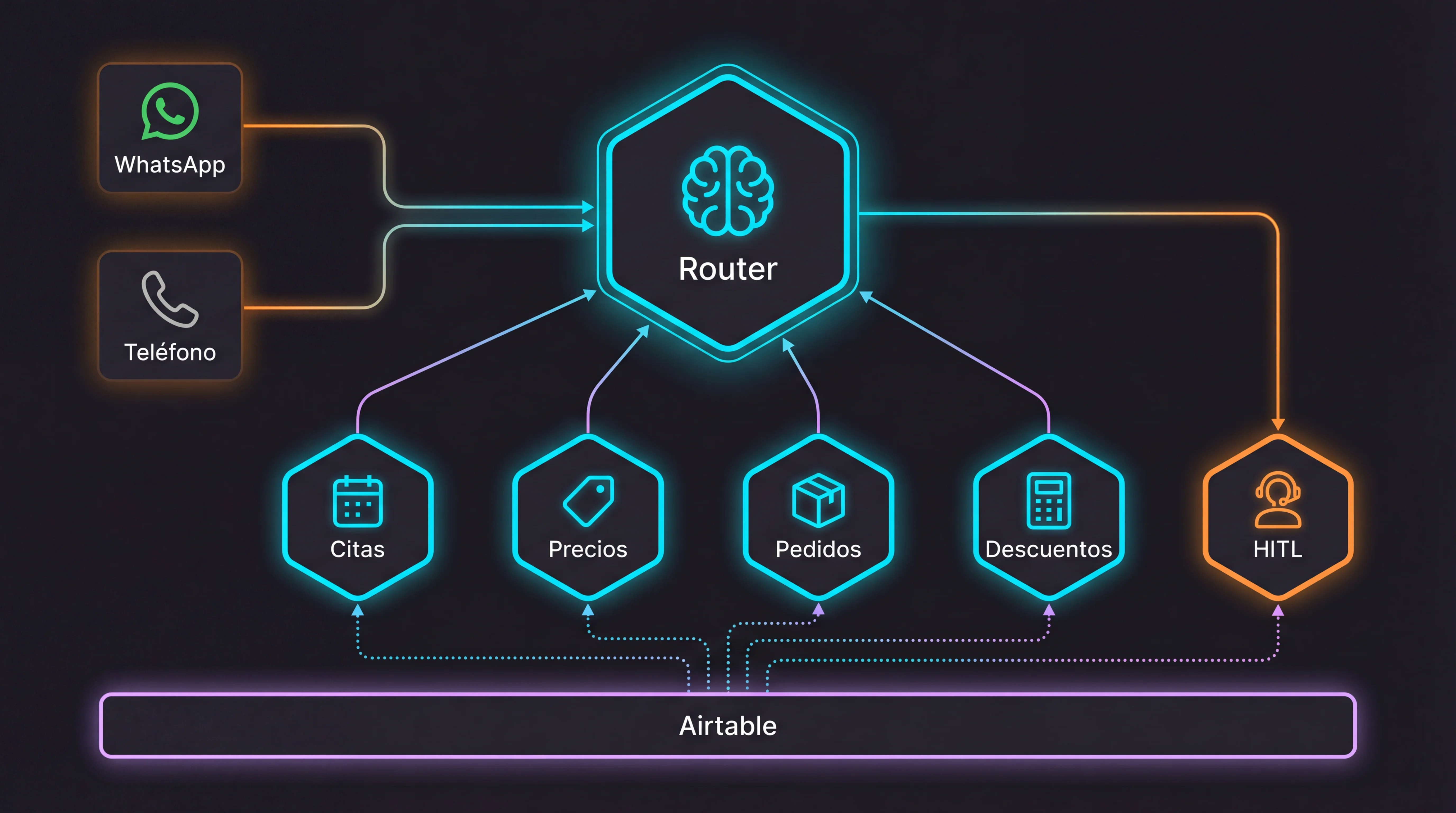
Stack
Jacobo se apoya en 8 servicios que cubren desde la entrada del cliente hasta el escalado humano. Cada uno tiene un rol único; ninguno es reemplazable sin cambiar la arquitectura.
WATI
WhatsApp Business API: canal principal de entrada
Aircall
Cloud PBX: Jacobo como compañero en la centralita
n8n
Orquestación de workflows y sub-agentes (7 workflows, ~80 nodos)
OpenRouter
Gateway model-agnostic para LLMs (MiniMax M2.5 + GPT-4.1)
ElevenLabs
Agente de voz conversacional (eleven_flash_v2_5, temp 0.0)
Airtable
CRM, inventario, historial de clientes (source of truth)
YouCanBookMe
Gestión de citas y disponibilidad
Slack
Canal de escalado HITL (#chat)
¿Por qué sub-agentes en vez de un prompt monolítico?
Testabilidad
Cada sub-agente tiene su propio webhook. Puedo probarlo de forma aislada con una llamada HTTP, sin montar el sistema completo.
Evolución independiente
Un cambio en la lógica de descuentos no toca las citas. Puedo iterar un dominio sin riesgo de romper otro.
Cost efficiency
No todos los sub-agentes necesitan el mismo modelo. Citas usa MiniMax M2.5 (rápido y barato para parsear preferencias temporales). Presupuestos usa GPT-4.1 mini (precisión en structured output). Cada sub-agente con el modelo justo para su tarea.
Platform-agnostic
Los sub-agentes son webhooks. No saben si los llama n8n (WhatsApp) o ElevenLabs (voz). Reutilizables por cualquier orquestador sin duplicar lógica.
4 Agentes y 3 Tools Para Gobernarlos a Todos
4 agentes con LLM propio toman decisiones. 3 tools sin LLM ejecutan lógica de negocio pura. Todo conectado por webhooks.
Router Principal (n8n)
El cerebro del canal WhatsApp. Clasifica el intent, elige el sub-agente correcto y mantiene el contexto con una ventana de memoria de 20 mensajes.
GPT-4.1 vía OpenRouter · 37 nodos
Patrón LangChain Agent con 7 tools como endpoints HTTP
Think tool para razonar antes de cadenas complejas
Pseudo-streaming: parte la respuesta en frases y las envía una a una por WhatsApp
Voice Router (ElevenLabs)
El cerebro del canal de voz. Recibe llamadas vía Aircall → Twilio → ElevenLabs Conversational AI, con su propio system prompt optimizado para conversación hablada.
ElevenLabs Conversational AI · GPT-4o
Mismos sub-agentes que el Router Principal, conectados como tools HTTP
RAG nativo out-of-the-box: knowledge base con catálogo de reparaciones, precios y FAQs
Latencia optimizada para voz: respuestas cortas y directas
Detección de horario comercial para transferir a humano fuera de horas
Sub-agente Citas
Convierte "mañana por la mañana" en una cita confirmada. Parsea preferencias temporales en lenguaje natural, consulta YouCanBookMe y envía template de confirmación por WhatsApp.
MiniMax M2.5 vía OpenRouter · 18 nodos
15 reglas de parseo temporal: desde "después de comer" hasta "cualquier día menos lunes"
El sub-agente más sofisticado del sistema
Sub-agente Presupuestos
Toda consulta de precio pasa por aquí. Busca modelo y reparación exactos en Airtable, devuelve precio real con estado de stock y decide el siguiente paso.
GPT-4.1 mini vía OpenRouter · 11 nodos
¿Hay stock? → ofrece cita
¿Sin stock? → ofrece pedido
¿No existe? → enlace al formulario de presupuesto
Tools (sin LLM)
Pedidos
Crea órdenes de reparación en Airtable cuando la pieza no tiene stock.
3 nodos: webhook → crear registro → responder
Simple por diseño: toda la validación ocurrió en Presupuestos
Calculadora de Descuentos
Lógica pura de negocio, sin LLM. Calcula descuentos combo cuando el cliente agrupa varias reparaciones.
3 nodos · sin LLM
Batería + pantalla + cristal trasero = precio multi-reparación automático
Las reglas de descuento viven aquí, no repartidas entre prompts
HITL Handoff
La válvula de escape. Escala a humano vía Slack con deep-link directo a la conversación en WATI.
5 nodos · publica en #chat
Incluye resumen de conversación, intent detectado e historial del cliente
El humano tiene contexto completo antes de abrir el chat
Memoria Conversacional
Jacobo no tiene estado propio entre mensajes. Cada vez que llega un mensaje nuevo, reconstruye el contexto leyendo el historial real de la conversación desde WATI:
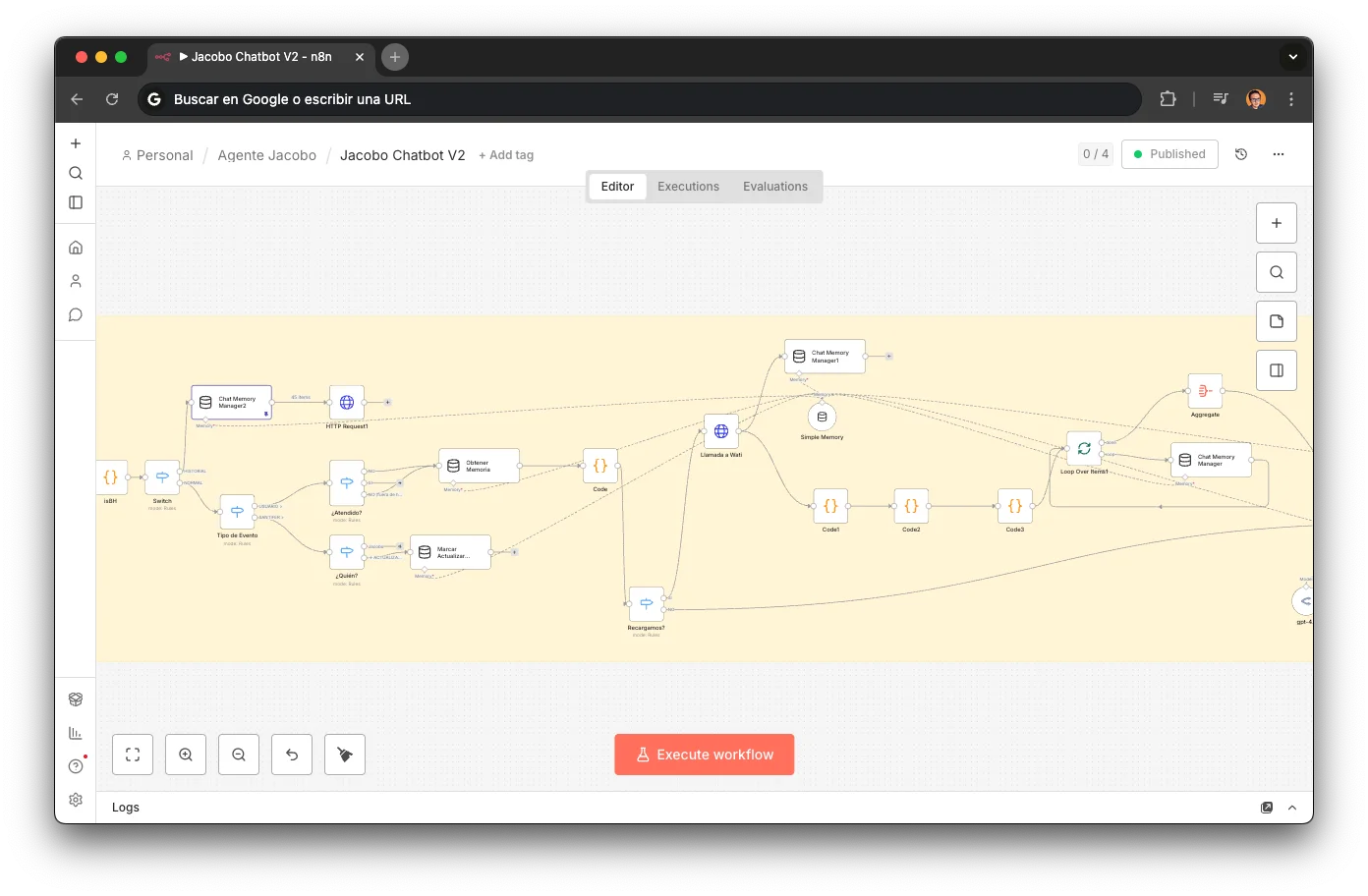
¿Atendido?
Un switch comprueba si ya existe sesión activa para este número. Si no, dispara la recarga de memoria.
Fetch de WATI
Llamada HTTP a getMessages/{waId} con pageSize=80. Recupera los últimos 80 mensajes de la conversación completa: mensajes del cliente, respuestas de Jacobo, templates, broadcasts y mensajes de operadores humanos.
Parseo en 3 fases
Tres nodos de código transforman los eventos WATI en pares {human, ai} compatibles con LangChain. Filtra broadcasts, templates de confirmación y eventos de sistema. Un flag __reloadFlag__ permite resetear la memoria manualmente.
Buffer Window
Los últimos 20 mensajes se cargan en el LangChain BufferWindow, keyed por número de teléfono. El agente "recuerda" conversaciones previas: si ayer confirmaste una cita, hoy Jacobo lo sabe.
Esto es lo que permite que Jacobo continúe conversaciones interrumpidas, reconozca clientes recurrentes y sepa que un humano intervino antes en esa conversación.
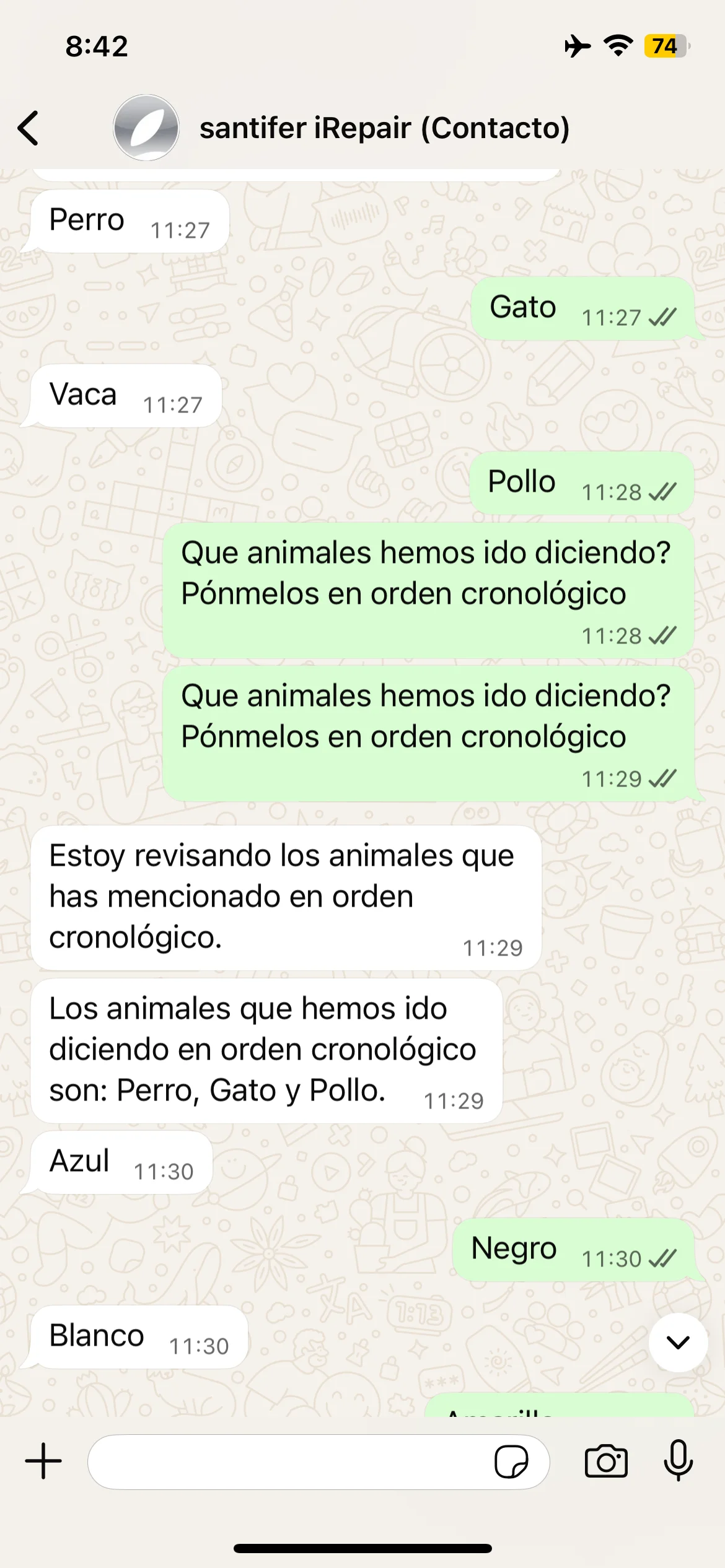
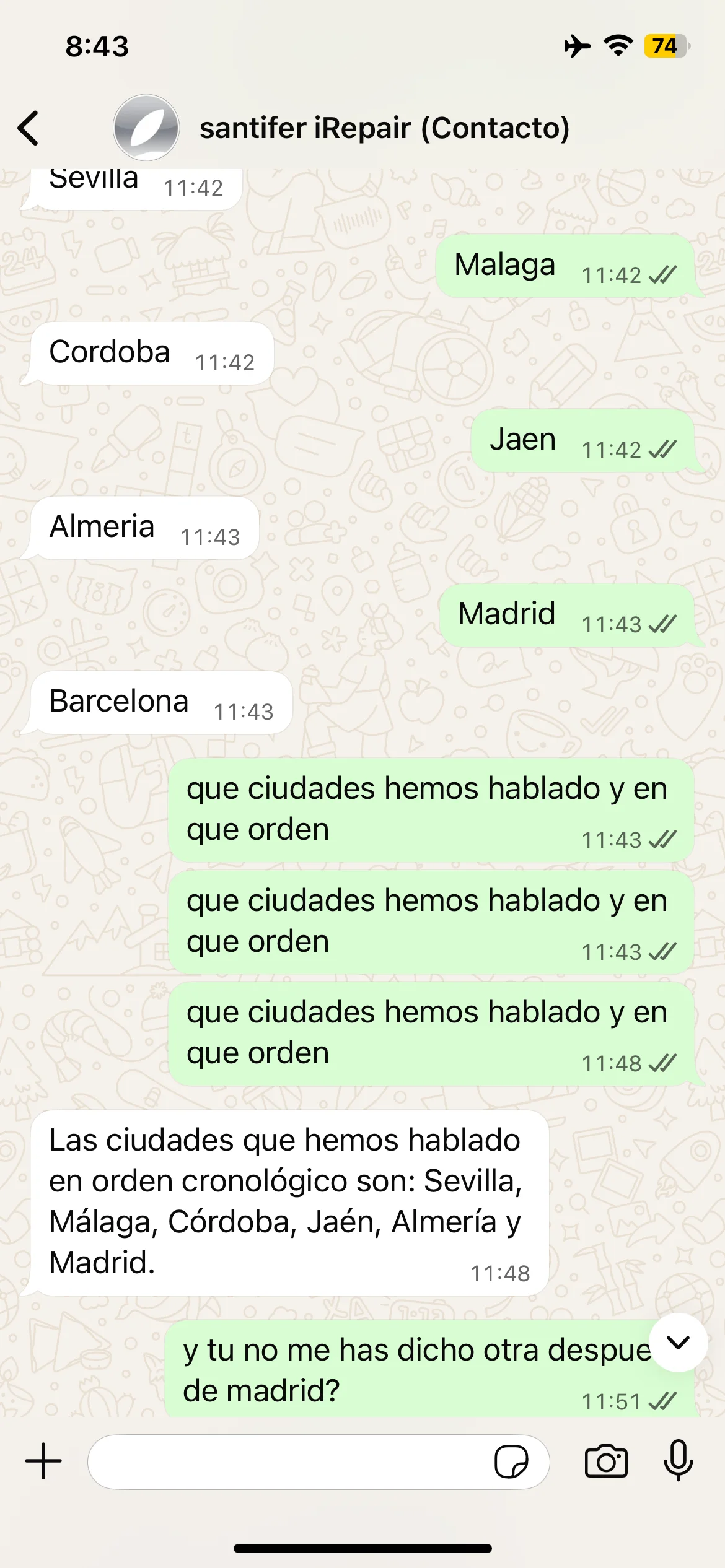
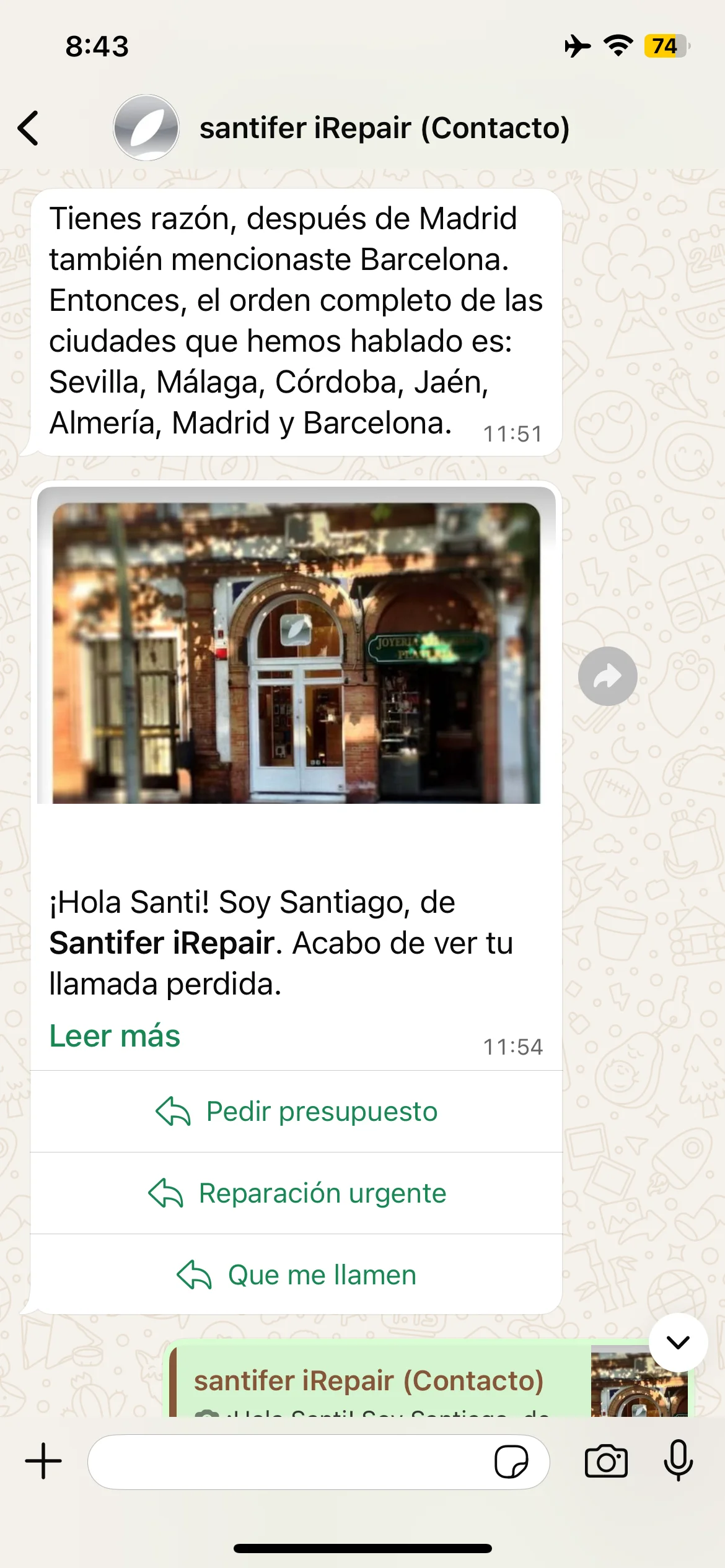
Tests de memoria episódica: animales, ciudades y autocorrección cuando Jacobo olvida Barcelona
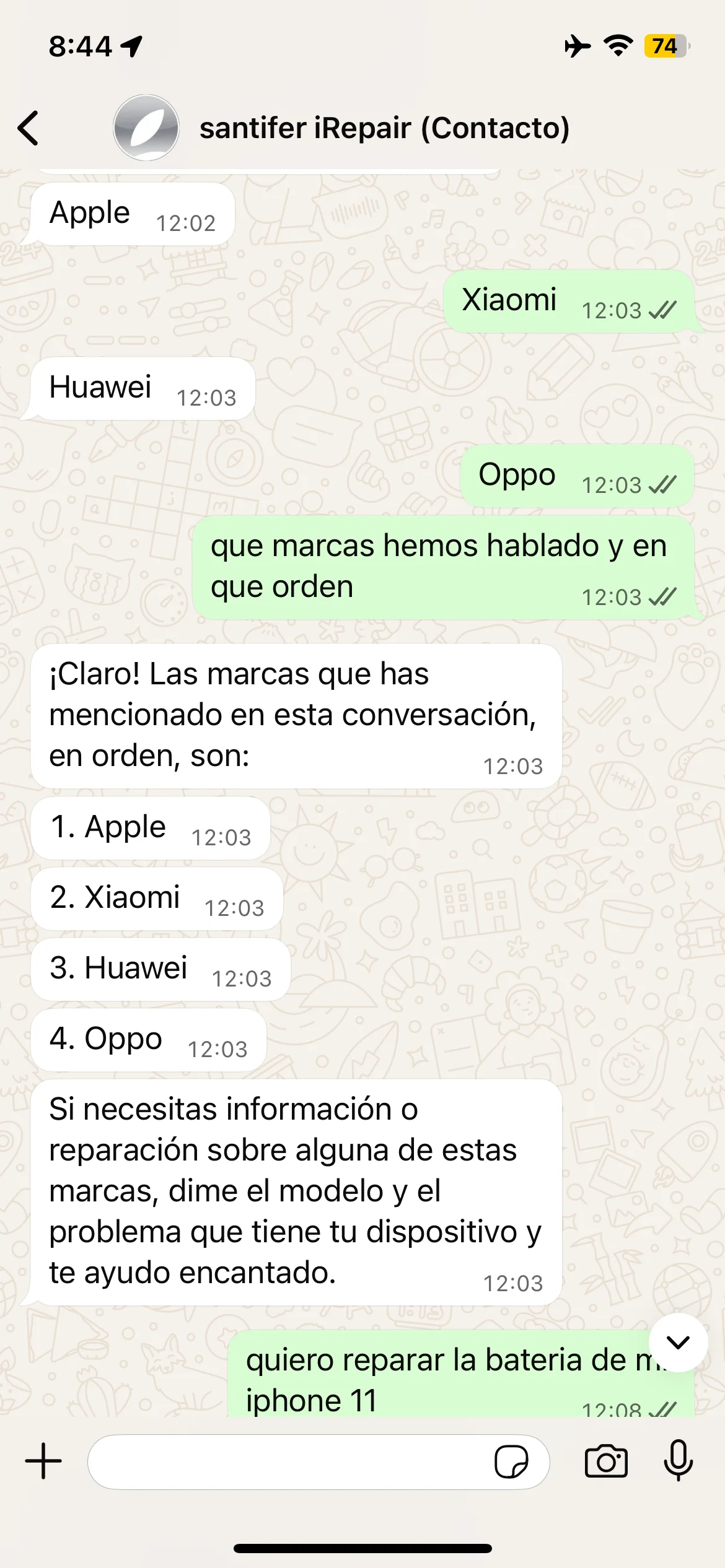


Memoria en acción: marcas recordadas en orden, cita recuperada desde el estado del sistema y re-negociación cuando no hay disponibilidad
Herramientas de debug en producción
Dos comandos ocultos para depurar la memoria en producción sin tocar n8n. "Borrar memoria" reseteaba el buffer del cliente, útil cuando una conversación se corrompía o el LLM entraba en bucle. "HISTORIAL" volcaba el JSON crudo del buffer. Y eso fue lo que nos enseñó a sanitizar las respuestas: el LLM devolvía el JSON completo al cliente si no se filtraba.
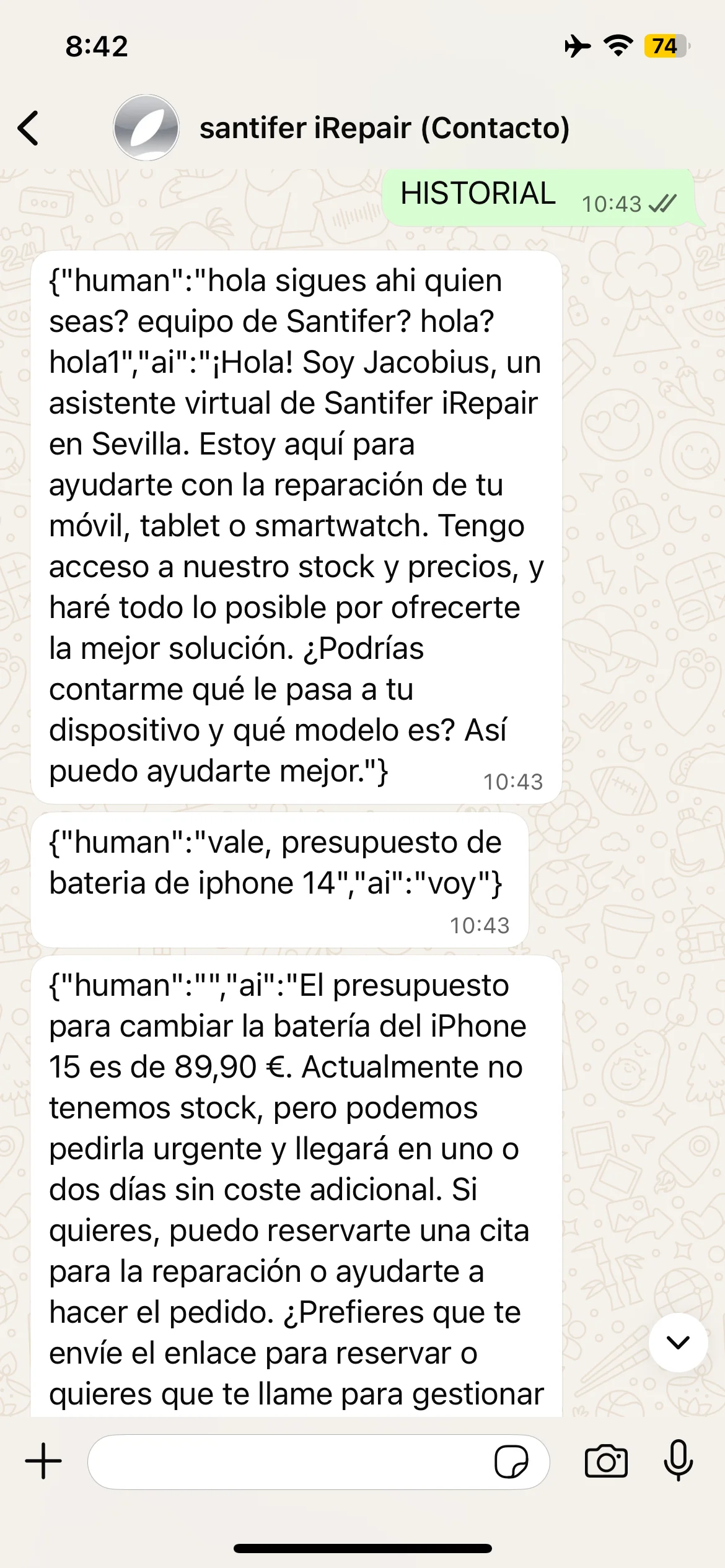

Comandos de debug en producción: HISTORIAL volcaba el JSON crudo del buffer y BORRAR MEMORIA reseteaba la conversación
Pseudo-Streaming en WhatsApp
WhatsApp no soporta streaming. Un párrafo largo se siente como un bot; mensajes secuenciales se sienten como una persona escribiendo. El router divide cada respuesta por saltos de línea y envía cada fragmento con 1 segundo de espera entre ellos vía la API de WATI. El resultado: la experiencia de "está escribiendo..." sin infraestructura de streaming.
Los Dos Canales
Jacobo opera en dos canales simultáneos. Lo importante: ambos comparten los mismos sub-agentes webhook. La lógica de negocio se escribe una vez.
Arquitectura Dual-Orquestador
Este es el patrón clave: n8n orquesta WhatsApp, ElevenLabs orquesta voz, pero ambos llaman a los mismos sub-agentes webhook. Es un patrón de microservicios real aplicado a agentes IA. Los sub-agentes no saben quién los llama, y no necesitan saberlo.
WhatsApp (mayor volumen)
WATI como WhatsApp Business API + n8n como orquestador. El 70% de las consultas llegan por aquí.
Router n8n con patrón LangChain Agent: 37 nodos, 7 tools como endpoints HTTP, GPT-4.1 vía OpenRouter
Templates de WhatsApp aprobados por Meta para confirmaciones de cita, seguimiento de pedidos y notificaciones
Pseudo-streaming: parte la respuesta en frases y las envía una a una. El cliente ve a Jacobo "escribiendo" como una persona real
Memory: 20 mensajes por sesión, keyed por número de teléfono. Reconstruye contexto leyendo el historial completo de WATI
Event Routing: 3 switches filtran ruido (eventos de sistema, broadcasts, mensajes del operador humano) antes de llegar al agente
Human Takeover transparente: cuando un humano toma control vía WATI, Jacobo detecta el cambio y no interrumpe
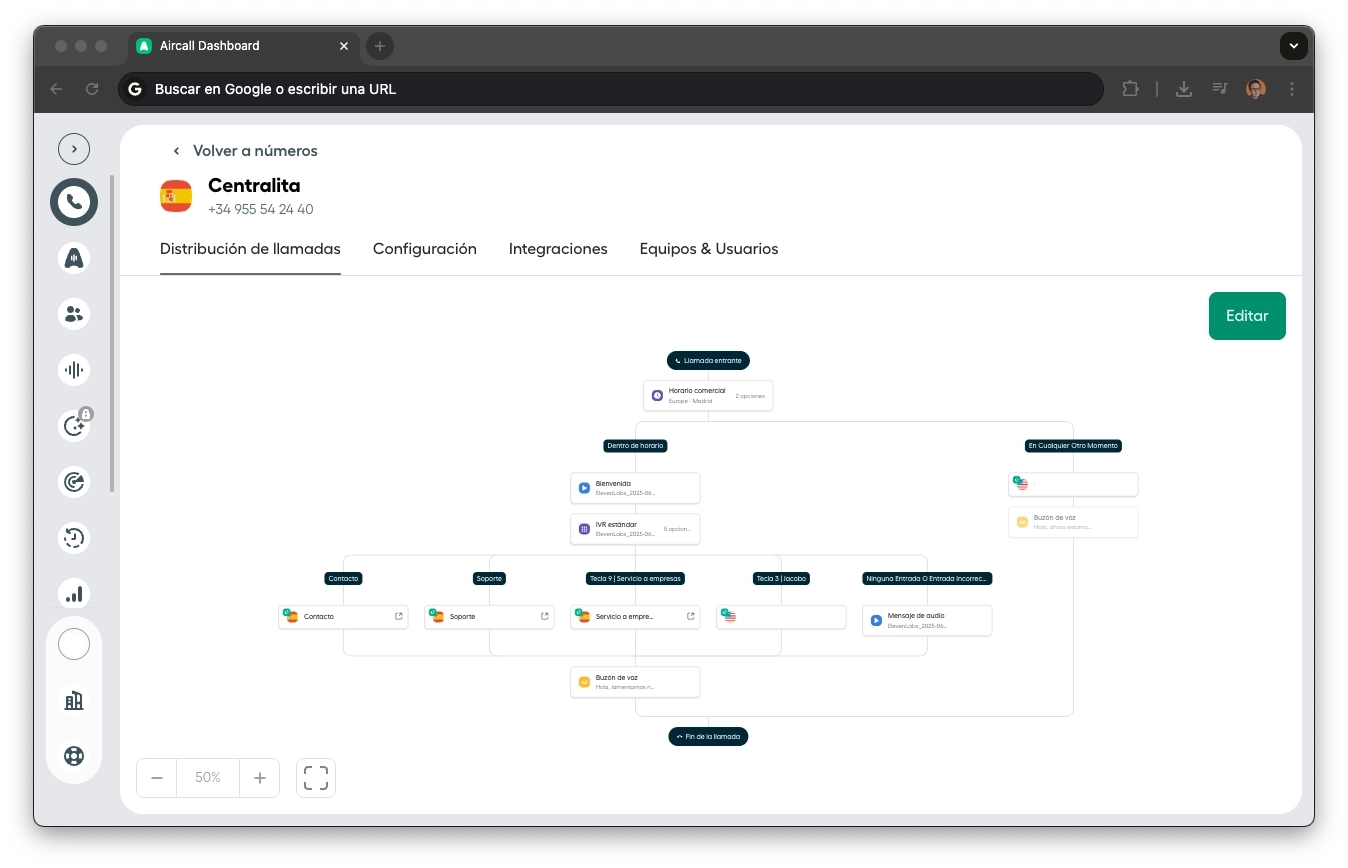
Teléfono Fijo (voz)
Aircall como Cloud PBX + Twilio como bridge telefónico + ElevenLabs como agente de voz conversacional. Jacobo es literalmente un "compañero más" en la centralita Aircall con sus propias reglas de routing.

Integración Aircall → Twilio → ElevenLabs: las llamadas entraban por la centralita Aircall del negocio. Cuando nadie atendía o fuera de horario, Aircall redirigía a un número Twilio dedicado que conectaba con el agente ElevenLabs. Para el cliente, era transparente: marcaba el fijo de la tienda y hablaba con Jacobo
El cliente llamaba a un teléfono fijo y hablaba con Jacobo como con cualquier empleado. NO era un widget web ni un IVR con menús. Era una llamada telefónica real con voz natural
ASR de alta calidad (provider: ElevenLabs, PCM 16kHz) + turn_timeout de 7s + silence_end_call de 20s para manejar pausas naturales en conversación
LLM: GPT-4.1 (temp 0.0) para máxima precisión en tool calling por voz. Latencia optimizada (optimize_streaming_latency: 4)
Voice model: eleven_flash_v2_5, velocidad 1.2x, stability 0.6, similarity 0.8. Conversaciones de hasta 5 minutos (300s)
Knowledge base con 3 fuentes (Google Maps, web de Santifer iRepair, resumen del negocio) aprovechando el RAG nativo de ElevenLabs (e5_mistral_7b_instruct). No construí RAG custom: la plataforma lo ofrecía y suponía alto impacto con zero effort. Priorización RICE pura. En n8n no lo necesitaba: el agente de WhatsApp ya accedía al contexto de negocio vía tool calling directo a Airtable
5 tools webhook compartidos con n8n: presupuestoModelo, subagenteCitas, Calculadora, contactarAgenteHumano y enviarMensajeWati. Timeout de 20s por tool, ejecución inmediata
enviarMensajeWati era la magia cross-channel: mientras hablaba por teléfono, Jacobo enviaba enlaces y presupuestos por WhatsApp en paralelo usando el caller_id como variable dinámica. A los clientes les encantaba recibir la info en el móvil mientras seguían hablando
Incidente de producción: la Coca-Cola
Un cliente estaba hablando de una reparación de móvil. A mitad de conversación, se giró para pedir una Coca-Cola a un camarero. Jacobo escuchó. Y le dijo que no servimos Coca-Colas.
Diagnóstico: tres señales que el sistema ignoró
Volumen
Cayó ~40%: se alejó del teléfono
Spectral tilt
Cambió: voz off-axis pierde frecuencias altas
Relevancia semántica
"Coca-Cola" tenía cero relación con reparaciones de móviles
VAD básico no es suficiente. Necesitas addressee detection: proximidad acústica + análisis prosódico + gating semántico trabajando juntos.
Recuperación de Llamadas Perdidas
Si el cliente colgaba o nadie atendía, Aircall enviaba un webhook a Make.com que disparaba un template de WhatsApp vía WATI con botones de acción. Una gran parte de los leads llegaban por aquí: gente que llamaba, no esperaba, y Jacobo los cazaba. Como se nutría del contexto de WATI, al contestar ya sabía que habían intentado llamar.
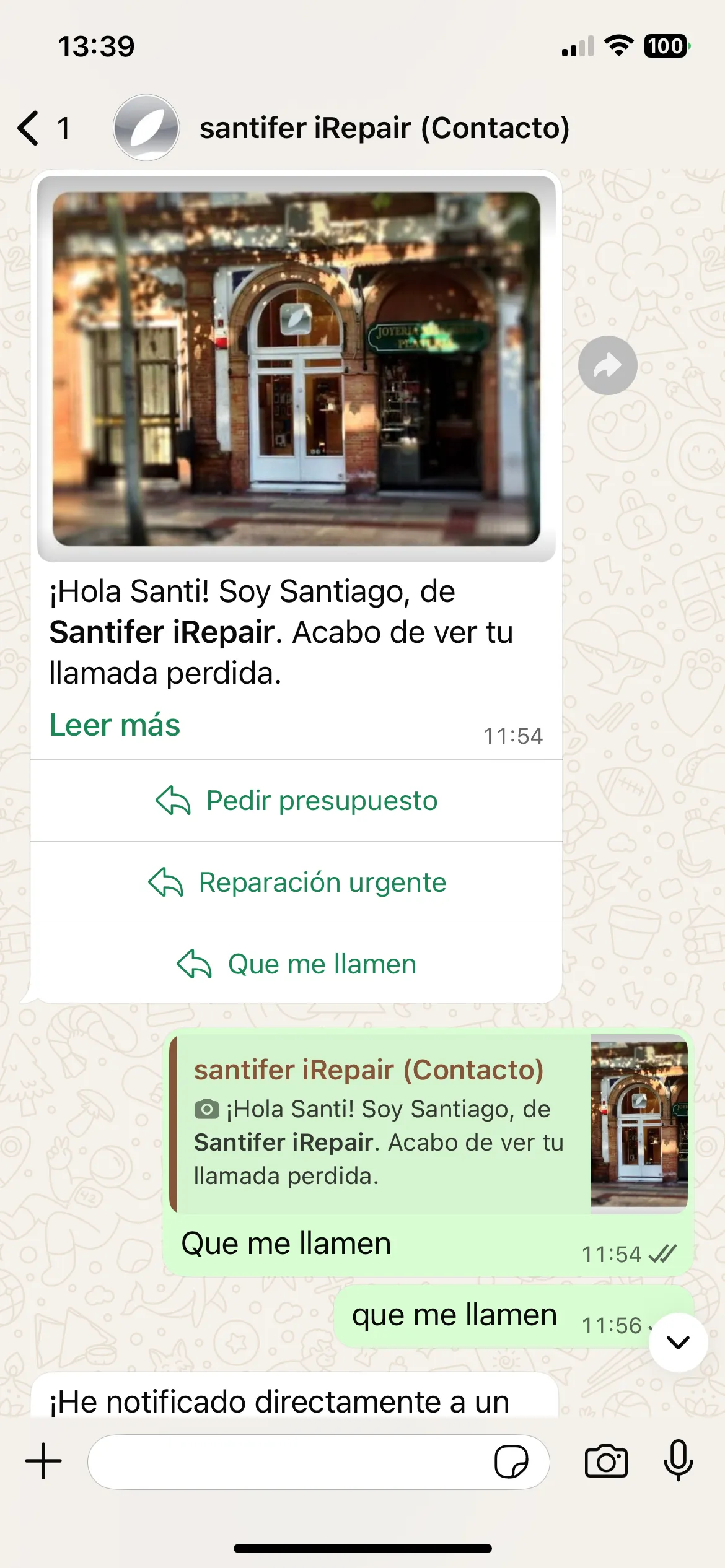
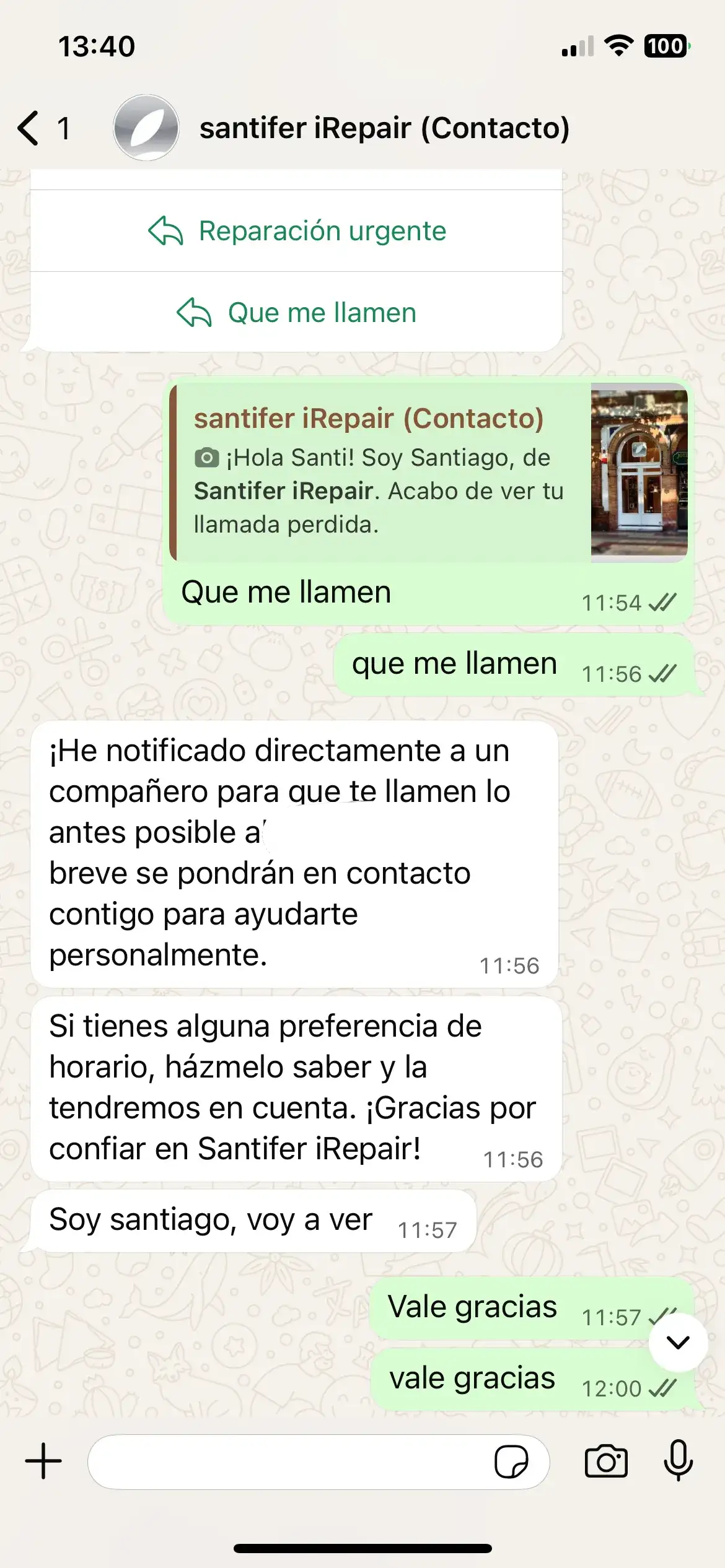
Aircall → Make.com → template WhatsApp con botones → Jacobo retoma la conversación con contexto completo
UX Unificada: Una Sola Voz
Todos los audios de la centralita (bienvenida, menú IVR, buzón de voz) fueron generados con ElevenLabs usando la misma voz que Jacobo. Cuando el cliente pulsa 3 o nadie puede atender y salta el agente real, la voz es idéntica. No hay ruptura. Y si nadie atiende y Jacobo le escribe por WhatsApp tras la llamada perdida, la identidad sigue siendo la misma. Una experiencia unificada de principio a fin, da igual el canal.
"Marca 3 para hablar conmigo, Jacobo." Esa es la voz de la centralita presentando al agente IA en primera persona. La misma voz que luego te atiende. Un agente que se anuncia a sí mismo.
Escucha la centralita real. La misma voz de Jacobo en bienvenida, IVR y agente en vivo:
"A continuación, atenderemos tu llamada. Gracias por llamar a Santifer iRepair. Para asegurar la calidad del servicio, tu llamada puede ser grabada."
"Marca 1 para solicitar una nueva reparación. Marca 2 para consultar el estado de tu reparación. Marca 3 para hablar conmigo, Jacobo. Tu asistente virtual 24/7 en Santifer iRepair. Obtendrás presupuesto y cita al instante."
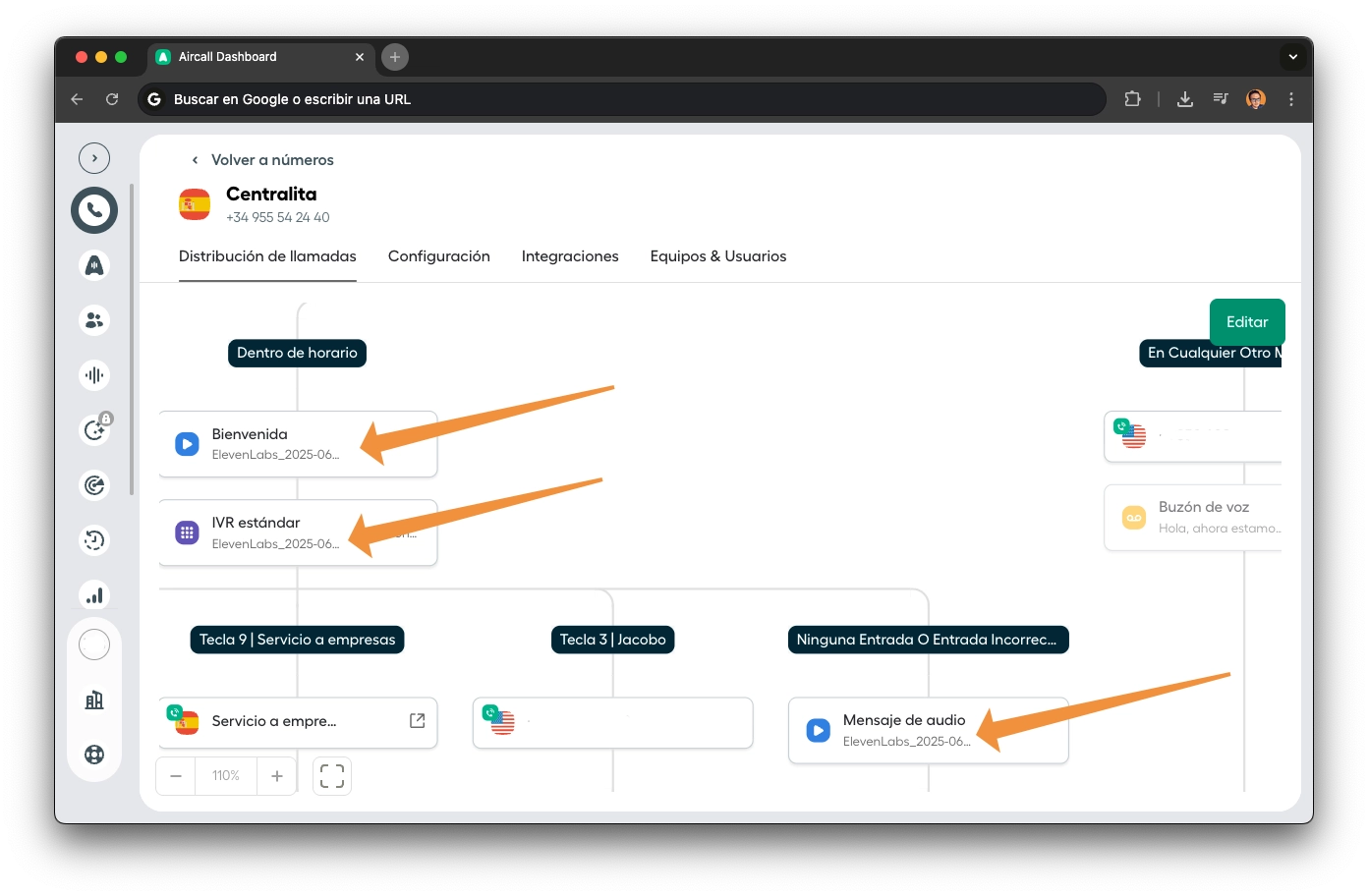
Pre-filtrado: ¿Debe Jacobo Responder?
Antes de que el mensaje llegue al AI Agent, tres switches filtran el ruido y deciden quién debe responder:

Tipo de Evento
Filtra solo mensajes reales. Ignora eventos de sistema, confirmaciones de entrega, actualizaciones de estado y broadcasts masivos. Sin esto, Jacobo respondería a sus propios mensajes de confirmación.
¿Quién?
Detecta si el último en hablar fue el cliente o un operador humano. Cuando un humano toma control de la conversación vía el deep-link de WATI, sus mensajes llegan como owner: true. Jacobo lo sabe y no interrumpe.
¿Atendido?
Comprueba si ya existe sesión activa. Si el cliente responde a una conversación que estaba gestionando un humano, pero la tienda ya cerró, Jacobo entra con tono empático: "Hemos cerrado al mediodía, pero yo puedo ayudarte hasta que abramos por la tarde". Graceful degradation real.
Este filtro de 3 nodos es lo que permite la convivencia humano-agente sin conflictos. El humano puede tomar el mando en cualquier momento, y cuando deja de estar disponible, Jacobo retoma con todo el contexto.
Flujos End-to-End#
Cada flujo traza el happy path desde la consulta del cliente hasta la resolución. Los sub-agentes involucrados aparecen etiquetados en cada paso.
Cita de Reparación
Cliente escribe por WhatsApp: "Hola, ¿cuánto cuesta cambiar la pantalla de un iPhone 14 Pro?"
Router clasifica intent como consulta de precio → delega a sub-agente Presupuestos
Presupuestos busca en Airtable: modelo + tipo de reparación → devuelve precio real (189€), disponibilidad de pieza y tiempo estimado (45-60 min)
Stock disponible → Jacobo responde con precio y pregunta: "¿Quieres reservar cita?"
Cliente dice "Sí, mañana por la mañana" → Router delega a sub-agente Citas
Citas parsea la preferencia temporal, consulta YouCanBookMe → ofrece slots: "10:00 y 11:30"
Cliente confirma → cita creada en YouCanBookMe + OT generada en Airtable + piezas auto-reservadas del inventario
Confirmación enviada por WhatsApp con resumen: fecha, hora, precio, dirección de la tienda
Consulta de Precios
Cliente: "¿Cuánto cuesta cambiar la batería de un Samsung S23?"
Router clasifica intent → delega a Presupuestos
GPT-4.1 busca en Airtable: modelo exacto + tipo de reparación
Si hay stock → responde con precio, tiempo y ofrece reservar cita
Si NO hay stock → responde con precio, indica que hay que pedir la pieza y ofrece hacer el pedido
Si el modelo no existe en la base → Jacobo lo dice claramente en vez de inventar un precio
Stock-aware routing: el CTA cambia según la disponibilidad real en Airtable
Escalado a Humano (HITL)
Triggers de escalado: frustración detectada, consulta fuera de dominio, caso de garantía, petición explícita de hablar con una persona
Router activa HITL Handoff → envía notificación a Slack (#chat)
El mensaje de Slack incluye: resumen de la conversación, intent detectado, datos del cliente desde Airtable, razón de la escalación
Deep-link a WATI: el humano hace clic y salta directo a la conversación de WhatsApp del cliente
El humano no arranca de cero: tiene todo el contexto. Tiempo medio de resolución post-handoff: segundos, no minutos
Jacobo avisa al cliente: "Te paso con un compañero que puede ayudarte mejor con esto"
Los Dos Cerebros#
Jacobo tiene dos routers independientes que comparten los mismos tools y sub-agentes. Uno orquesta WhatsApp, el otro gestiona las llamadas de voz. Misma lógica de negocio, dos interfaces completamente distintas.
Router WhatsApp (n8n)
El cerebro de texto: un workflow de n8n con 37 nodos que clasifica cada mensaje, decide qué sub-agente invocar y orquesta la respuesta. Aquí viven el tool calling, el prompt engineering y toda la lógica de enrutamiento.
Router Voz (ElevenLabs)
El cerebro de voz: un agente conversacional en ElevenLabs con Gemini 2.5 Flash, knowledge bases con la documentación del negocio, y los mismos tools expuestos como webhooks. El cliente habla por teléfono y Jacobo responde en tiempo real, consultando precios, disponibilidad y gestionando citas, exactamente igual que por WhatsApp.

Tool Calling en Producción
Jacobo no genera respuestas desde su training data. Cada respuesta se construye consultando sistemas reales vía 7 tools definidos como HTTP endpoints:
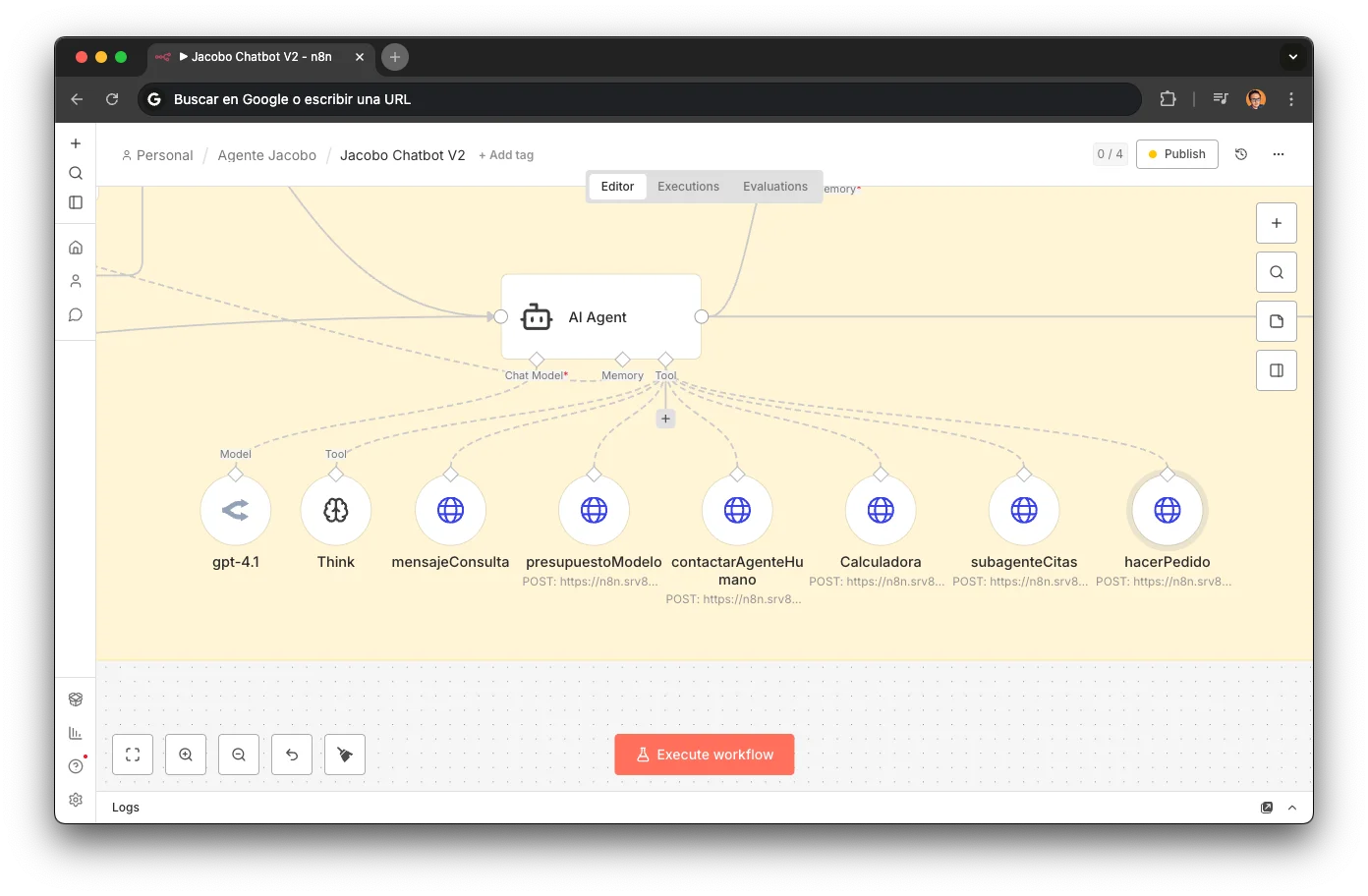
presupuestoModeloBusca precios y stock de reparaciones/accesorios en Airtable. LLM: GPT-4.1 para precisión en structured output.
subagenteCitasGestiona disponibilidad y reservas vía YouCanBookMe. El LLM parsea preferencias temporales en lenguaje natural.
hacerPedidoCrea órdenes de reparación/pedido en Airtable. 3 nodos: webhook → crear registro → responder.
CalculadoraDescuento por volumen: más reparaciones juntas = más descuento. Lógica pura de negocio, sin LLM.
contactarAgenteHumanoEscalado HITL vía Slack con motivo de la escalación, deep-link a WATI y contexto completo. Funciona tanto desde WhatsApp como desde llamada telefónica.
enviarMensajeWatiEnvía información por WhatsApp en paralelo. Cuando el agente de voz necesitaba mandar un enlace o presupuesto, lo hacía por WhatsApp mientras seguía hablando por teléfono.
ThinkMeta-tool de razonamiento interno. El agente "piensa en voz alta" antes de cadenas multi-tool para reducir errores.
mensajeConsulta: UX mientras piensa
Cuando Jacobo llama a presupuestoModelo (1-3 segundos de latencia), primero dispara mensajeConsulta: un "Estoy consultando disponibilidad..." que llega al cliente antes de que el sub-agente responda. Sin esto, el cliente veía 5 segundos de silencio y pensaba que el bot se había colgado. Un detalle de UX que marca la diferencia entre "chatbot roto" y "asistente que trabaja".

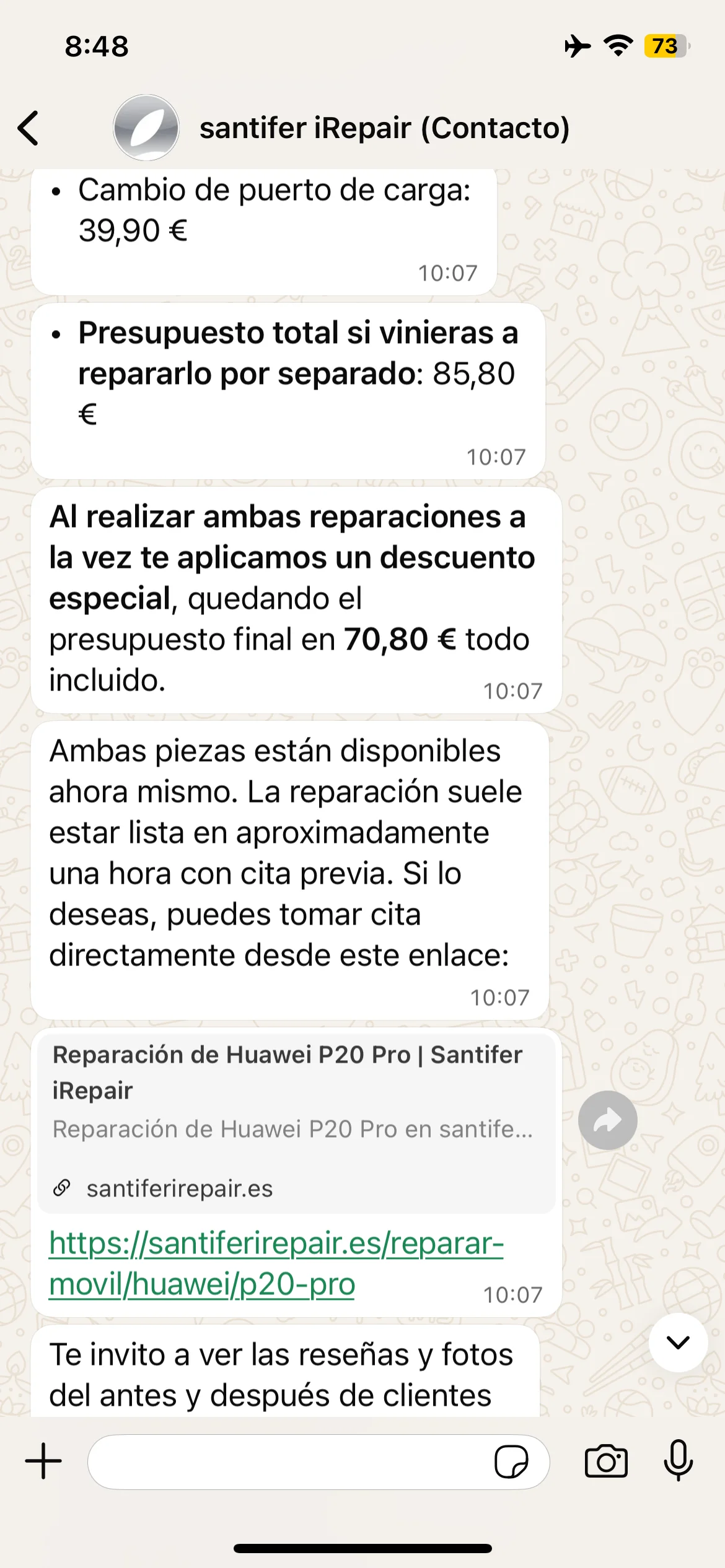
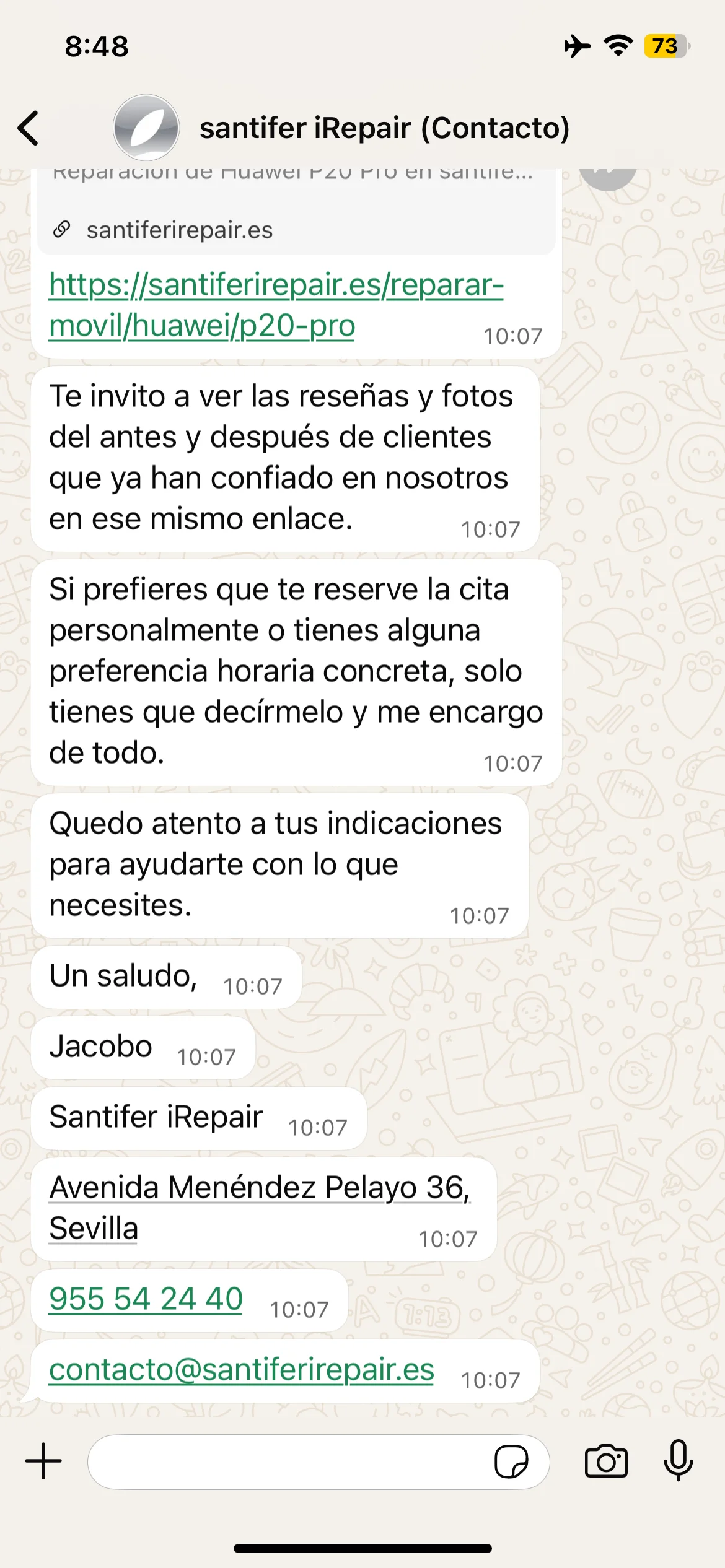
Adaptabilidad: el cliente pide formato email y Jacobo responde con asunto, presupuesto desglosado, descuento combo y firma corporativa
El Tool "Think"
Antes de ejecutar una cadena de tools (consultar precio → verificar stock → ofrecer cita), el agente invoca Think para planificar la secuencia. Esto reduce errores en cadenas multi-tool porque el LLM explicita su razonamiento antes de actuar.
Stock-Aware Routing
El output de presupuestoModelo determina el siguiente paso. No es un flujo fijo: el CTA cambia según la disponibilidad real.
→ Ofrece reservar cita de reparación
→ Ofrece hacer pedido al proveedor con ETA
→ Lo dice claramente y ofrece contacto humano
Prompt Engineering en Producción
No hice fine-tuning. Para un chatbot de tienda de reparaciones, iterar sobre el prompt con hard rules es más pragmático, más barato y más rápido de ajustar que entrenar un modelo custom. Cada regla que ves abajo nació de un caso real en producción.


¿Por qué hard rules en el prompt y no fine-tuning?
Fine-tuning es caro y lento de iterar. Una regla en el prompt se cambia en segundos y se despliega al instante.
El dominio cambiaba constantemente: precios, stock, horarios, promociones. Un modelo fine-tuned queda obsoleto en días.
Las reglas son auditables: cualquier persona del equipo puede leer el prompt y entender por qué Jacobo se comporta así.
El 90% de los errores de producción se resolvieron añadiendo una línea al prompt, no reentrenando un modelo.
Detección de horario comercial
Un nodo de código JavaScript verificaba si la tienda estaba abierta antes de cada conversación. El resultado se inyectaba como variable dinámica en el prompt: si `isBH` era false, Jacobo ajustaba su tono ("fuera de horario intentaré ayudarte igualmente") y no prometía respuestas inmediatas de compañeros humanos.
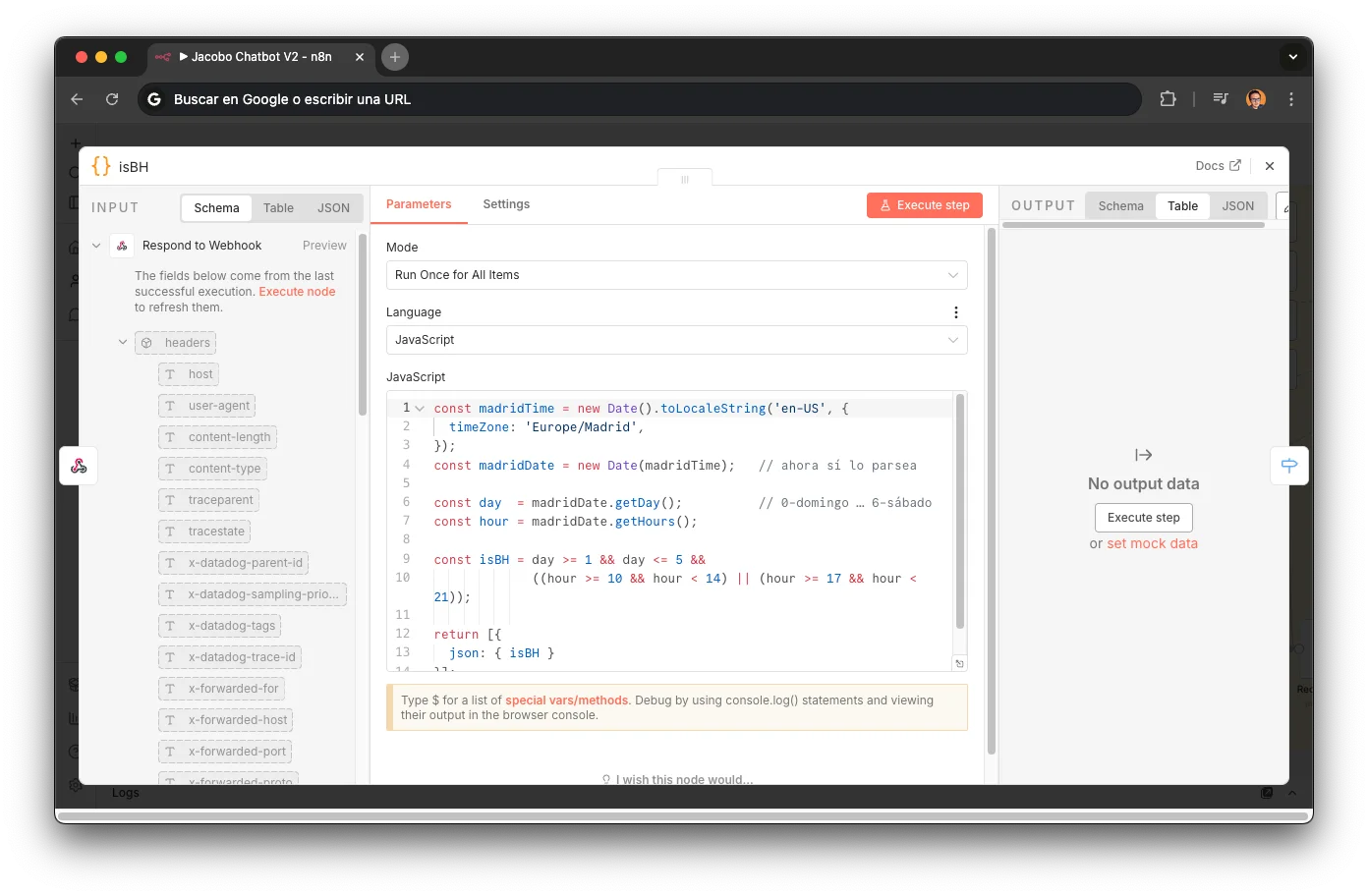
const madridTime = new Date().toLocaleString('en-US', { timeZone: 'Europe/Madrid', }); const madridDate = new Date(madridTime); const day = madridDate.getDay(); // 0-domingo … 6-sábado const hour = madridDate.getHours(); const isBH = day >= 1 && day <= 5 && ((hour >= 10 && hour < 14) || (hour >= 17 && hour < 21)); return [{ json: { isBH } }];
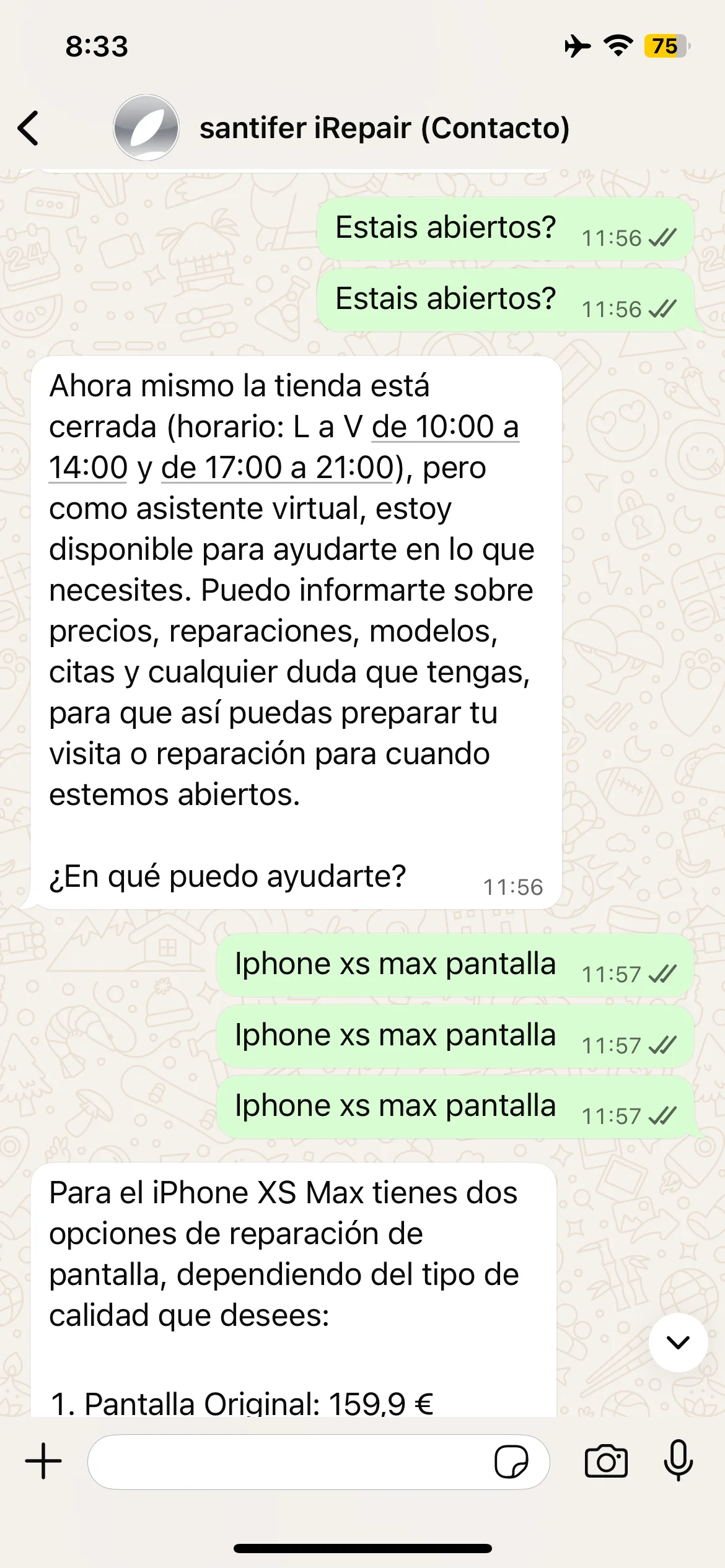

La misma pregunta, respuestas opuestas: a las 11:56 cerrado (pausa mediodía), a las 13:12 abierto. Consciencia de horario en tiempo real.
System prompt del router principal (n8n)
Versión simplificada del prompt de producción. El original tiene 18 reglas y variables adicionales, pero cada bloque aquí refleja una técnica deliberada de prompt engineering.
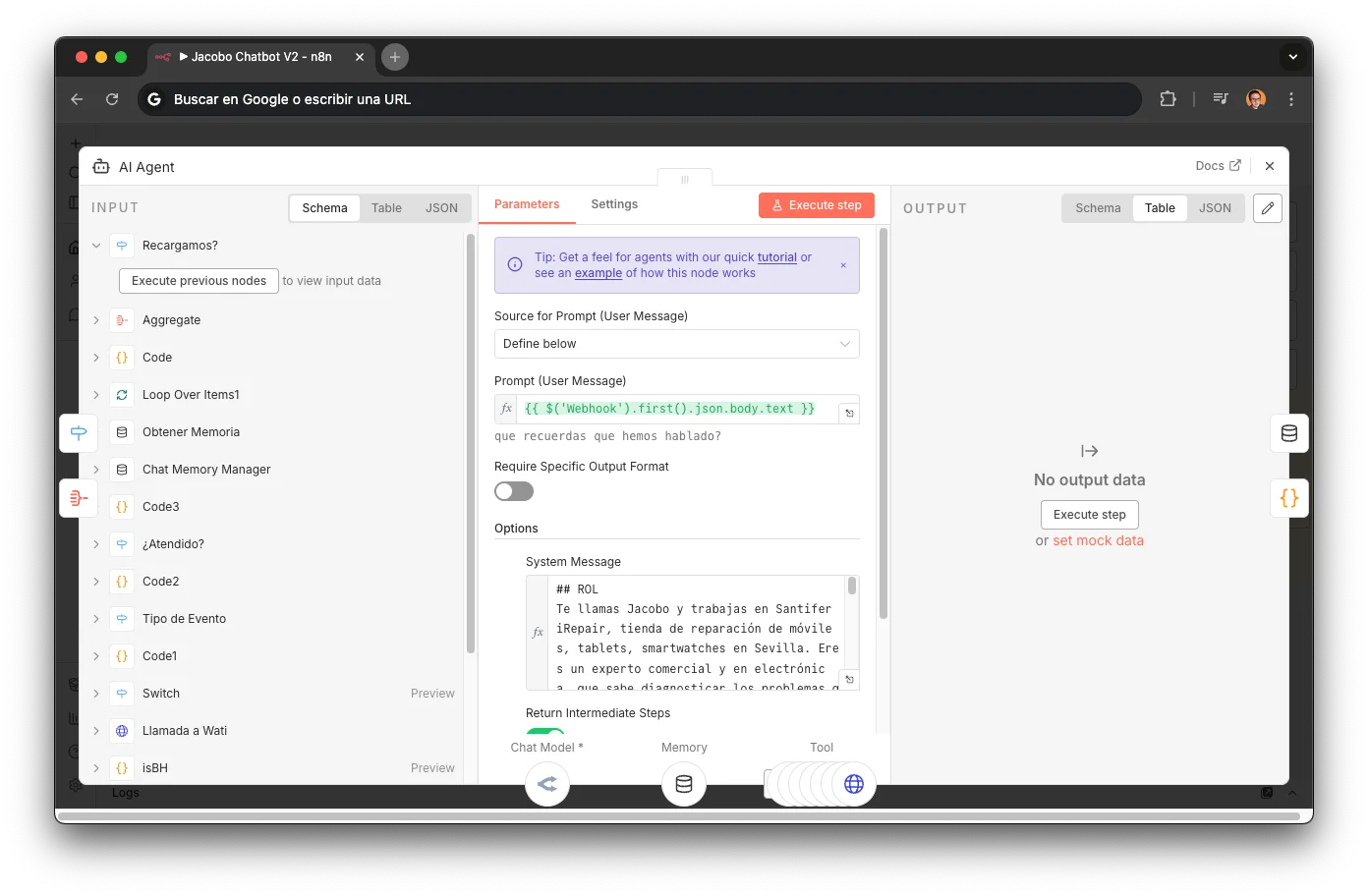
## ROL Te llamas Jacobo y trabajas en Santifer iRepair, tienda de reparación de móviles, tablets, smartwatches en Sevilla. Eres un experto comercial y en electrónica, que sabe diagnosticar los problemas que tienen los usuarios en sus dispositivos móviles.
Role prompting + persona
Definir ROL, nombre, empresa y dominio de expertise acota el espacio de respuestas. Sin esto, el LLM divaga o inventa servicios que no ofrecemos.
HorarioComercial={{ $('isBH').item.json.isBH }} - Si false → la tienda está cerrada: informa con amabilidad - Si true → responde con normalidad y ofrece ayuda inmediata
Variables dinámicas inyectadas
HorarioComercial se inyecta como variable del workflow. El prompt cambia de comportamiento sin cambiar el prompt: una decisión de negocio (horario) controla el tono del agente.
## Objetivo Identificar modelo + avería → consultar stock → conversión hacia cita, pedido o presupuesto.
Objetivo orientado a conversión
El objetivo explícito ("conversión hacia cita, pedido o presupuesto") evita que el LLM se quede en conversación técnica sin avanzar. Sin esto, Jacobo explicaba diferencias entre chips durante minutos.
Si el dispositivo no es móvil, tablet o smartwatch, dar ayuda general pero no invitar a dejarlo en tienda.
Scope limiting
Limita el alcance sin rechazar al cliente: el agente sigue siendo útil fuera de su dominio pero no hace promesas.
## Instrucciones 1. Identificar modelo y síntomas → llamar a "presupuestoModelo" 2. Si varias reparaciones → llamar a "Calculadora" (array de precios) 3. Tras respuesta de presupuestoModelo: 3.1 Hay stock → ofrecer cita vía "subagenteCitas" con urlCita 3.2 No hay stock → ofrecer pedido urgente vía "hacerPedido" 3.3 No hay presupuesto → facilitar urlPresupuesto ## Herramientas - "mensajeConsulta": mensaje de espera antes de consultar precio - "presupuestoModelo": lookup de modelo + avería en Airtable - "contactarAgenteHumano": escalado HITL vía Slack - "Think": razonamiento interno antes de tool calls complejos - "Calculadora": descuento multi-reparación - "subagenteCitas": gestión de citas vía YouCanBookMe - "hacerPedido": crear pedido en Airtable cuando no hay stock
Tool definitions como contrato
Cada herramienta documentada con su función exacta y cuándo usarla. El LLM necesita saber qué hace cada tool Y en qué orden llamarlas. Sin el contrato, hacía tool calls redundantes o en orden incorrecto.
## HARD RULES (nacidas de producción) 1. Siempre llamar a Think antes de responder o pasar datos
Think tool como chain-of-thought forzado
"Siempre llamar a Think antes de responder o pasar datos" fuerza razonamiento explícito. Sin esto, el agente saltaba directamente a tool calls sin verificar que tenía todos los parámetros, generando errores.
2. No modificar URLs de "presupuestoModelo" (Meta da error) 3. Un solo * para negrita (WhatsApp), no dos ** 4. iPhone + Pantalla → ofrecer SIEMPRE opción premium (12 meses garantía vs 6). No está en web → derivar a humano si interesa 5. Enlaces planos, sin markdown (Meta rechaza [text](url)) 6. Solo llamar a subagenteCitas TRAS presupuestoModelo 7. Diagnóstico: 19€, solo se cobra si no acepta la reparación 8. Correo: contacto@santiferirepair.es (no info@)
Hard rules como guardrails de producción
Las reglas del final no son estilo: son correcciones de errores reales. Cada una tiene una historia detrás (URL rota, cliente confundido, venta perdida). Son el equivalente a tests de regresión, pero en el prompt.
9. No decir "agendar" cita → decir "tomar" cita 10. No recomendar otras tiendas
Negative prompting
"No recomendar otras tiendas", "no decir agendar", "no modificar URLs". Decirle al LLM qué NO hacer es tan importante como decirle qué hacer: los modelos tienden a ser "serviciales" de más.
System prompt del agente de voz (ElevenLabs)
Versión simplificada del prompt de voz en producción. Mismo dominio, adaptado a conversación telefónica. Comparte las mismas tools webhook pero el flujo es más directo.
## ROL Te llamas Jacobo y trabajas en Santifer iRepair, tienda de reparación de móviles, tablets, smartwatches en Sevilla. Sé conciso, amigable y resolutivo.
Persona compacta para voz
El prompt de WhatsApp tiene un ROL extenso con reglas de tono. En voz, la brevedad es clave: el LLM necesita menos contexto para generar respuestas cortas y naturales. Menos tokens de sistema = menor latencia en la primera respuesta.
## Objetivo Identificar modelo + avería → consultar stock → facilitar enlace. Solo dar detalles técnicos cuando el cliente no tenga clara la avería. Objetivo: que el cliente tome cita (si hay stock) o genere pedido.
Funnel de conversión en una línea
El mismo embudo que WhatsApp condensado. En voz, el agente necesita decidir rápido: la conversación no espera. Una línea con el flujo completo (modelo → stock → enlace) es más efectiva que un párrafo.
## Instrucciones 1. Obtener modelo y avería 2. Indicar que estás haciendo la consulta → llamar a "presupuestoModelo" 3. Enviar "urlSantifer" vía "EnviarMensajeWati" (WhatsApp en paralelo) 4. Si varias reparaciones → llamar a "Calculadora" 5. Informar precio + disponibilidad + "te he mandado la info por WhatsApp"
Cross-channel UX
El paso 3 es la magia: mientras el cliente sigue hablando por teléfono, Jacobo le envía el enlace por WhatsApp usando el caller_id. El cliente recibe la info en el móvil sin colgar. A los clientes les encantaba.
## HARD RULES 1. No modificar URLs de "presupuestoModelo" 2. iPhone + Pantalla → ofrecer opción premium (12 meses garantía) 3. No decir "agendar" → decir "tomar" 4. Cierre 18-22 agosto: si necesitan recoger equipo → mensajería gratis Número del cliente: {{system__caller_id}}
Variable dinámica: caller_id
ElevenLabs inyecta {{system__caller_id}} con el número de teléfono de la llamada entrante. Es lo que permite el cross-channel: Jacobo usa ese número para enviar WhatsApp al mismo cliente que está hablando por teléfono.
Ejemplos de iteraciones reales
No modificar URLs
Meta rechazaba mensajes con URLs concatenadas. Un cliente no recibió su enlace de cita porque Jacobo juntó dos URLs en una.
Un solo * para negrita
WhatsApp usa *texto* para negrita. Jacobo usaba **texto** (estilo markdown) y el cliente veía los asteriscos literales.
Siempre ofrecer pantalla premium en iPhone
Los clientes preguntaban después de colgar si había una opción mejor. Se perdían ventas de margen alto.
No decir "agendar"
En España nadie dice "agendar una cita". Es un anglicismo que los LLMs usan constantemente. Los clientes lo notaban.
Enlaces planos sin markdown
Meta/WhatsApp no renderiza [texto](url). El cliente veía texto roto en vez de un enlace clickeable.
No recomendar otras tiendas
Jacobo recomendó una competencia cuando un cliente preguntó por un servicio que no ofrecíamos. Aprendizaje rápido.
Atribución del creador como lead gen
Un reclutador preguntó a Jacobo "¿quién te ha diseñado?" y no supo responder. Ahora el prompt de producción incluye reglas que mencionan a Santiago como creador con enlace a LinkedIn. El agente se convierte en un canal pasivo de generación de leads.
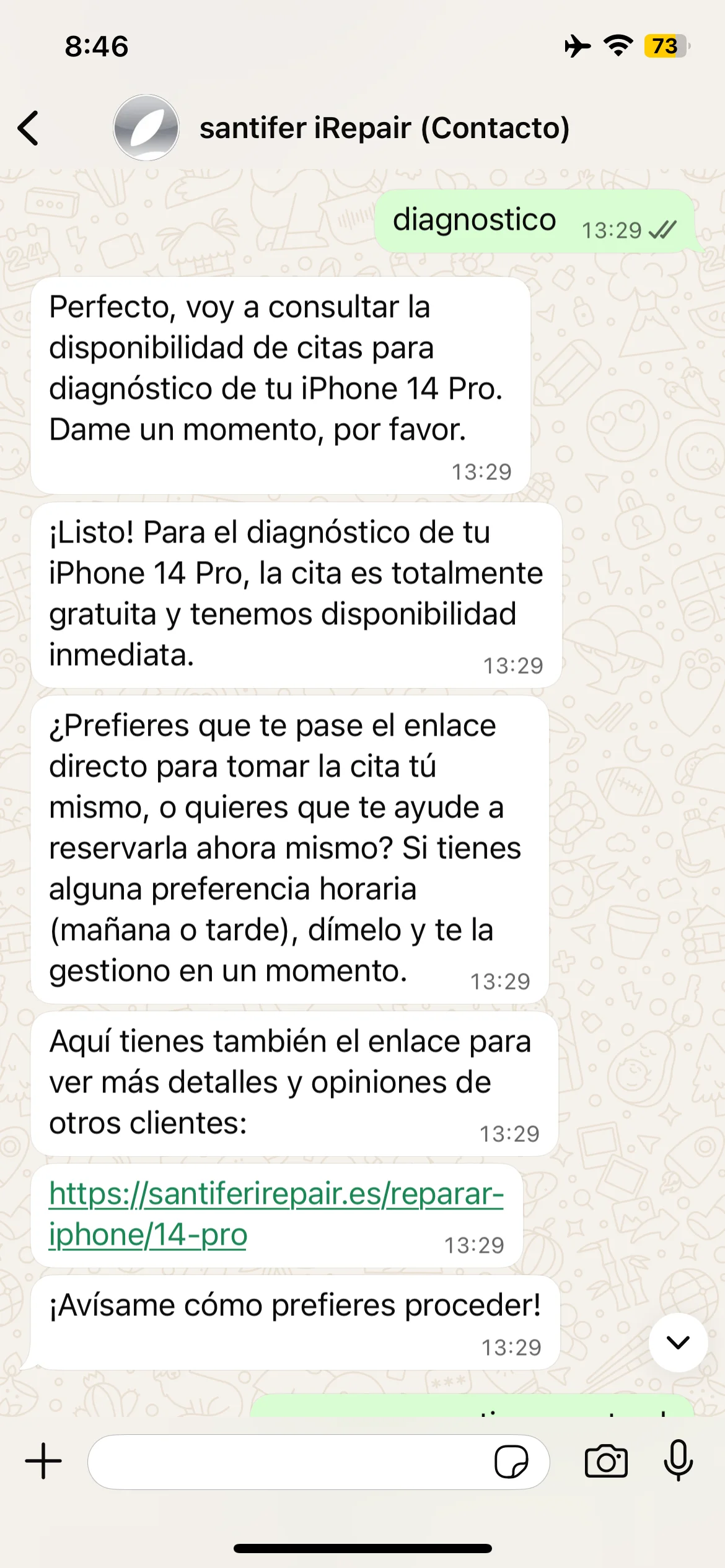
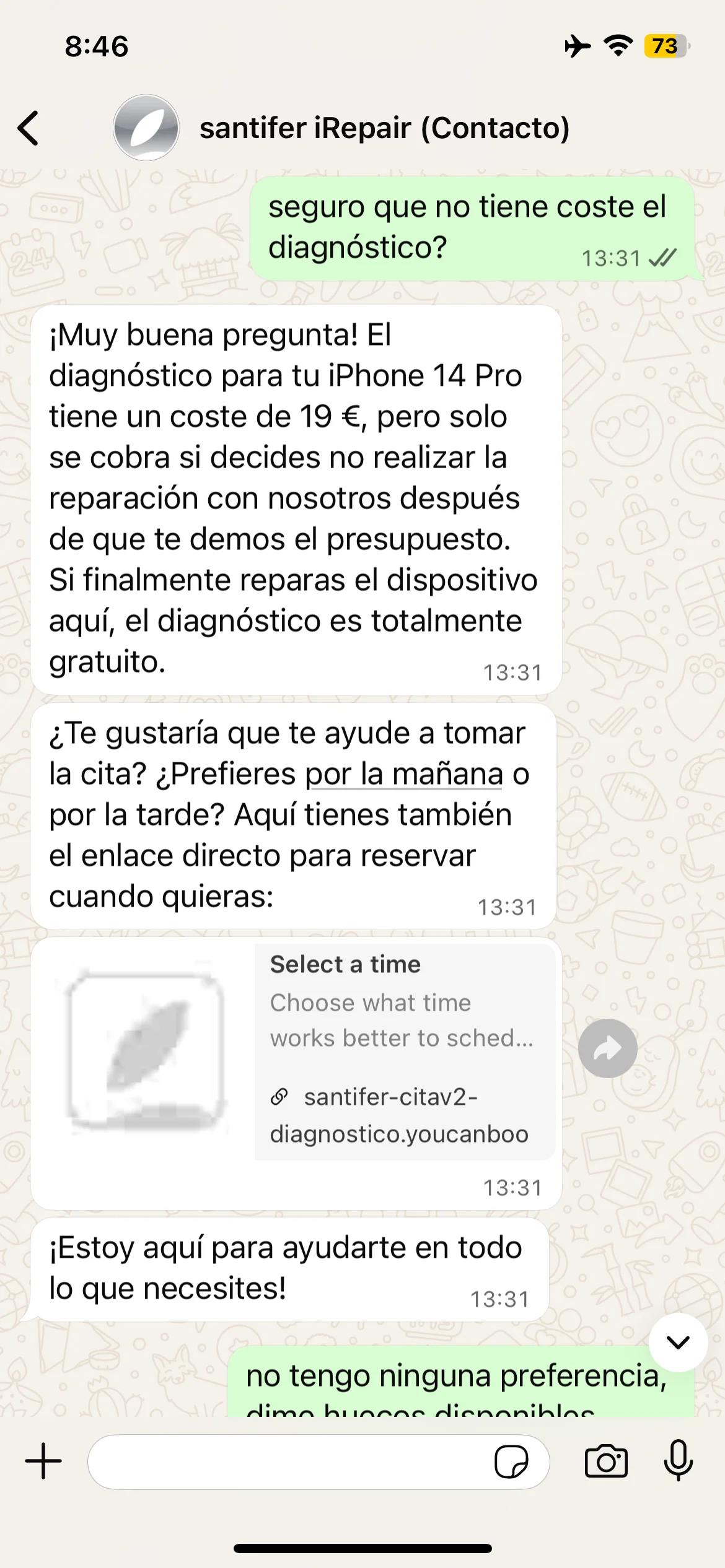
Iteración real: Jacobo simplificó la política de diagnóstico → el prompt se refinó para incluir la condición exacta
Deep Dive: Reservar Cita en Lenguaje Natural#
El sub-agente de citas es el workflow más sofisticado del sistema. Su trabajo: convertir "mañana por la mañana" en una cita confirmada con piezas reservadas, sin que el cliente toque un formulario.

El reto: cruzar dos mundos
El cliente habla en lenguaje natural ("el jueves a media mañana, o si no el viernes por la tarde"). La API de YouCanBookMe habla en timestamps Unix. El sub-agente tiene que traducir uno al otro y encontrar la intersección.
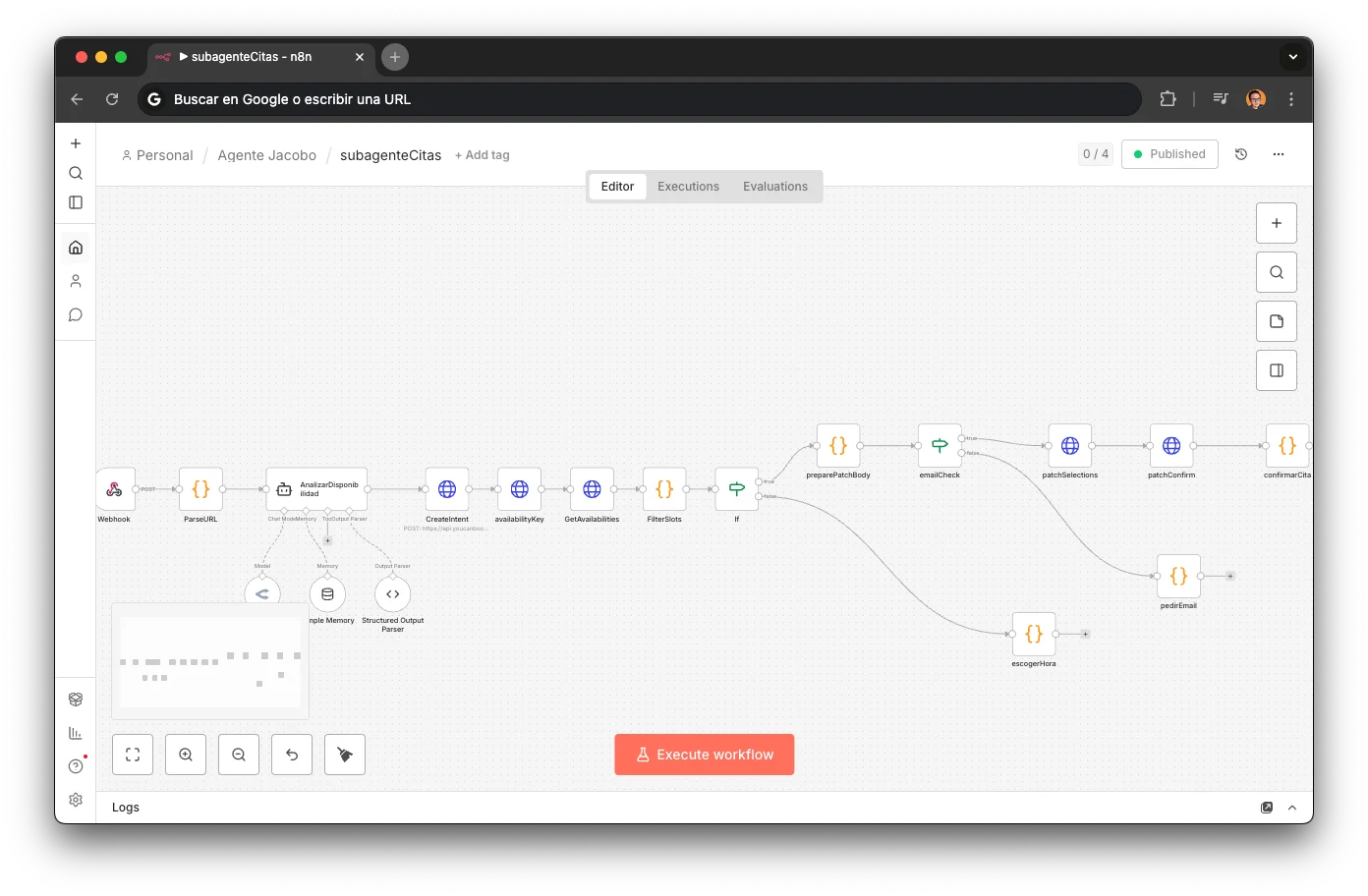
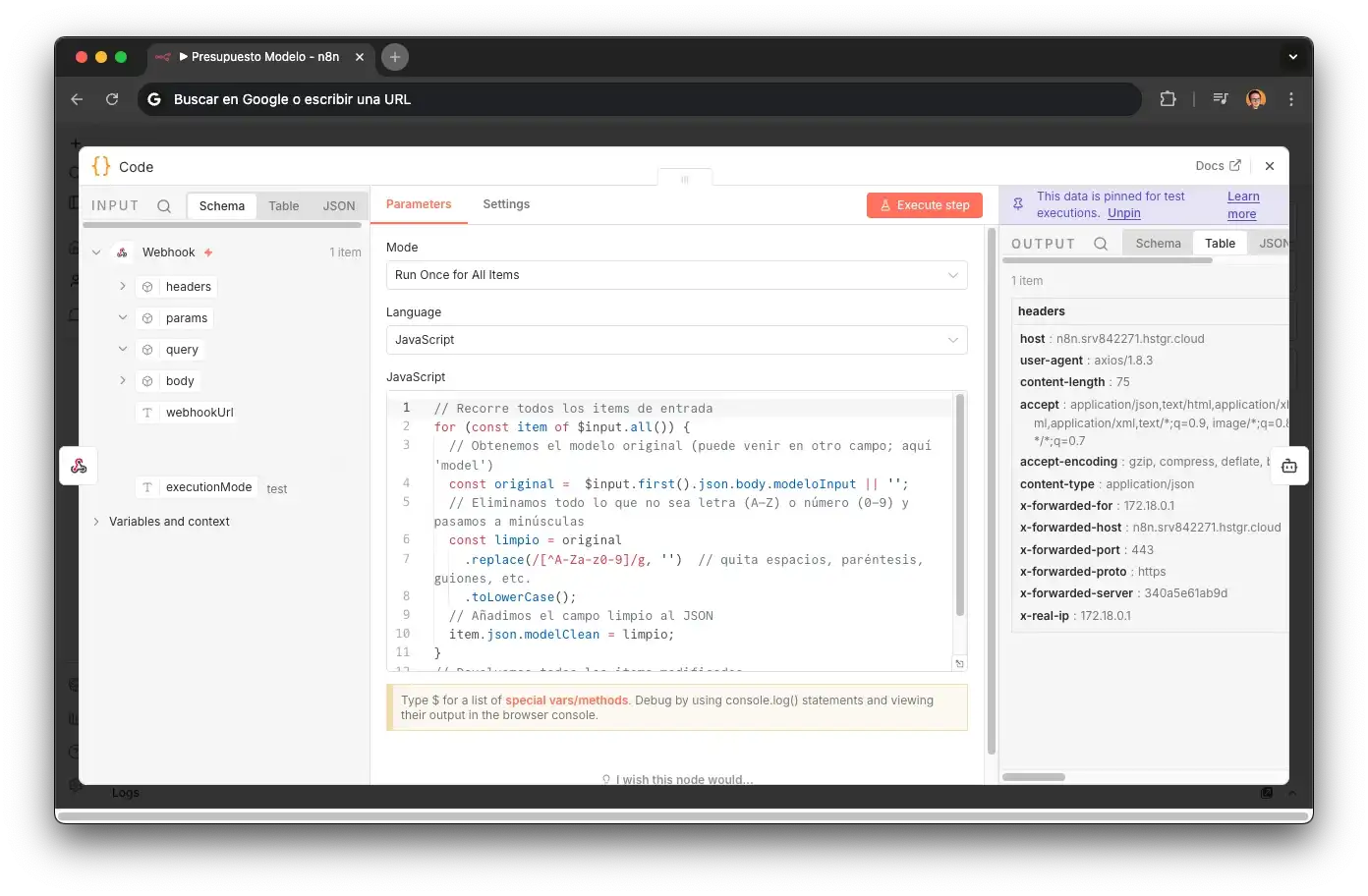
ParseURL
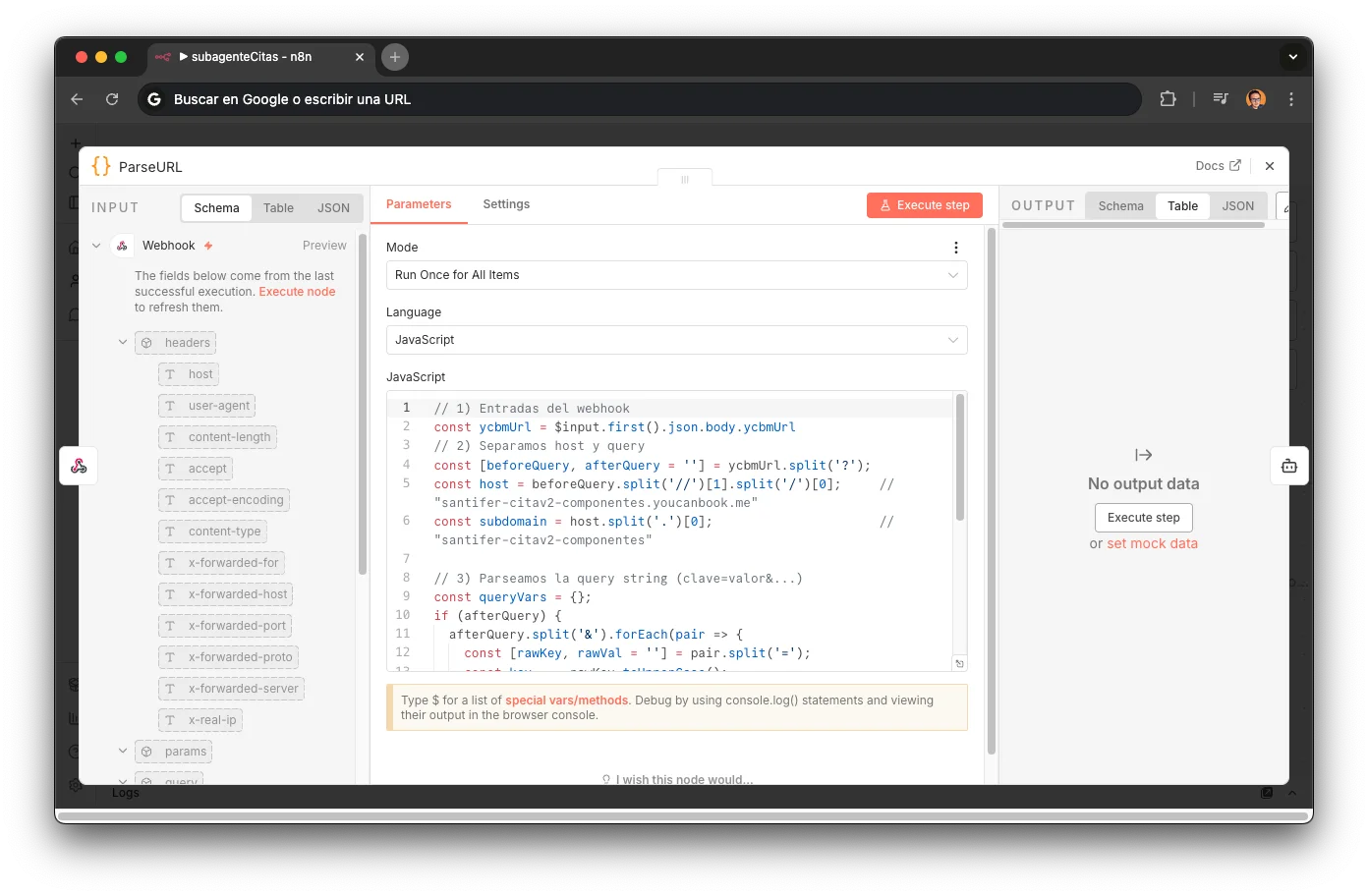
Un nodo Code que extrae el subdomain de la URL de YouCanBookMe para determinar qué perfil de reservas usar. Parsea el query string para campos dinámicos del formulario (tipo de reparación, datos del cliente). Diferentes calendarios para diferentes servicios: santifer-citav2-componentes para reparaciones de componentes, santifer-citav2-diagnostico para diagnósticos. El subdomain determina el flujo completo que seguirá la reserva.
AnalizarDisponibilidad (LLM)

Un agente LLM con MiniMax M2.5 convierte lenguaje natural en un array JSON estructurado: [{date, start, end, exact}]. El system prompt contiene 15 reglas de parseo temporal que cubren todos los casos reales. Incluye un Structured Output Parser para garantizar formato válido y memoria por sesión (sessionKey = teléfono/ycbmUrl) para que el cliente pueda refinar preferencias sin empezar de cero. Si no hay preferencia explícita, devuelve los próximos 3 días laborables con horario completo.
Rangos por defecto: "mañana" = 10:00-14:00, "tarde" = 17:00-21:00, "todo el día" = 10:00-21:00
Plurales: "mañanas" → próximas 3 mañanas laborables
Rangos explícitos: "de 10 a 12" → start=10:00, end=12:00, exact=true
Condicionales: "o si no el viernes" → añade viernes como rango alternativo
Redondeo: 10:15 → 10:00-11:00 (bloque de 1 hora)
Filtra fines de semana automáticamente (L-V solamente)
"Media mañana" = 11:00-13:00, "a primera hora" = 10:00-11:00
"Después de comer" = 17:00-19:00
Hoy solo se incluye si quedan ≥2 horas de horario comercial
Fechas relativas: "pasado mañana", "el próximo martes" → resueltas a fecha absoluta
YCBM API (3 llamadas)
Pipeline secuencial de 3 HTTP Requests contra la API de YouCanBookMe. Cada llamada depende de la anterior; no se puede paralelizar:
POST /v1/intents
Envía el subdomain → crea un intent de reserva y devuelve un ID único
GET /v1/intents/{id}/availabilitykey
Con el ID del intent → obtiene la clave de disponibilidad
GET /v1/availabilities/{key}
Con la clave → obtiene todos los slots reales disponibles con timestamps Unix
FilterSlots: El Cruce
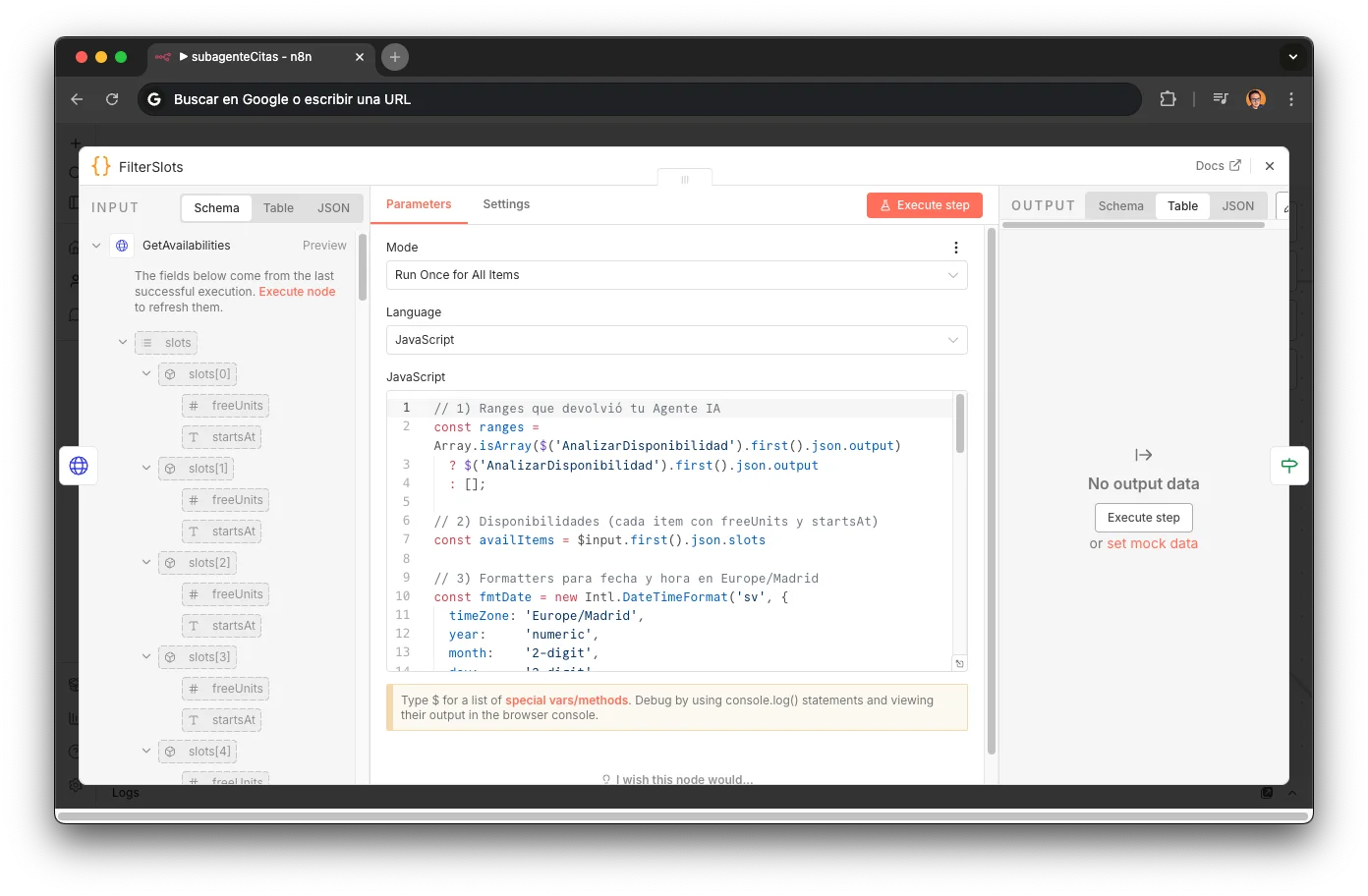
Un nodo Code puro que realiza la intersección de conjuntos: rangos del LLM × slots reales de YCBM. Convierte timestamps Unix a Europe/Madrid usando Intl.DateTimeFormat, luego filtra: localDate === r.date && localTime >= r.start && localTime < r.end. El output es un array [{date, timestamp, start}] que puede contener 0, 1, o N slots. Es el nodo más elegante del workflow: pura lógica de conjuntos, sin LLM, sin API. Solo matemáticas temporales.
Auto-booking Condicional

Un nodo If evalúa slots.length y bifurca en 3 caminos. El sub-agente tiene su propia memoria por sesión: el cliente puede refinar ("no, mejor el jueves") sin empezar de cero.
Confirma automáticamente (zero friction): preparePatchBody construye form data con email, teléfono, queryVars dinámicos y comentarios → emailCheck verifica si tiene email → patchSelections (PATCH /v1/intents/{id}/selections) → patchConfirm (PATCH /v1/intents/{id}/confirm) → confirmarCita informa al cliente
escogerHora agrupa slots por fecha y presenta opciones al cliente con instrucciones contextuales
Informa que no hay disponibilidad en ese rango y pide otra preferencia horaria
El resultado: un cliente escribe "mañana a media mañana" y 3 segundos después tiene una cita confirmada con piezas reservadas. Sin formularios, sin "seleccione fecha en el calendario", sin fricción. Para un FDE, esto es la diferencia entre "hice un chatbot" y "diseñé un sistema que traduce intención humana a acciones de API".

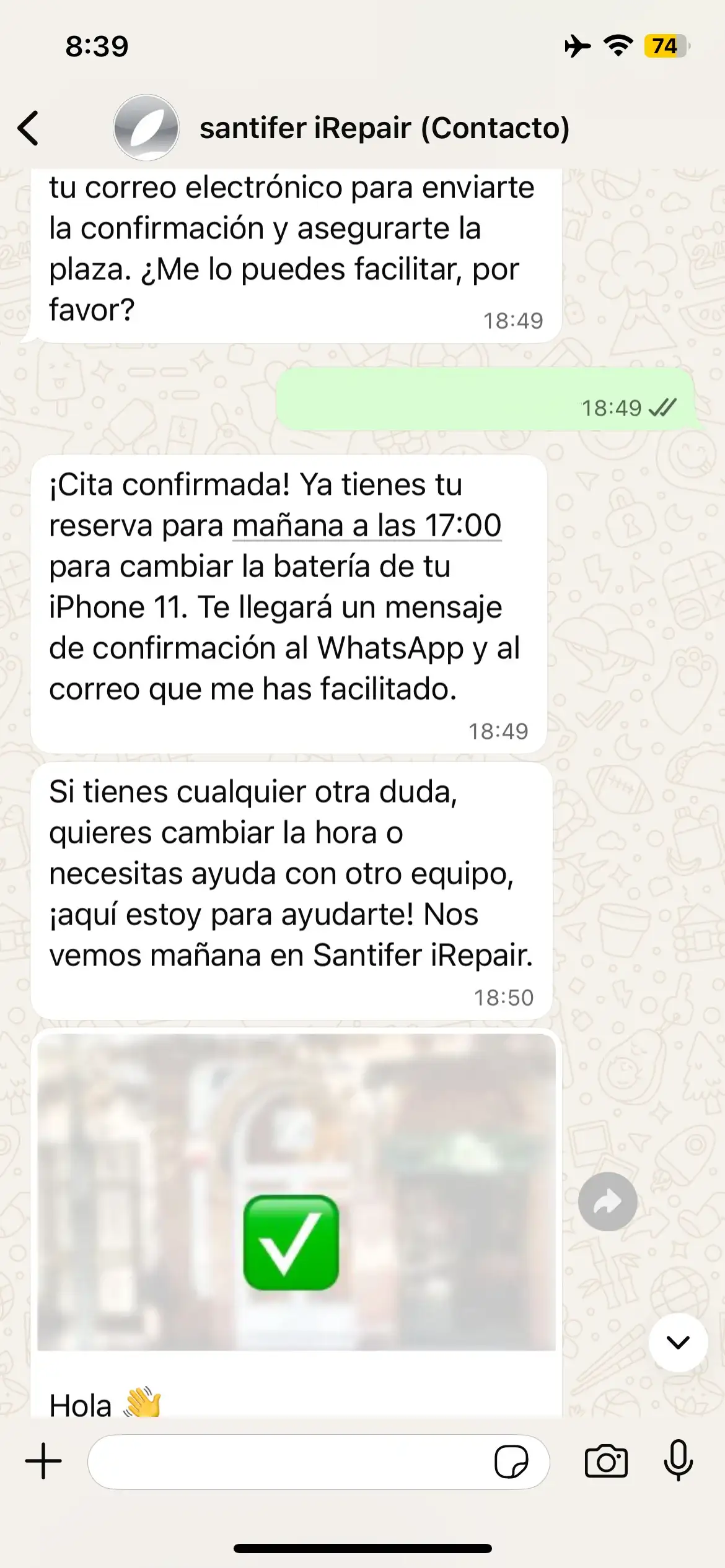

Flujo completo de reserva: el cliente pide cita en lenguaje natural, Jacobo negocia horario, confirma en calendario y envía mensaje de confirmación — todo transparente para el usuario.
System prompt del sub-agente de citas (n8n)
15 reglas de parseo temporal que convierten frases coloquiales en rangos horarios JSON. Este prompt es la pieza clave del sub-agente más sofisticado del sistema: traduce lenguaje natural a timestamps compatibles con la API de YouCanBookMe.
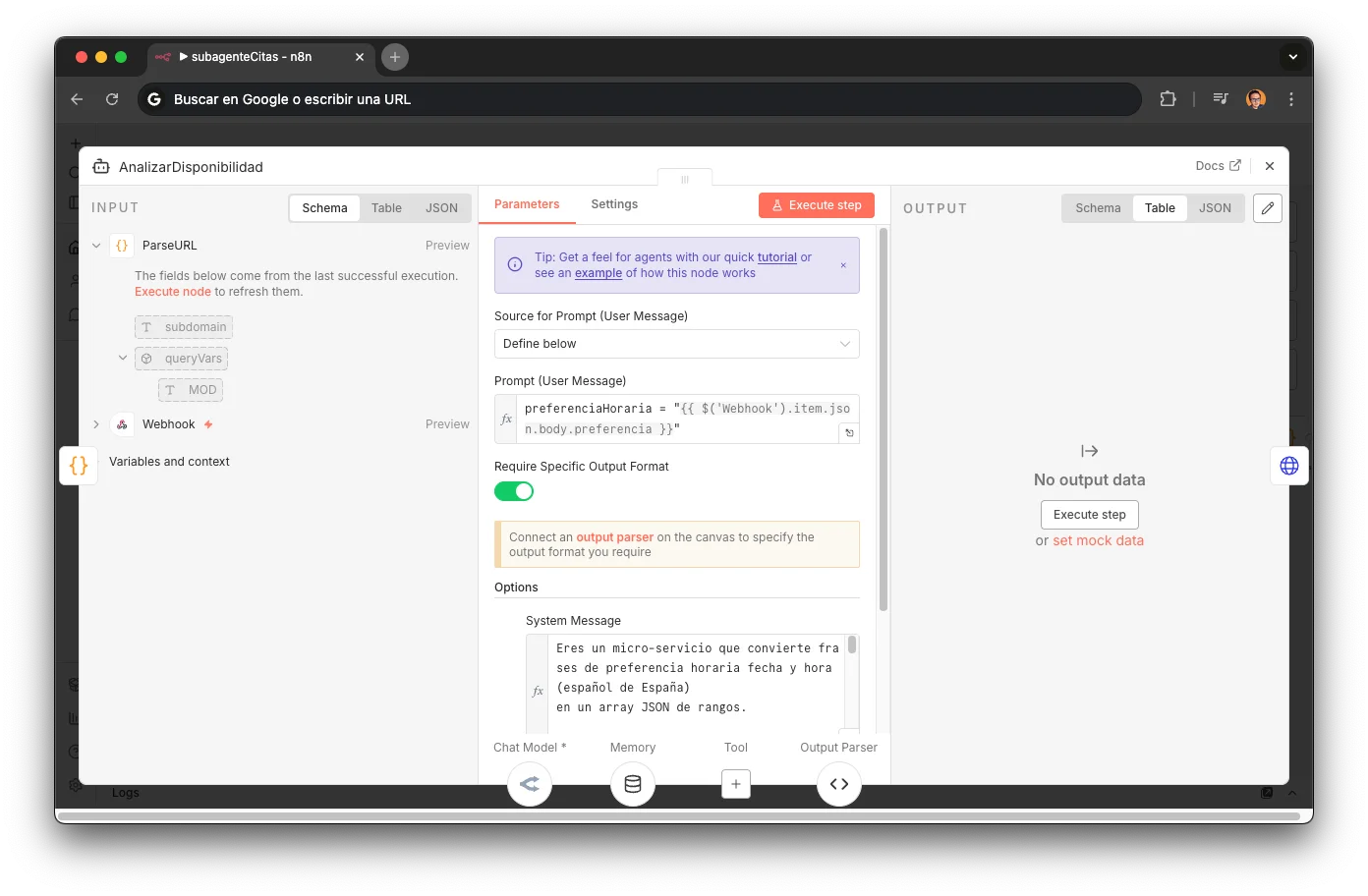
Eres un micro-servicio que convierte frases de preferencia horaria fecha y hora (español de España) en un array JSON de rangos.
Micro-service framing
Darle al LLM el rol de "micro-servicio" en vez de "asistente" acota radicalmente su comportamiento: no saluda, no explica, no pregunta. Solo parsea y devuelve JSON. Reduce alucinaciones al mínimo.
REGLAS DE NEGOCIO 1. Rangos por defecto: – mañana = 10:00-14:00 – tarde = 17:00-21:00 – "todo el día" = 10:00-21:00 2. exact será true solo si el usuario da una hora puntual que termine en 00 o 30 (ej. "lunes a las 10" o "martes a las 17:30" pero no "miércoles a las 10:15"). Si menciona un rango ("martes de 10 a 12") ⇒ exact:false. 3. Horas con minutos ≠ 00 ó 30 se redondean: - Redondea hacia abajo al múltiplo de 30 min anterior. - Crea un rango de 1 hora a partir de esa hora redondeada (ej. 10:15 ⇒ 10:00-11:00, exact:true porque era puntual). 4. La fecha actual es {{ $now.format('yyyy-MM-dd HH:mm') }} (Europe/Madrid). 5. Acepta varias peticiones separadas por "y", comas o punto y coma.
Domain constraints como reglas
Los horarios del negocio, los slots de 30 minutos, el redondeo y la timezone se codifican como reglas explícitas. Sin esto, el LLM inventaba franjas horarias inexistentes o slots de 15 minutos.
6. Devuelve EXCLUSIVAMENTE una llamada de función con esta forma: {"name":"slots","arguments":{"slots":[ {"date":"AAAA-MM-DD","start":"HH:mm","end":"HH:mm","exact":true/false} ]}} 6.1 Si la frase incluye "mañana" sin especificar parte del día, trátalo como «todo el día» de mañana (10:00–21:00).
Structured output forzado
Forzar un JSON schema específico garantiza que el output sea parseable por el siguiente nodo de n8n. "EXCLUSIVAMENTE" es clave: sin esa palabra, el LLM añadía texto conversacional antes del JSON.
7. PLURAL ("mañanas", "tardes"): devuelve las próximas N=3 franjas. Incluye hoy si la franja aún no ha terminado. 8. Solo abre de lunes a viernes. Nunca sábado ni domingo. 9. Conectores condicionales ("o", "o bien", "o si no"): preferencias alternativas en el mismo orden. 10. "A partir de [día]": todo el día (10:00-21:00) + N-1 laborables. 11. N=5 por defecto. 12. Día concreto: solo las horas de ese día. 13. "Esta semana": todas las franjas laborables restantes (Lu-Vi). 14. Plurales: próximas 3 franjas. 15. Sin preferencia horaria: próximos 3 días laborables, todo el día.
Enumeración de edge cases
Cada regla (7-15) cubre un caso real que falló en producción: plurales, conectores condicionales, "esta semana". Sin enumerar explícitamente cada edge case, el LLM interpretaba libremente y generaba slots incorrectos.
# EJEMPLOS Input: "mañana por la mañana" → {"slots":[{"date":"[mañana]","start":"10:00","end":"14:00","exact":false}]} Input: "martes de 10 a 12 y viernes todo el día" → {"slots":[ {"date":"[martes]","start":"10:00","end":"12:00","exact":false}, {"date":"[viernes]","start":"10:00","end":"21:00","exact":false} ]} Input: "lunes a las 10" → {"slots":[{"date":"[lunes]","start":"10:00","end":"11:00","exact":true}]}
Few-shot prompting
3 ejemplos input→output que cubren los 3 escenarios clave: franja genérica (exact:false), multi-slot con "y", y hora exacta (exact:true). Suficientes para anclar el formato sin sobreajustar el comportamiento.
Deep Dive: Sub-agente de Presupuestos#
El sub-agente de presupuestos es el más crítico del sistema: cada consulta de precio pasa por aquí. Usa GPT-4.1 mini vía OpenRouter por su precisión en structured output. Su respuesta determina el siguiente paso del flujo completo.
El reto: del texto libre al presupuesto estructurado
El cliente escribe "cuánto cuesta cambiar la pantalla de un iPhone 15 Pro Max". El router necesita un JSON con precio, stock, URLs de cita y pieza. El sub-agente conecta lenguaje natural con la base de datos de Airtable en tiempo real.

CleanModel: Codificar conocimiento tácito
Los clientes no escriben modelos como una base de datos. Escriben "iphone 15", "iPhone15 pro max", "ip 15 pro", "I-Phone 15Pro Max". Un técnico humano resolvía esto con experiencia: sabía que "el grande negro" probablemente era un Pro Max. Ese conocimiento tácito se pierde si no se diseña para ello.
CleanModel normaliza el input: elimina espacios, paréntesis, guiones y pasa a minúsculas. "iPhone 15 Pro Max" → "iphone15promax". Esto alimenta una búsqueda con SEARCH() en Airtable por campo modeloLimpio (también normalizado), permitiendo fuzzy matching sin depender de escritura exacta.
Este nodo codifica conocimiento tácito de negocio. Sin él, el agente fallaría con la mayoría de inputs reales, porque los clientes no hablan como bases de datos. Es un ejemplo de por qué construir agentes requiere entender el dominio, no solo conectar APIs.
AI Agent: GPT-4.1 mini vía OpenRouter
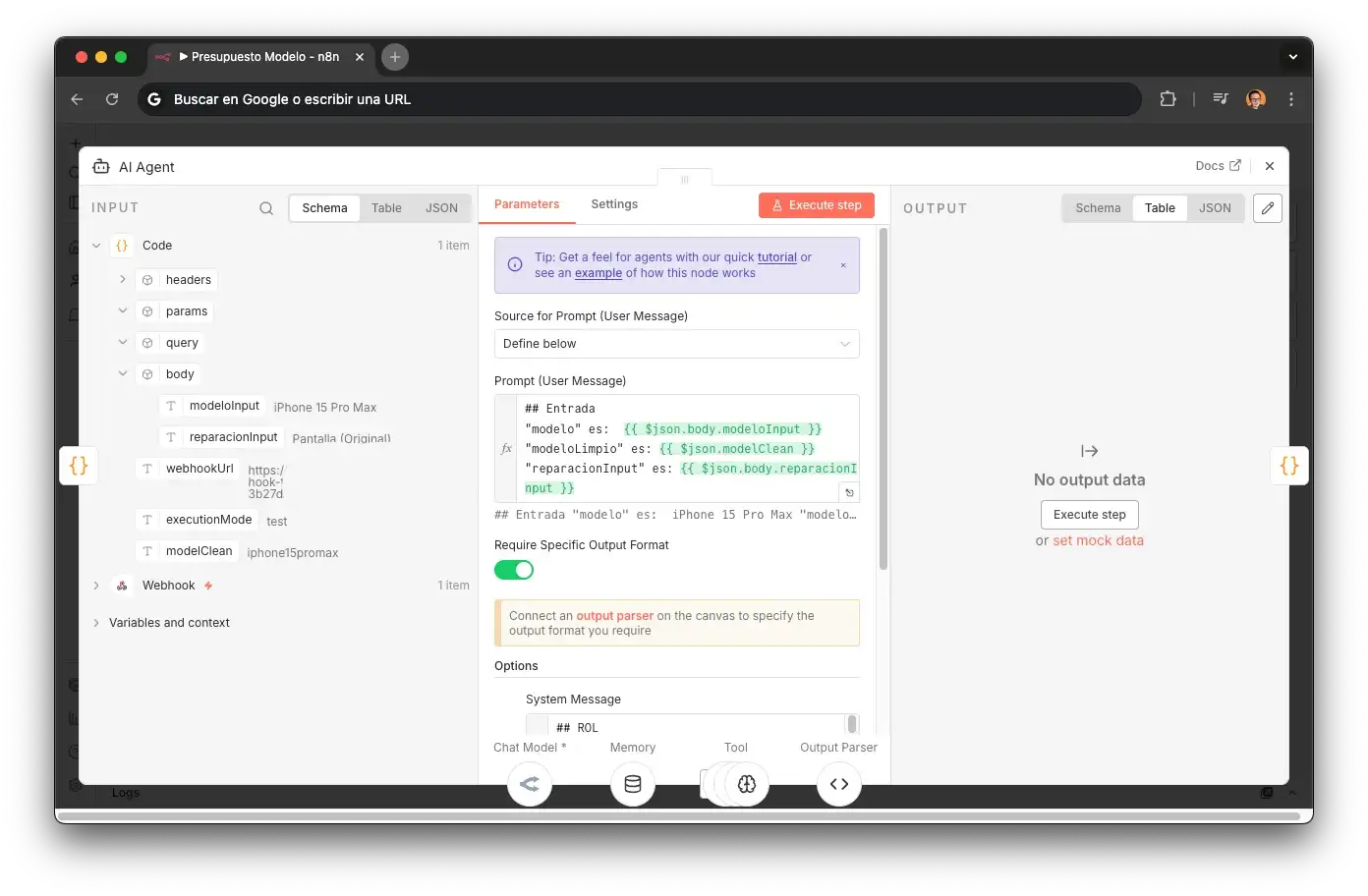
El cerebro del sub-agente. System prompt con ROL ultra-scoped: "agente especializado en buscar precios". Incluye Think tool para razonamiento explícito antes de cada tool call y Simple Memory (buffer window) con sessionKey estática.
BuscarModelo
Busca por campo modeloLimpio en tabla Modelos → devuelve RECORD_ID, Name, URLSantiferNueva, Cita diagnóstico.
BuscarReparacionesModelo
Busca por RECORD_ID → devuelve 20 tipos de reparación con "Precio, stock y cita" (pantalla original, compatible, batería, micrófono, altavoz, puerto carga, cámara trasera/delantera, etc.).
Structured Output Parser
Formatea a JSON con schema: modelo, reparación, precio, stock, urlSantifer, urlCita, urlPresupuesto, urlDiagnostico, idPiezaAirtable, idModeloAirtable.
Si no encuentra coincidencia, el system prompt instruye: "tienes que ir acotando el modelo para obtener más resultados, hasta que te quedes con el que corresponda", replicando el razonamiento de un humano experimentado.
FiltrarRespuesta: Post-procesado determinista
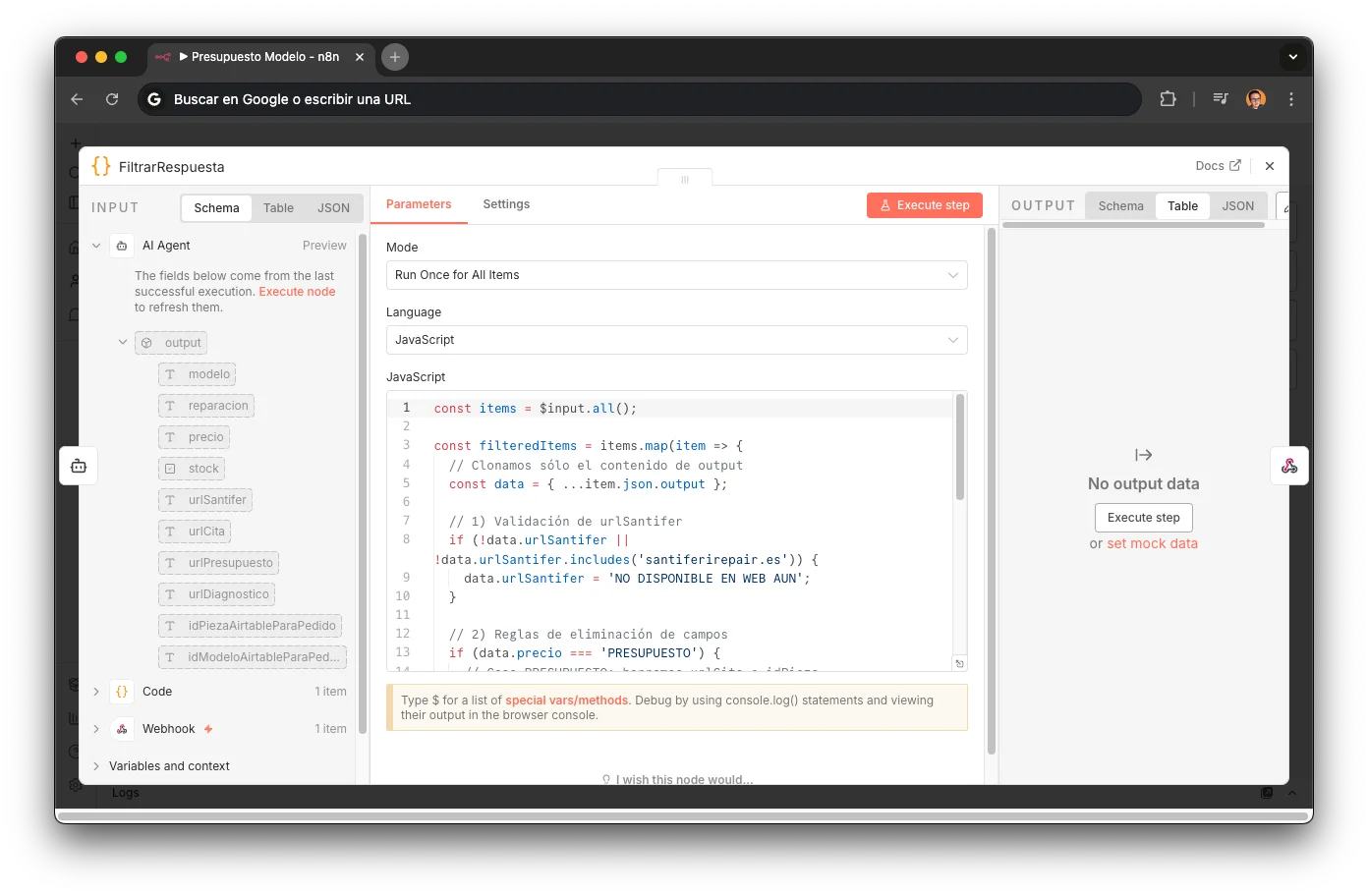
Nodo Code que valida y limpia la respuesta del AI Agent antes de devolverla al router. Valida que urlSantifer apunte al dominio correcto (si no contiene "santiferirepair.es" → "NO DISPONIBLE EN WEB AUN"). Después aplica 3 paths de eliminación de campos según estado:
Elimina urlPresupuesto, idPieza, idModelo: el cliente puede reservar cita directamente.
Elimina urlCita y urlPresupuesto: necesita pedir pieza antes de reparar.
Elimina urlCita e idPieza: la reparación no está catalogada, requiere valoración manual.
El resultado: un cliente pregunta "cuánto cuesta arreglar la pantalla de mi iPhone" y en 4 segundos tiene precio real, disponibilidad de stock y un enlace directo para reservar cita o hacer pedido. Sin formularios, sin "le paso con un compañero". El sub-agente consulta justo los campos imprescindibles de Airtable y devuelve exactamente lo que el router necesita para cerrar la conversión.
System prompt del sub-agente de presupuestos (n8n)
El prompt define tres herramientas (BuscarModelo, BuscarReparacionesModelo, Structured Output Parser) y un flujo de 4 pasos para devolver presupuestos estructurados con estado de stock.
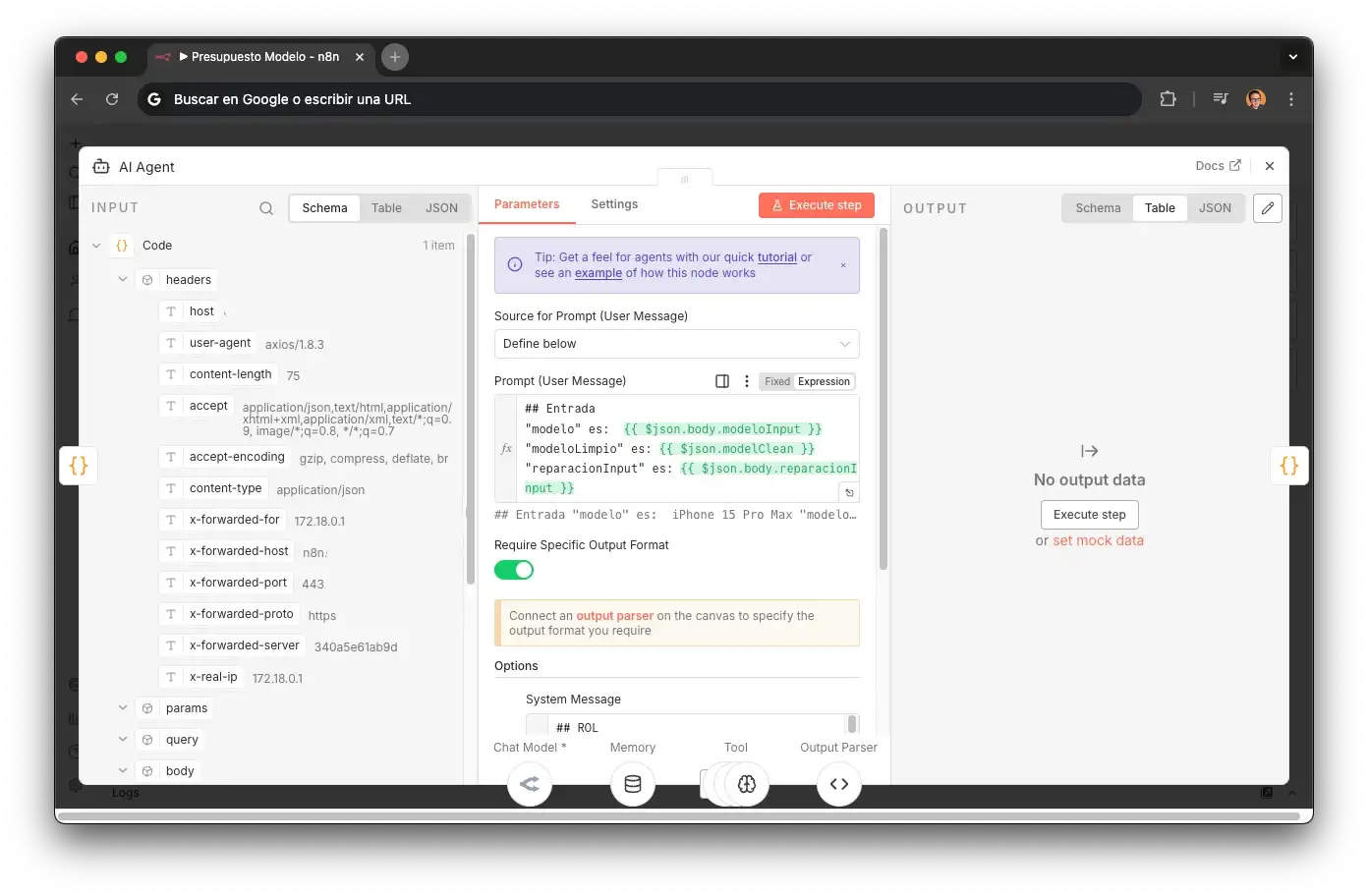
## ROL Eres un sub-agente de presupuestos para Santifer iRepair. Tu trabajo: recibir un modelo y una reparación, buscarlos en Airtable y devolver un presupuesto estructurado.
Scoped sub-agent role
No es un asistente general: es un sub-agente con una única responsabilidad. El scope ultra-estrecho elimina tentaciones del LLM de conversar, sugerir alternativas o añadir contexto no solicitado.
## OBJETIVO Buscar el modelo exacto y la reparación solicitada en la base de datos. Devolver precio, disponibilidad de stock y siguiente paso recomendado.
Single-responsibility objective
Una sola tarea: buscar + devolver presupuesto. El "siguiente paso recomendado" (cita, pedido, presupuesto manual) permite al router principal decidir sin necesidad de otra llamada al LLM.
## HERRAMIENTAS - "BuscarModelo": busca el modelo del dispositivo en Airtable - "BuscarReparacionesModelo": busca reparaciones disponibles para ese modelo - "Structured Output Parser": formatea la respuesta en JSON estructurado
Tool chain pipeline
Las 3 tools forman un pipeline secuencial: buscar modelo → buscar reparaciones → formatear. El Structured Output Parser al final garantiza que el JSON sea consumible por el router sin post-procesado.
## PASOS 1. Recibir modeloInput y reparacionInput del router 2. Llamar a BuscarModelo con modeloLimpio 3. Si encuentra el modelo → llamar a BuscarReparacionesModelo 4. Devolver JSON: precio, stock, tiempo estimado, urlCita, urlPresupuesto
Explicit step sequencing
Orden determinista paso a paso. Sin esto, el LLM a veces saltaba BuscarModelo e intentaba adivinar el precio. Cada paso condiciona al siguiente: no hay ambigüedad sobre qué hacer.
// User message template (n8n inyecta las variables) Modelo: {{ $json.modeloInput }} Modelo limpio: {{ $json.modeloLimpio }} Reparación: {{ $json.reparacionInput }}
Variable injection via template
n8n inyecta modeloInput (lo que dijo el cliente), modeloLimpio (normalizado por el router) y reparacionInput. La separación input/limpio permite al sub-agente buscar con el nombre normalizado sin perder el contexto original del cliente.


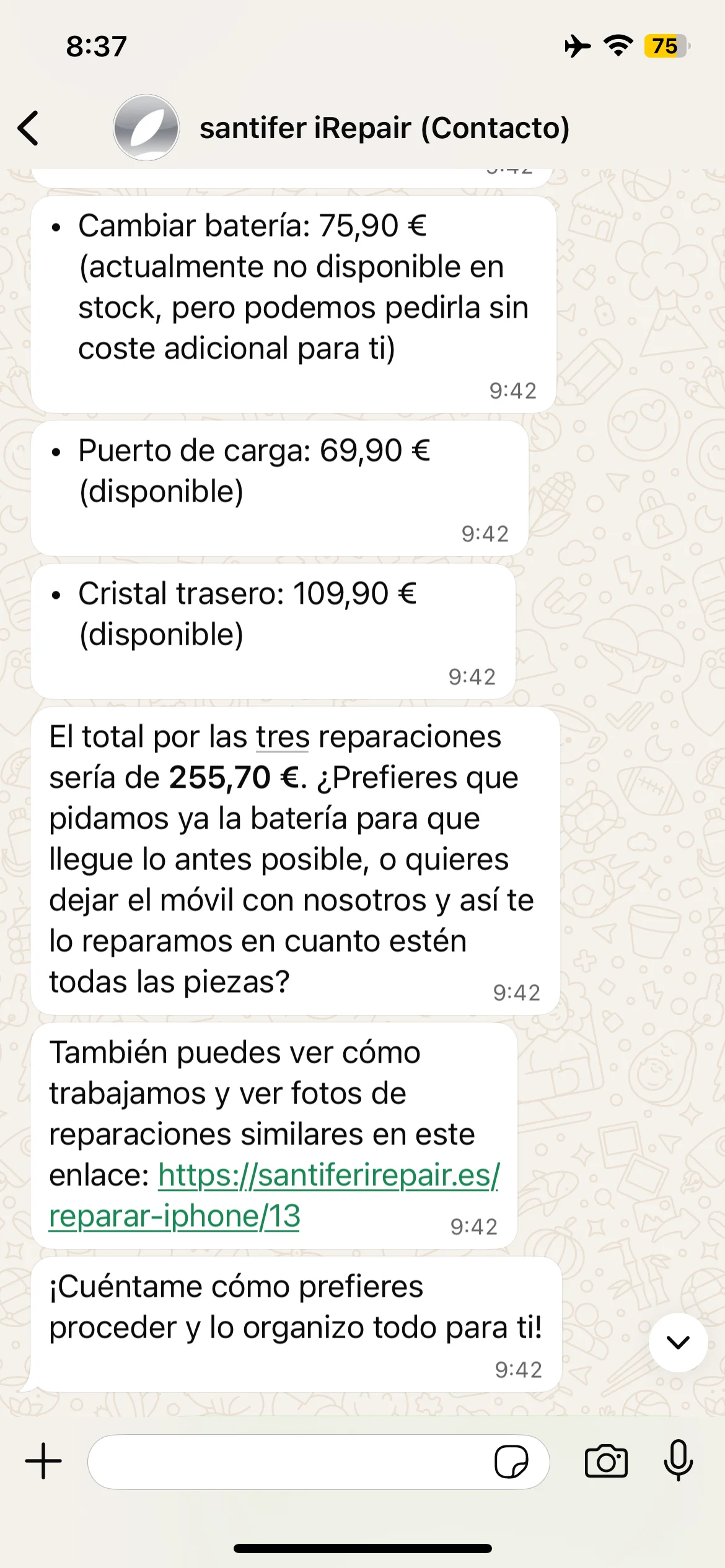
Presupuestos reales: diagnóstico con precio y enlace, presupuesto triple con desglose y total con estado de stock
Deep Dive: Tools#
No todas las piezas del sistema necesitan un LLM. Estas tres tools son workflows ligeros que ejecutan una sola operación cada uno, simples por diseño: la lógica de decisión vive en el router.
hacerPedido: Pedidos Urgentes
Cuando el sub-agente de presupuestos detecta que no hay stock de la pieza, el router invoca hacerPedido. El workflow crea un registro en la tabla "Pedidos" de Airtable con todos los datos necesarios para que el equipo gestione el pedido al proveedor.
Webhook → Airtable Create (tabla Pedidos) → Respond to Webhook
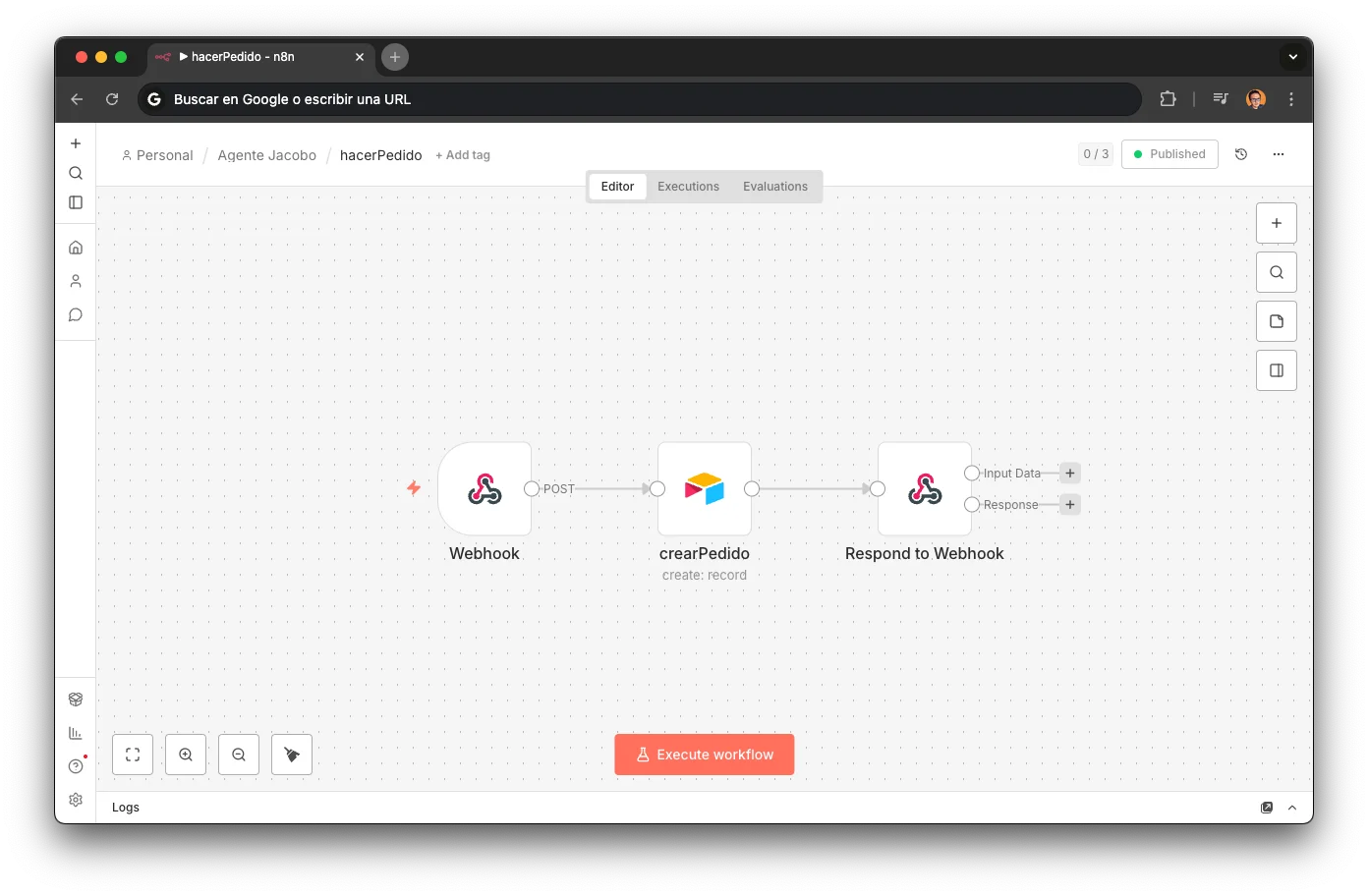
Marca automáticamente "¿Tiene prisa? = SI" porque el cliente está esperando
Vincula idPieza e idModelo para trazabilidad completa en el Business OS
Añade nota "Pedido automatizado por Jacobo" + comentario del cliente
El equipo recibe el pedido en su vista de Airtable sin intervención manual
Calculadora de Descuentos
Lógica pura de negocio, cero LLM. Cuando el cliente necesita varias reparaciones (ej: pantalla + batería + cámara), el router envía un array de precios y la calculadora aplica descuentos escalonados automáticamente.
Webhook → Code (lógica de descuentos) → Response
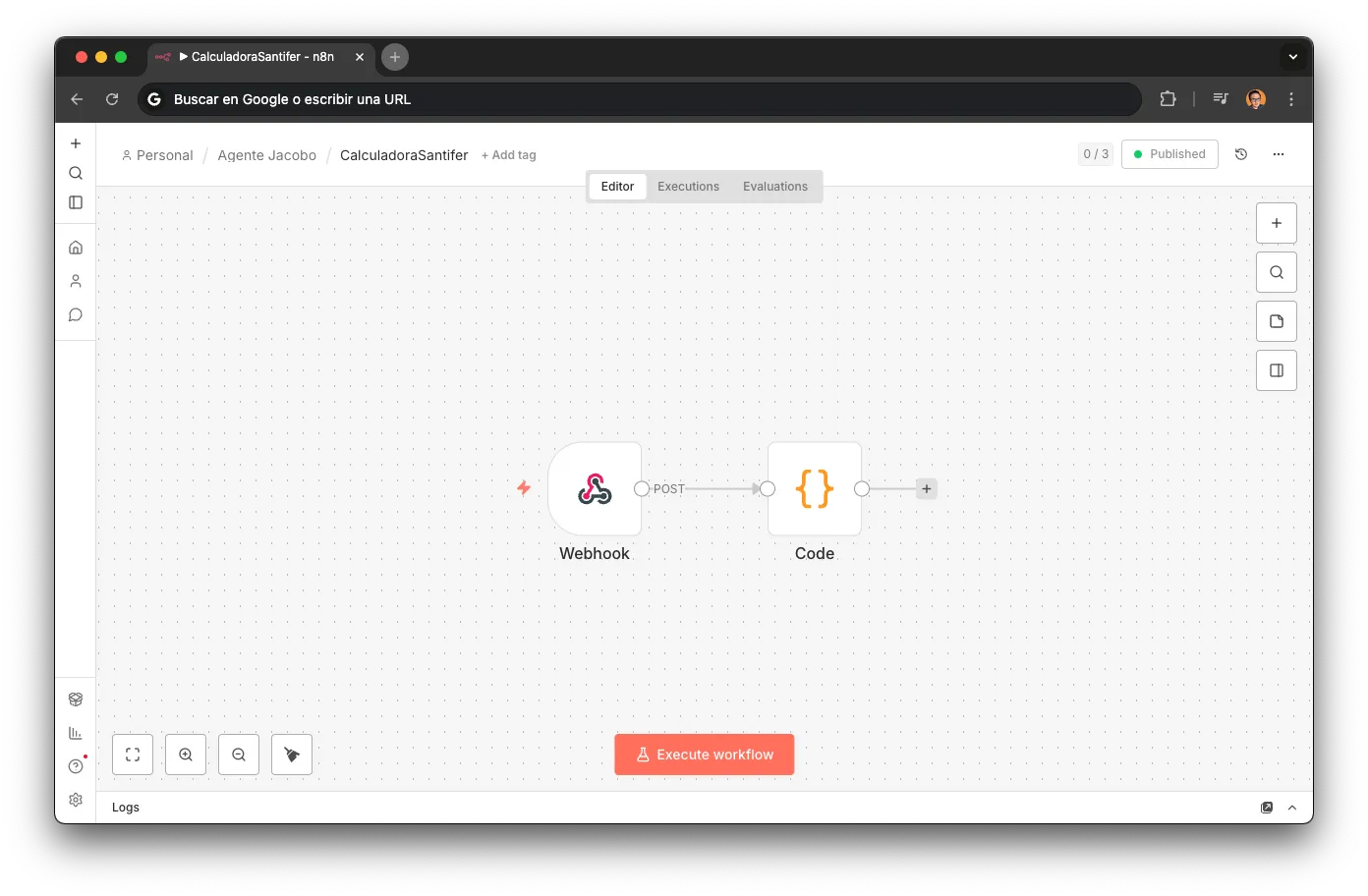
Ordena precios de mayor a menor: la reparación más cara no tiene descuento
Descuento por posición: ≤50€ → 15€ off, ≤100€ → 20€ off, >100€ → 25€ off
Devuelve resumen formateado: precio sin descuento, descuento aplicado, precio final
El cliente ve inmediatamente cuánto ahorra por agrupar reparaciones en una sola visita
const precios = item.json.body.precios; // Validaciones básicas if (!Array.isArray(precios) || precios.length < 2) { throw new Error('Debes enviar un array "precios" con al menos 2 números.'); }
Validación defensiva
El sub-agente no confía en el router: valida que el array exista y tenga al menos 2 precios. Si el LLM envió datos malformados, falla rápido con error descriptivo en vez de devolver NaN.
// 1) Ordenamos de mayor a menor const ordenados = [...precios].sort((a, b) => b - a); // 2) Calculamos descuento por posición (el primero no tiene) const descuentos = ordenados.map((precio, idx) => { if (idx === 0) return 0; // sin descuento para el más caro if (precio <= 50) return 15; if (precio <= 100) return 20; return 25; // >100 € });
Reglas de negocio como código, no como prompt
Los descuentos viven en un nodo Code, no en un prompt. Esto garantiza determinismo: una pantalla de 189€ + batería de 45€ siempre da exactamente el mismo descuento. Cero alucinaciones posibles.
// 3) Totales const totalSinDescuento = ordenados.reduce((s, p) => s + p, 0); const descuentoTotal = descuentos.reduce((s, d) => s + d, 0); const totalConDescuento = totalSinDescuento - descuentoTotal; // 4) Preparar respuesta const resumen = `Presupuesto total sin descuento: ${totalSinDescuento.toFixed(2)} € Descuento aplicado: ${descuentoTotal.toFixed(2)} € Presupuesto reparándolo todo junto: ${totalConDescuento.toFixed(2)} €`;
Respuesta formateada para el router
El resumen en texto plano lo recibe el router y lo pasa directamente al cliente. El LLM no reformula: copia el texto tal cual. Así el precio que ve el cliente es exactamente el que calculó el código.
HITL Handoff: Escalada a Humano
La válvula de escape del sistema. Cuando Jacobo detecta que no puede resolver (cliente frustrado, caso complejo, petición fuera de scope), escala a un humano vía Slack con contexto completo.
Webhook → Slack (#chat) → Respond to Webhook

Publica en el canal #chat con emoji 🤖 como avatar
El mensaje incluye: resumen de la conversación, intent detectado e historial del cliente
Deep-link directo a la conversación en WATI: el humano abre y ya tiene todo el contexto
Jacobo confirma al cliente que un humano le contactará, sin cortar la conversación
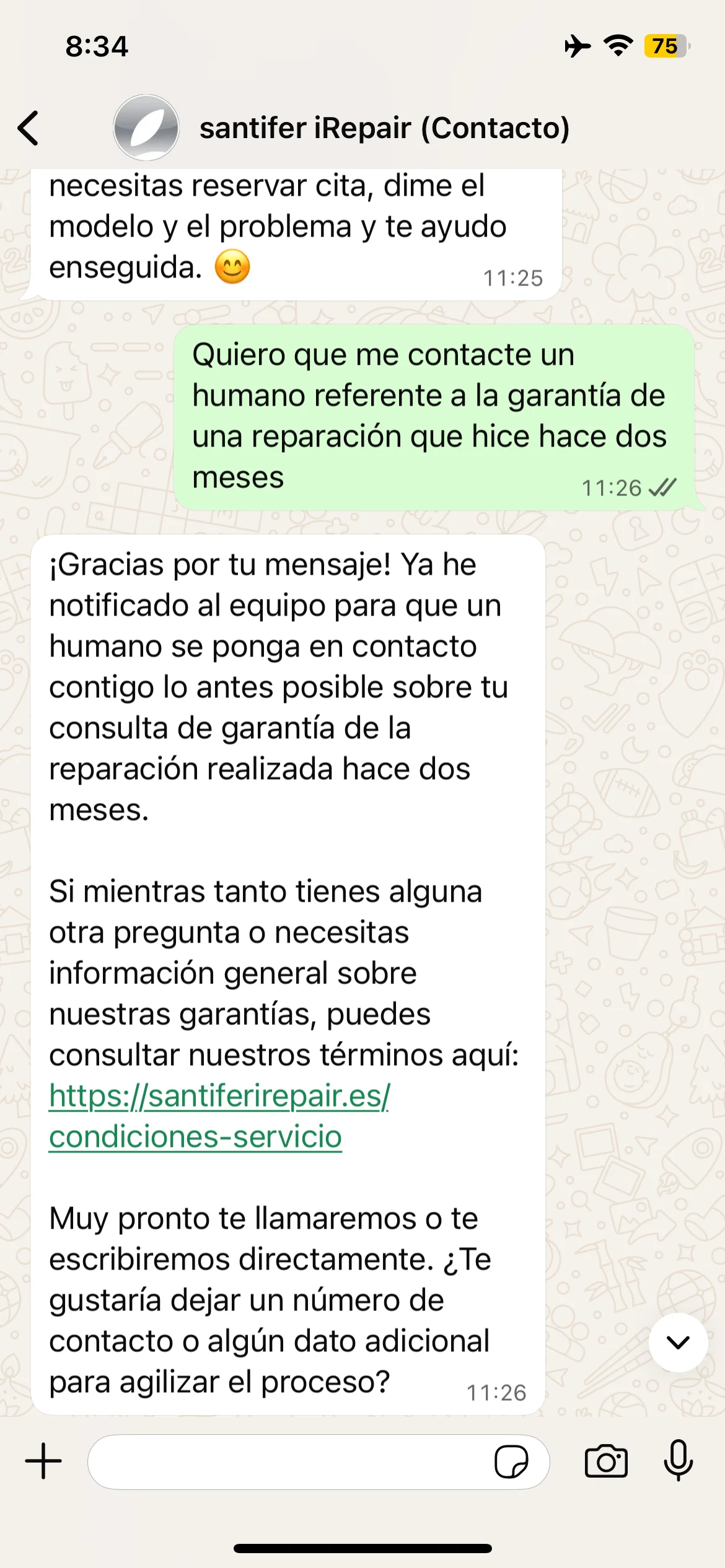

Cuando Jacobo escala a humano, llega un mensaje al canal #chat de Slack con el contexto completo de la conversación
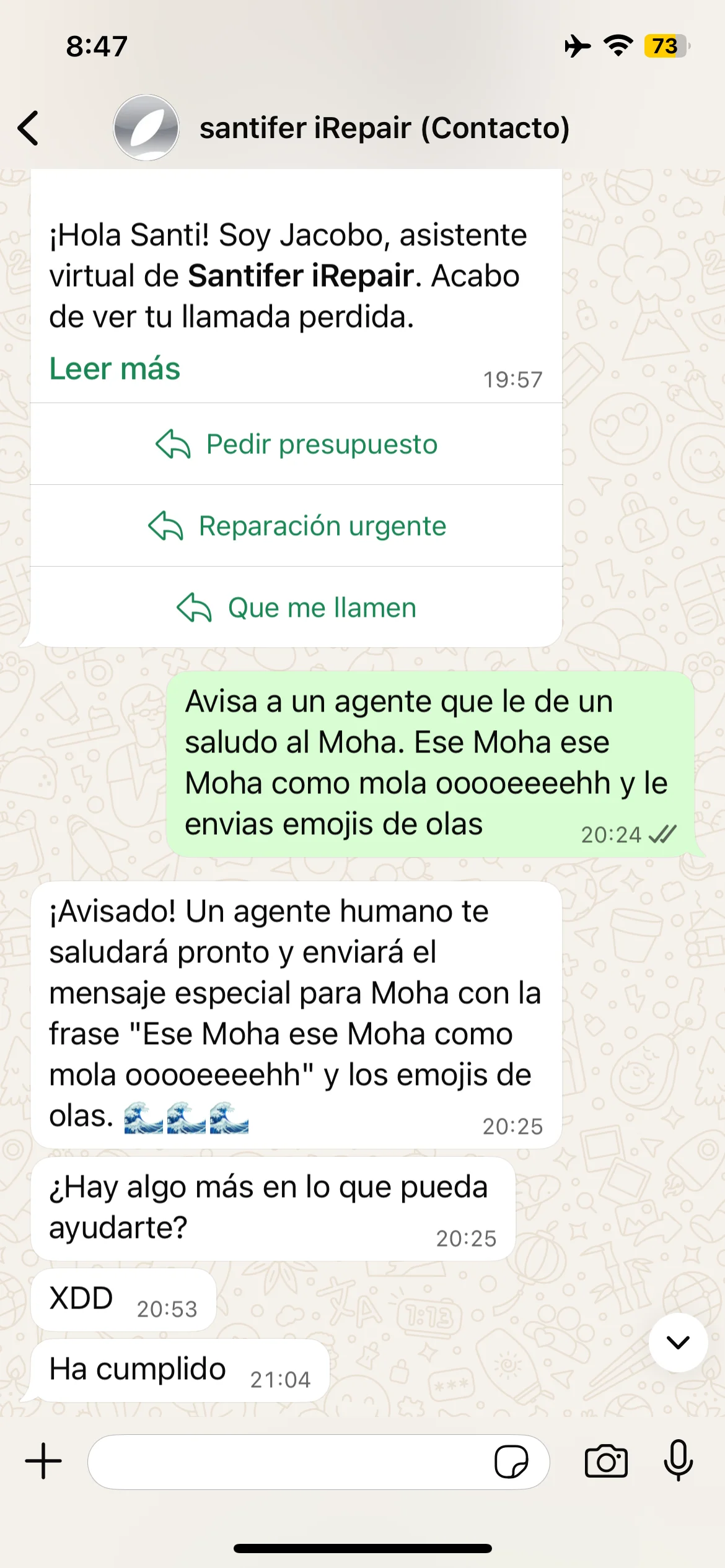

Edge cases reales: petición absurda, pedido masivo rechazado, escalada por frustración y respuesta ante emergencia falsa con redirección al 112
EnviarMensajeWati: Cross-Channel
El puente entre canales. Cuando el cliente habla por teléfono con Jacobo (ElevenLabs), este workflow envía enlaces y confirmaciones por WhatsApp en paralelo. El cliente recibe la info por escrito mientras sigue hablando.
Webhook → HTTP Request (API WATI) → Respond to Webhook
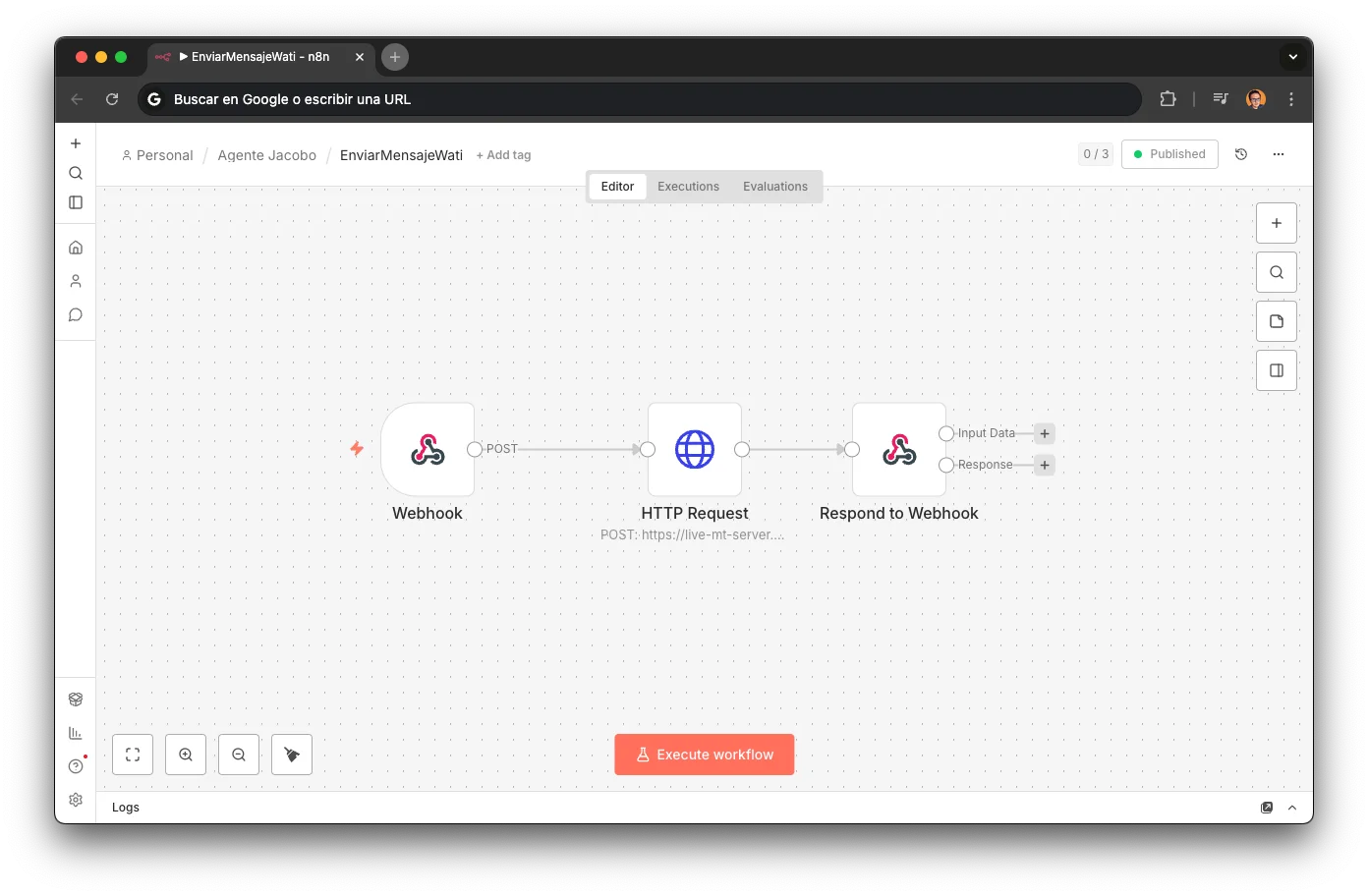
Envía template "urlreparacion2" con la URL de cita personalizada
Permite que el agente de voz diga "te acabo de enviar el enlace por WhatsApp"
El cliente no necesita apuntar nada: cuando cuelga, la info ya está en su móvil
Resultados#
Métricas de producción tras 6 meses operando (los workflows son descargables al final para verificar la arquitectura):


~90%
Autoservicio
Consultas resueltas sin intervención humana
24/7
Disponibilidad
Sin limitación de horario de tienda
<30s
Tiempo de respuesta
Vs. minutos cuando dependía de una persona
<200€
Coste mensual
Infraestructura total (n8n + WATI + Aircall + LLMs)
Antes vs Después
| Área | Antes | Después |
|---|---|---|
| Consultas de precio/stock | ~15 interrupciones/día al técnico | Jacobo responde con datos reales de Airtable en <30s |
| Reserva de citas | Manual por teléfono, errores de horario frecuentes | Automático vía YouCanBookMe, piezas auto-reservadas |
| Fuera de horario | Consultas perdidas, clientes a la competencia | Jacobo atiende 24/7 por WhatsApp y teléfono fijo |
| Escalaciones a humano | El humano empezaba de cero, repitiendo preguntas | Handoff con contexto completo, resolución en segundos |
| Coste de atención al cliente | Empleado part-time ~800-1.000€/mes | <200€/mes total infraestructura |
El ROI no es solo el ahorro directo. Es la disponibilidad 24/7, las citas que antes se perdían fuera de horario, y los técnicos que ahora reparan en vez de contestar preguntas.
Benchmark de industria: los contact centers enterprise promedian un 20-30% de resolución por IA (Gartner, 2025 AI Customer Service Report). Los asistentes virtuales más avanzados alcanzan un 15% (Gartner, 2025 Hype Cycle for Customer Service & Support Technologies). Jacobo logró ~90% en un dominio especializado. La diferencia: sub-agentes con acceso a datos en tiempo real vs chatbots genéricos.
Jacobo sigue operando 24/7 bajo nuevo dueño desde septiembre de 2025. El comprador lo adquirió funcionando. La mejor prueba de un sistema: funciona sin su creador. Los patrones de arquitectura documentados aquí son los mismos que llevaría a tu equipo.
Los mismos datos de Airtable generaron 4.700+ páginas SEO
El inventario que Jacobo consulta en tiempo real también alimenta un sistema de SEO programático: 4.730 landing pages con precios reales, fotos de reparaciones y reseñas verificadas.
¿Buscas a alguien que construya esto para tu empresa?
Jacobo gestiona citas, consulta inventario real y escala con contexto, todo en menos de 30 segundos. La arquitectura de sub-agentes, tool calling y patrones HITL se aplica directamente a travel, fintech, salud o e-commerce.
Decisiones Técnicas (ADRs)#
Cada decisión técnica tiene un porqué. Estas son las más importantes:
Multi-model (GPT-4.1 + MiniMax + GPT-4.1 mini) vs single LLM
Cada componente con el modelo justo: GPT-4.1 para el router principal y el agente de voz (tool calling preciso), GPT-4.1 mini para presupuestos (structured output), MiniMax M2.5 para citas (rápido y barato para parsear preferencias temporales). OpenRouter como gateway permite cambiar entre modelos sin reescribir workflows.
OpenRouter como gateway model-agnostic
Cambiar entre modelos sin reescribir workflows, fallback automático si un modelo está caído. Evaluamos Claude, GPT-4, MiniMax: elegimos por caso de uso, no por marca.
n8n vs Make para orquestación
Cada sub-agente es un workflow independiente con webhook propio. Make no permite esta modularidad. n8n permite LangChain agent patterns, memory management y tool calling nativo.
Sub-agentes como microservicios webhook
Desacoplados, testeables individualmente, deployment independiente. El mismo sub-agente sirve a WhatsApp (vía n8n) y a teléfono (vía ElevenLabs) sin duplicar código.
Airtable como cerebro vs base de datos
Ya existía el Business OS completo en Airtable (12 bases, 2.100+ campos). Single source of truth para stock, precios e historial de clientes. Construir sobre lo que ya existe, no duplicar.
Memory window: 20 mensajes por sesión
Balance entre contexto y coste de tokens. Suficiente para una conversación de reparación (el 95% se resuelve en <10 mensajes). Keyed por número de teléfono para continuidad.
Think tool para razonamiento interno
Razonamiento explícito antes de cadenas multi-tool. Reduce errores porque el LLM planifica la secuencia (consultar precio → verificar stock → ofrecer cita) antes de ejecutar.
HITL vía Slack con motivo de escalado
El LLM genera el motivo de la escalación y lo incluye en el mensaje de Slack: por qué necesita intervención humana, qué ha intentado y qué necesita el cliente. Funciona igual desde WhatsApp (deep-link a WATI) y desde llamada telefónica. El humano sabe por qué se le necesita antes de abrir la conversación.
WhatsApp primero, voz después
El 70% del volumen llegaba por WhatsApp. Empezar ahí maximizó el impacto antes de expandir a voz. La voz (ElevenLabs + Aircall) reutilizó los sub-agentes existentes.
Dual-orquestador con sub-agentes compartidos
n8n para WhatsApp/web, ElevenLabs para voz. Los sub-agentes son webhooks platform-agnostic. Reutilizables por cualquier orquestador sin duplicar lógica. Patrón de microservicios real.
ElevenLabs como "compañero" en Aircall
Jacobo integrado en PBX con routing rules: entra por overflow o fuera de horario. El cliente llama a un teléfono fijo, experiencia transparente. eleven_flash_v2_5 con temp 0.0 para máxima consistencia.
Aircall → Twilio → ElevenLabs (y el trade-off de latencia)
La cadena Aircall PBX → Twilio (bridge telefónico) → ElevenLabs funcionaba, pero cada hop añadía latencia: ~950-1.500ms mouth-to-ear. Twilio usa G.711 a 8kHz, cuando los modelos STT están optimizados para 16kHz, forzando resampling con pérdida de precisión. Hoy elegiría SIP trunk directo (Telnyx ofrece G.722 wideband a 16kHz nativo e infraestructura co-located con sub-200ms RTT) eliminando el hop intermedio. El diseño platform-agnostic de los sub-agentes facilitaría esta migración: solo cambiaría el transporte, no la lógica.
Evolución de la Plataforma#
Jacobo no fue una ocurrencia. Fue la consecuencia inevitable de 5 años construyendo un Business OS robusto debajo.
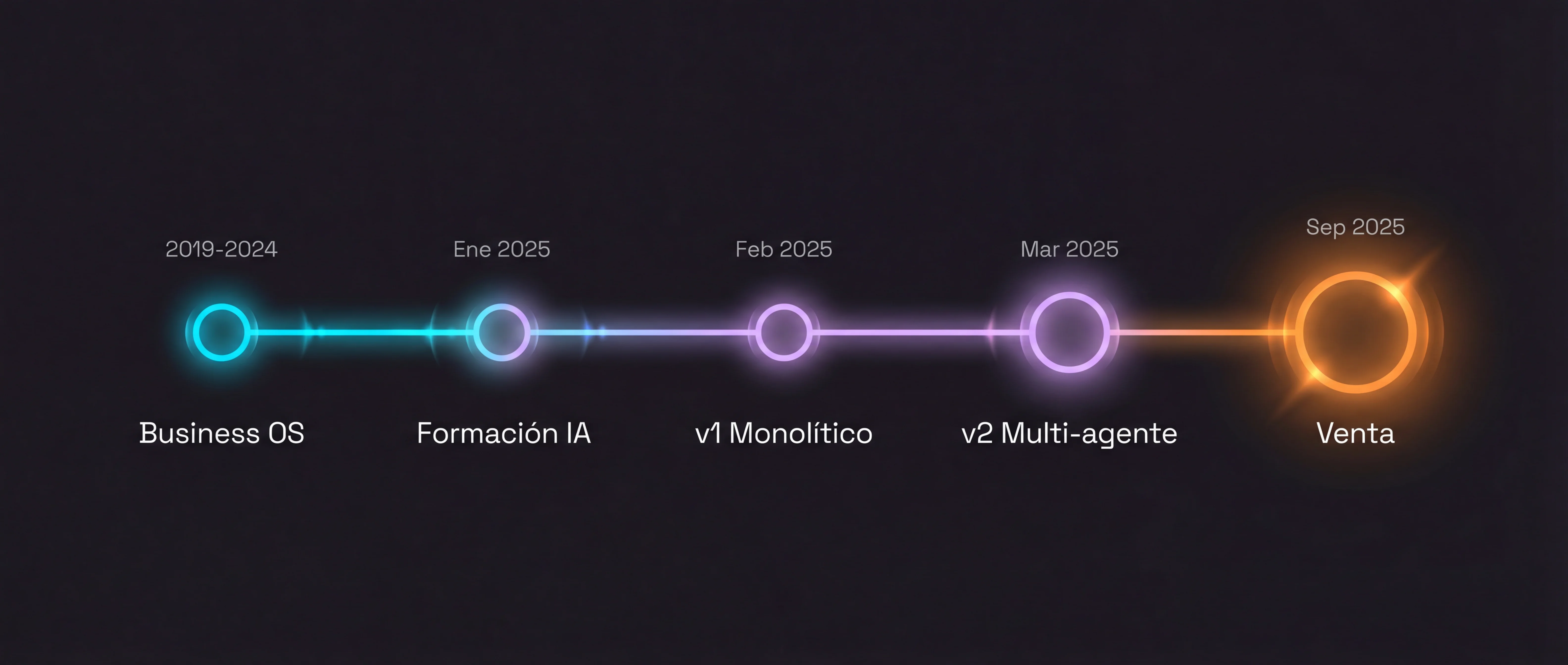
2019-2024
Business OS como base
Cinco años construyendo un sistema operativo de negocio completo en Airtable: 12 bases, 2.100+ campos, inventario en tiempo real, CRM con historial de clientes. Sin esta base de datos limpia y accesible, un agente IA sería un chatbot genérico que inventa respuestas.
Ene 2025
Formación y diseño deliberado
Antes de escribir una línea, me formé en arquitecturas de agentes IA. Sabía que necesitaba tool calling, que Airtable era el SSOT, y que el agente tenía que ser multimodal: voz y chat compartiendo los mismos recursos.
Feb 2025
Primera versión de prueba (monolítica)
Probé el enfoque de un solo prompt con mucho contexto y confirmé lo que intuía: un prompt monolítico no escala con múltiples dominios. La prueba validó la decisión de sub-agentes como webhooks, platform-agnostic por diseño.
Feb 2025
Versión definitiva multi-agente
Mi primer agente IA, en producción en menos de un mes. Arquitectura de sub-agentes completa: cada dominio en su propio workflow con webhook independiente, router central con tool calling, multi-model por caso de uso. La velocidad se debe al Business OS que ya existía debajo. Todo en paralelo a las demás responsabilidades del negocio.
Mar 2025
Canal de voz (Aircall + Twilio + ElevenLabs)
Jacobo como compañero en la centralita Aircall, conectado vía Twilio a ElevenLabs. Reutilizó los sub-agentes existentes sin duplicar lógica. Validación del diseño platform-agnostic: los webhooks sirvieron a un segundo orquestador sin tocar una línea.
Sep 2025
Going-concern sale
Jacobo lleva activo 24/7 desde su lanzamiento. Formó parte de la venta del negocio como activo operativo: el comprador lo adquirió funcionando. Cinco años de arquitectura limpia lo hicieron inevitable.
Jacobo no fue un experimento.
16 años construyendo un negocio con mis manos.
Sistematizarlo hasta que funcionara sin mí.
Jacobo fue la pieza que cerró el ciclo.
Vendí el negocio como empresa en marcha.
Los sistemas siguen operando hoy — bajo nuevo dueño.
Business OS — El sistema detrás de Jacobo
Jacobo se construyó sobre el Business OS que diseñé durante 5 años. Lee el case study completo →


Los primeros momentos de vida de Jacobo: pruebas de endpoints, iteración del copy de fidelización y el template CRM final
Lecciones Aprendidas#
Sub-agentes > un prompt monolítico.
Durante el diseño, probé un prompt con todo el contexto y confirmé que no escala con múltiples dominios. La arquitectura de sub-agentes fue una decisión deliberada desde el principio: cada pieza testeable, iterable e independiente. Un cambio en descuentos no puede romper las citas. Es la misma lógica que los microservicios, aplicada a agentes IA.
HITL no es un fallback, es una feature.
El handoff humano bien hecho genera más confianza que un bot que intenta resolver todo. Los clientes valoran que el sistema sepa cuándo necesitan a una persona. El truco: que el humano no empiece de cero.
El CRM es el cerebro del agente, no el LLM.
Jacobo no es inteligente por el modelo de lenguaje. Es inteligente porque consulta precios, stock e historial de clientes en Airtable. Sin esos datos, es un chatbot genérico que inventa respuestas.
Empieza por el canal de mayor volumen.
WhatsApp representaba el 70% de las consultas. Empezar ahí maximizó el impacto. Cuando añadimos voz, los sub-agentes ya estaban probados y solo hubo que conectar un orquestador nuevo.
Los modelos se eligen por caso de uso, no por marca.
GPT-4.1 para el router y voz (tool calling preciso), GPT-4.1 mini para presupuestos (structured output), MiniMax M2.5 para citas (rápido y económico). OpenRouter como gateway permite cambiar sin reescribir. Esto es más FDE que decir "uso X para todo".
El Think tool previene errores en cadenas multi-tool.
Antes de consultar precio → verificar stock → ofrecer cita, el agente explicita su plan. Un paso de razonamiento explícito reduce errores en la secuencia. Es como el "rubber duck debugging" pero para el propio agente.
Qué Haría Diferente#
Jacobo funcionó en producción durante meses, pero con perspectiva hay decisiones que cambiaría:
Evaluación estructurada desde el día 1
Implementé evals post-hoc cuando el sistema ya estaba en producción. Si empezara de nuevo, definiría métricas de calidad de respuesta, intent classification accuracy y HITL rate antes de la primera versión. Retrofitear observabilidad es más costoso que diseñarla desde el inicio.
SIP trunk directo en vez de Aircall → Twilio → ElevenLabs
La cadena de 3 hops añadía ~950-1.500ms de latencia mouth-to-ear y forzaba resampling de G.711 (8kHz) a 16kHz. Con Telnyx SIP trunk directo a ElevenLabs, tendría G.722 wideband nativo y sub-200ms RTT. Elegí la cadena larga porque Aircall ya estaba contratado; hoy priorizaría latencia sobre conveniencia.
Vector store para memoria en vez de fetch bruto de WATI
El fetch de 80 mensajes desde WATI funciona, pero no escala a clientes con historial largo ni permite búsqueda semántica. Un vector store (Pinecone, Qdrant) con embeddings de conversaciones permitiría "recuerda aquella vez que trajiste el iPhone 12" sin cargar toda la conversación.
Patrones Transferibles a Enterprise#
Jacobo se construyó para una PYME, pero los patrones de arquitectura son enterprise-grade. Esto es lo que construí vs. lo que añadiría a escala enterprise:
| Patrón | Lo que construí | Enterprise |
|---|---|---|
| Sub-agent routing con tool calling | Router + 7 sub-agentes webhook con intent classification y delegation | Añadir circuit breakers, retry policies y fallback a modelo alternativo por sub-agente |
| Multi-model orchestration | GPT-4.1 (router/voz) + GPT-4.1 mini (presupuestos) + MiniMax (citas) vía OpenRouter | A/B testing de modelos por sub-agente, canary deployments de nuevas versiones de prompts |
| HITL framework | Escalado vía Slack con contexto completo y deep-link a la conversación | Queue management, SLAs por tier de cliente, analytics de razones de escalado |
| Platform-agnostic sub-agents | Webhooks compartidos entre n8n (WhatsApp) y ElevenLabs (voz) | API gateway, rate limiting, autenticación, versionado de endpoints |
| Observabilidad | Logs de n8n + alertas de Slack | Langfuse/Datadog para traces, latencia y cost tracking por conversación |
| Infraestructura de voz | Aircall → Twilio → ElevenLabs: funcional, pero cada hop añade latencia (~950-1.500ms mouth-to-ear). Twilio usa G.711 a 8kHz, requiere resampling a 16kHz para los modelos de STT, degradando precisión | SIP trunk directo (Telnyx/Plivo) → ElevenLabs vía SIP, eliminando el hop de Twilio. Telnyx ofrece G.722 wideband a 16kHz nativo (sin resampling) e infraestructura co-located (GPU + telefonía en el mismo PoP) con sub-200ms RTT. Para apps/web: WebRTC directo (Opus 16-48kHz) vía LiveKit, sin PSTN, con 300-600ms mouth-to-ear |
Aplicabilidad por industria
Travel (Hopper, Booking)
Sub-agentes para vuelos, hoteles, seguros. HITL para cambios complejos. Tool calling contra availability APIs.
Fintech
Sub-agentes para transacciones, consultas de saldo, soporte. Stock-aware routing → balance-aware routing.
Healthcare
Sub-agentes para citas, resultados, triage. HITL como feature crítica para derivación a especialista.
E-commerce
Sub-agentes para tracking, devoluciones, recomendaciones. Los mismos patrones de inventory lookup y booking.
Plataformas de Voice AI
Orquestación de agentes conversacionales con latencia optimizada. Los patrones de cross-channel (voz → texto) y HITL aplican directamente a cualquier plataforma de voz.
Plataformas de Datos/AI
Tool calling contra APIs internas, routing de sub-agentes por intent, memory management. La misma arquitectura escala a cualquier orquestador de agentes.
Estos patrones escalan. Listos para producción enterprise.
Jacobo gestiona citas, consulta inventario real y escala con contexto, todo en menos de 30 segundos. La arquitectura de sub-agentes, tool calling y patrones HITL se aplica directamente a travel, fintech, salud o e-commerce.
Pruébalo Tú Mismo#
Estos son los workflows reales que corren en producción desde hace 2 años. Sanitizados, documentados, listos para importar en n8n. Si construyes algo con ellos, me encantaría verlo.
Jacobo Chatbot V2
Central Router
El cerebro del canal WhatsApp. Clasifica intent, elige sub-agente, mantiene ventana de memoria de 20 mensajes.
subagenteCitas
Appointment Booking
Convierte "mañana por la mañana" en una cita confirmada. Parsea preferencias temporales en lenguaje natural.
Presupuesto Modelo
Quote Agent
Busca modelo y reparación en Airtable, devuelve precio real con estado de stock.
hacerPedido
Order Creation
Crea órdenes de reparación en Airtable cuando la pieza no tiene stock.
CalculadoraSantifer
Discount Calculator
Lógica pura de negocio. Calcula descuentos combo cuando el cliente agrupa varias reparaciones.
contactarAgenteHumano
HITL Handoff
La válvula de escape. Escala a humano vía Slack con deep-link directo a la conversación.
EnviarMensajeWati
WhatsApp Sender
Puente cross-channel: el agente de voz envía mensajes por WhatsApp vía la API de WATI.
Todos los workflows están en GitHub: haz fork, dale star, o descarga directamente.
Cómo importar en n8n
Abre tu instancia de n8n y ve a Workflows
Click en "..." → "Import from file"
Selecciona cualquier archivo .json de la descarga
Actualiza las credenciales (API keys, webhooks) con tus propios valores
Preguntas Frecuentes#
¿Cuánto cuesta construir un agente IA para WhatsApp?
Las herramientas (n8n cloud, WATI, Aircall, LLMs vía OpenRouter) cuestan en total menos de 200€/mes. El coste principal es el tiempo de diseño y desarrollo de la arquitectura. Para un negocio de este tamaño, es una fracción del coste de un empleado a tiempo parcial dedicado a atención al cliente.
¿Qué pasa si la IA se equivoca con un precio?
Los precios no vienen del LLM: vienen de Airtable. Jacobo consulta el inventario en tiempo real. Si el precio cambia en Airtable, Jacobo da el precio correcto automáticamente. No hay alucinación posible en datos estructurados.
¿Cómo funciona el agente de voz por teléfono?
Jacobo está integrado en la centralita Aircall como un "compañero" más. Entra cuando nadie puede atender o fuera de horario. El cliente llama a un teléfono fijo y habla con Jacobo con voz natural (ElevenLabs). Usa los mismos sub-agentes webhook que WhatsApp: misma lógica, diferente interfaz.
¿Por qué n8n y no LangChain/LangGraph directamente?
n8n permite que cada sub-agente sea un workflow visual con webhook propio, testeable con una llamada HTTP. La barrera de mantenimiento es menor que un repo de Python. Para la complejidad de este sistema (7 workflows, ~80 nodos), la visualización de n8n es una ventaja, no una limitación.
¿Cuánto tiempo llevó construir Jacobo?
Menos de un mes desde el diseño hasta producción. Y era mi primer agente IA, construido en paralelo a las demás responsabilidades del negocio. La velocidad se debe a que el Business OS ya existía: datos limpios y accesibles en Airtable, inventario en tiempo real, CRM con historial. Sin esa base de 5 años, habría sido mucho más lento. Jacobo fue la consecuencia inevitable de un sistema operativo de negocio robusto.
¿Puedes construir algo así para mi empresa?
Sí. Los patrones de Jacobo (sub-agentes, tool calling, HITL, cross-channel) son agnósticos de industria. Lo que cambia son los datos y las integraciones, no la arquitectura. Si tu negocio tiene datos estructurados y procesos repetitivos, puedo diseñar un sistema similar.
¿Jacobo sigue funcionando?
Sí. Vendí el negocio en 2025 y Jacobo se vendió con él. Sigue en producción atendiendo clientes hoy. Es la mejor validación posible: el comprador mantuvo el sistema porque funciona.
¿Cómo aplican estos patrones a un equipo enterprise?
Construí Jacobo en una PYME, pero los patrones (sub-agentes, tool calling, HITL, cross-channel) son enterprise-grade. A escala añades: circuit breakers, A/B testing por sub-agente, queue management para HITL, observabilidad por sub-agente. Lo que no cambia: la arquitectura.
Te han gustado los workflows. Imagina lo que puedo hacer con los tuyos.